开篇
前面已经讲了两种表示文本特征的向量化方法了,到这里也可以进入我们的词向量了,词向量是近几年来NLP领域最重要的研究成果之一,我们现在再看一些基本的NLP任务也基本上再也离不开词向量的身影,今天我们就用代码的层面来看看它到底是什么?ps:拖延症晚期,跳票严重。今天无论如何都要把词向量这篇博客补上。
word2vec
前面我们也讲到了两种向量化的方式,他们有个缺点就是太长了,都是以词典的大小来表示自己的,这就限制了我们词典的长度以避免相应的维度问题。比如说one-hot编码,如果词典长达10万,那么我们的词向量也就10万啦。这也太稀疏啦,而且每个词的表示是完全不一样的,不好计算相似度,这就很糟糕了。那我们现在使用的词向量是怎么得来呢。现在的词向量来源于上下文的语义,算是语言模型的副产品。这边我还是放上宏毅大佬的几张ppt以便大家的理解。
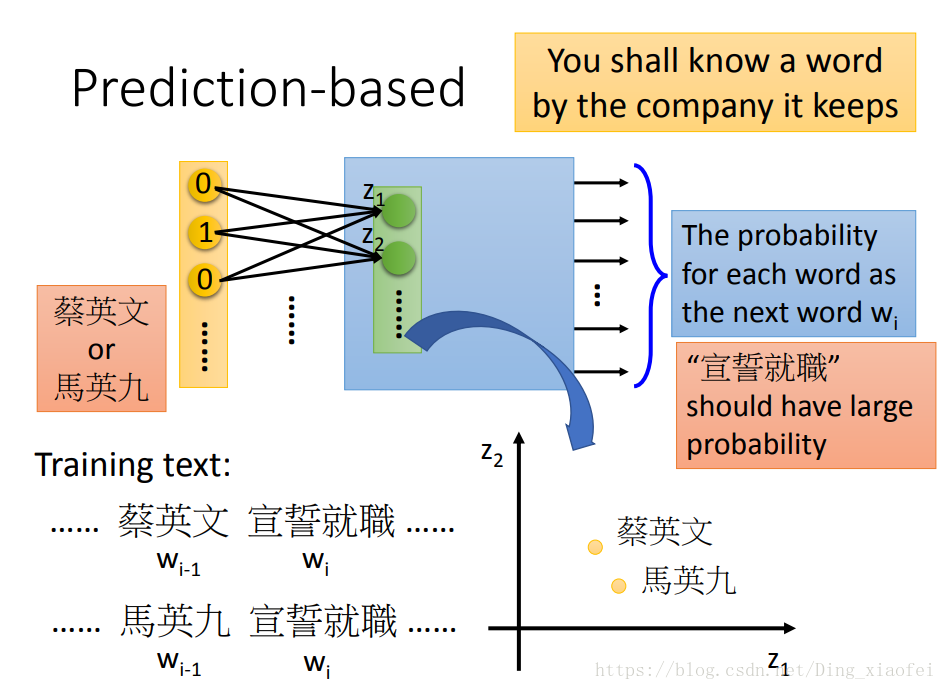
首先还是要讲一下神经网络语言模型,当然我们后面肯定会有语言模型的详细代码博客要写,什么是语言模型呢,说白了就是判断一句话是否符合逻辑,换句话说就是,现实生活中出现这句话的概率是多大,如果概率大,那么就判定这句话是符合逻辑了,是人话。神经网络语言模型训练好了,就是为了生成人话的,注意上面的图,我们输入那两个人的名字,期待他们输出的就是宣誓就职。如果是其他的话,那么就是有误差的,就要调整我们的参数。这就是典型的一个预测模型,而这个预测模型就是我们的语言模型的实现,当我们使用lstm这类循环神经网络的时候,我们就可以源源不断的生成我们想要的句子啦,只要给它一个初始值。Ok,到这里,你可能回想这和我们的词向量有什么关系,这当然有关系啦,我们的词向量根据上下文的词来生成,就是这种典型的语言模型,只不过采用的不是典型的n-gram,因为它不需要考虑文字的语序,上下文信息显得更加有效。
注意词向量的模型式三层的,只有一个隐藏层,而它的词向量也主要来源于它的隐藏层的参数矩阵,知乎上有一篇很好的回答,相信能够给大家很好的启发词向量。因为不是纯理论博客,有些东西点到为止,但是欢迎大家提问。如有错误,也希望大神能够指出,帮我改正。词向量算是入门nlp的坑啦,讲的好的博客比较少。希望我贴出的这篇回答能给大家带来启发。
代码
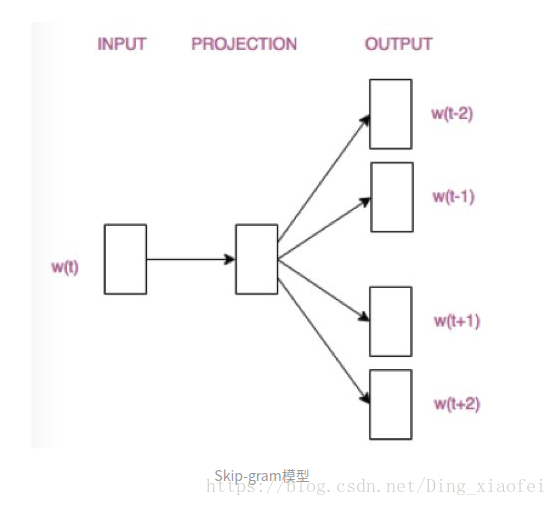
这边先讲数据预处理的代码,主要是数据的获取和词典的生成以及训练数据的生成,博主代码底子薄弱,所有这些预处理的代码都调过。还是要简单的描述一下我们代码的主要任务,词向量的代码不是你给个语料,它就给你生成词向量的代码,如果你是这样认为的,那么希望你能够好好阅读一下词向量的理论知识。我们整体任务还是预测任务,像今天我们要说的skip-gram就是入上图,给出一个中心词,预测它的上下文。词向量是语言模型的副产品,它是来源于中间隐藏层的权值矩阵的。希望我说的还算清楚,下面开始我们的预处理代码,为什么要讲预处理呢。因为我的底子差,希望能够积累这些琐碎的处理经验。
首先是数据的获取:
def load_movie_data():
save_folder_name = 'temp'
pos_file = os.path.join(save_folder_name, 'rt-polarity.pos')
neg_file = os.path.join(save_folder_name, 'rt-polarity.neg')
# Check if files are already downloaded
if os.path.exists(save_folder_name):
pos_data = []
with open(pos_file, 'r') as temp_pos_file:
for row in temp_pos_file:
pos_data.append(row)
neg_data = []
with open(neg_file, 'r') as temp_neg_file:
for row in temp_neg_file:
neg_data.append(row)
else: # If not downloaded, download and save
movie_data_url = '+++'
stream_data = urllib.request.urlopen(movie_data_url)
tmp = io.BytesIO()
while True:
s = stream_data.read(16384)
if not s:
break
tmp.write(s)
stream_data.close()
tmp.seek(0)
tar_file = tarfile.open(fileobj=tmp, mode="r:gz")
pos = tar_file.extractfile('rt-polaritydata/rt-polarity.pos')
neg = tar_file.extractfile('rt-polaritydata/rt-polarity.neg')
# Save pos/neg reviews
pos_data = []
for line in pos:
pos_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode())
neg_data = []
for line in neg:
neg_data.append(line.decode('ISO-8859-1').encode('ascii',errors='ignore').decode())
tar_file.close()
# Write to file
if not os.path.exists(save_folder_name):
os.makedirs(save_folder_name)
# Save files
with open(pos_file, "w") as pos_file_handler:
pos_file_handler.write(''.join(pos_data))
with open(neg_file, "w") as neg_file_handler:
neg_file_handler.write(''.join(neg_data))
texts = pos_data + neg_data
target = [1]*len(pos_data) + [0]*len(neg_data)
return(texts, target)
这边数据是情感分析的数据集,数据的下载使用代码去下载实现,但是不太好用,老是下载不下来,大家可以直接点击它给的链接,浏览器会直接下载到本地。主要下载下来的数据打开的时候可能会出现编码的问题,这时候大家可以在open函数里面加一个参数,encoding=’latin-1’,具体为什么要这么做,请大家参考我的博客python编码问题。其实这边的target用处不是很大,因为我们不做分类任务嘛,只要有文字内容就可以了。