因为计算机不能理解词语,所以我们需要用词向量表示一个词。
词向量有一个发展历程。
1 one-hot
2 bag of words
-
tf-idf
-
binary weighting
-
b-gram和n-gram
优点:考虑了词的顺序
缺点:词表膨胀,无法衡量向量之间的相似性
3 分布式表示 -
skip-gram
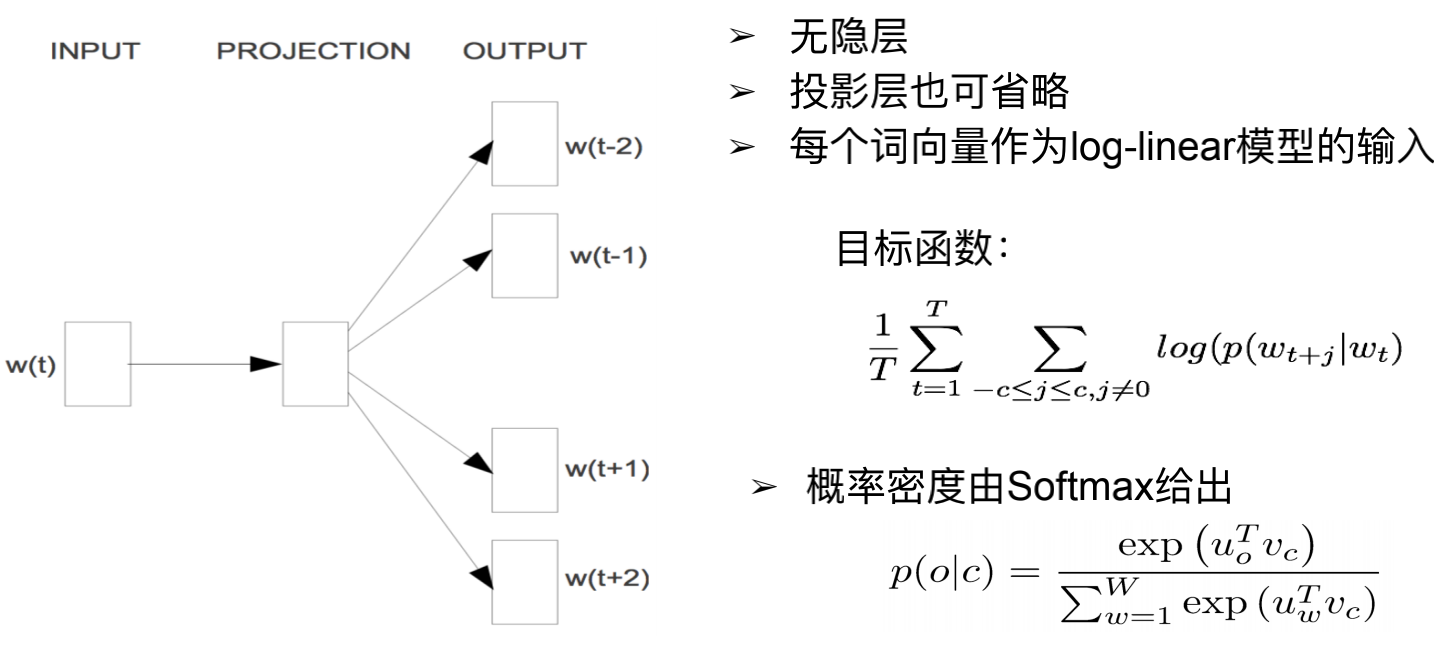
输入第t个词,用一层的神经网络,预测周围的词,也就是第t-2个,t-1个,t+1个,t+2个…。
这个任务本身没有意义,做这件事情的意义是拿到词向量。拿到词向量可以用于查找一个词的邻近词,做词类比的任务,用于命名实体识别等。
其原理就是:一个单词可以用附近的单词来表示这个单词。
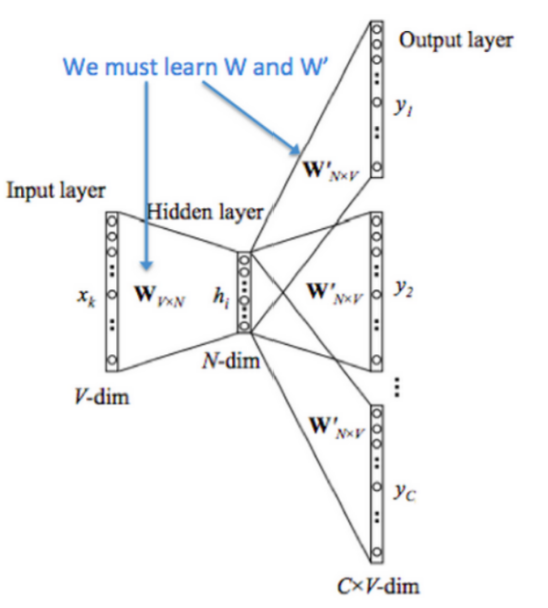
整体训练网络如上图。词表大小为N。
输入X是一个one-hot的表示形式。其形状是NxN。
第一层是一个线性变换 h= XxW (W是一个Nx100的一个矩阵),得到一个Nx100维的隐层矩阵。
最后在隐层上加一个线性变换: hxW’ 得到输出是这里(X周围的一个位置)应该是某个词的概率。W’是一个Nx100的矩阵。
对下游有用的是W,用做词向量表示。一般把W称作输入向量,W’称作输出向量。
(这里看到模型维度对不上,不能做举证乘法,可能有一个转置操作。)
目标函数:找到在给定 w t w_t wt的情况下 w t + j w_{t+j} wt+j出现的概率: p ( w t + j ∣ w t ) p(w_{t+j}|w_t) p(wt+j∣wt),再对这个概率取log。对所有窗口范围内的概率log和取最大值。t是从1到T的,再对这所有和,取和。
具体概率的计算方式是 u o u_o uo是输出的词向量, v c v_c vc是输入词向量。
p ( o ∣ c ) = e x p ( u o T v c ) ∑ w = 1 W e x p ( u w T v c ) p(o|c)=\dfrac{exp(u_o^Tv_c)}{\sum_{w=1}^W exp(u_w^Tv_c)} p(o∣c)=∑w=1Wexp(uwTvc)exp(uoTvc)
损失函数:
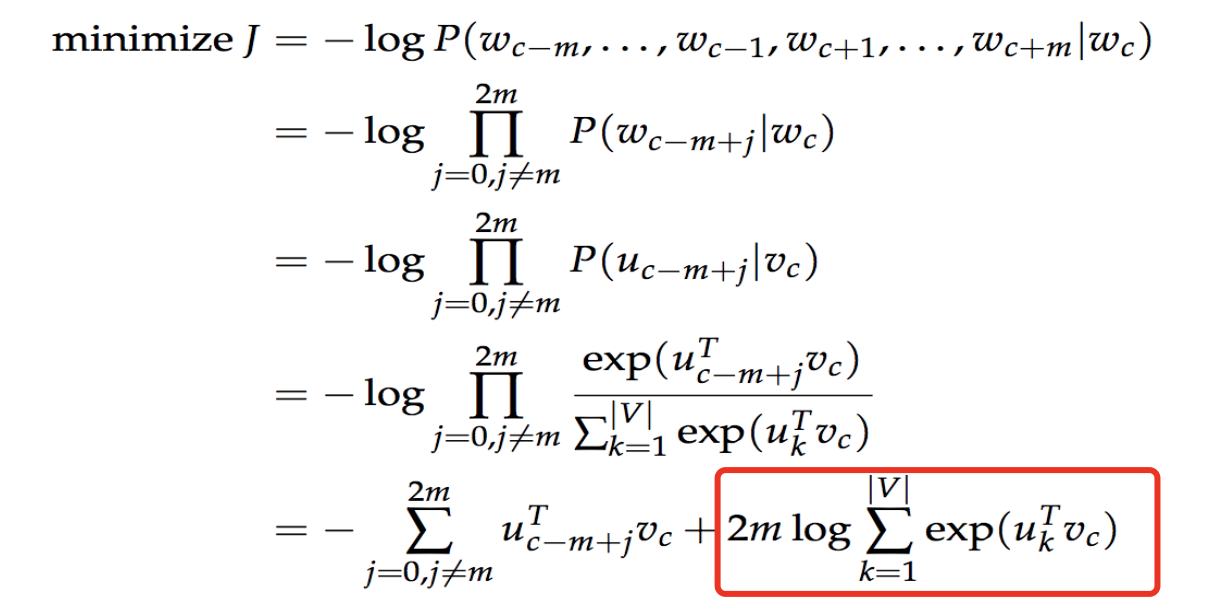
这里最大的问题是p(o|c)的分母是很大的。要计算 v c v_c vc与词库中每一个单词的词向量的和。如果词库有50万个单词,那就要计算50万次。计算量很大。看损失函数的最后一项,也是一样的。
采取的措施有一种是负例采样。
我们的输入input embeding是一个50万x100维的矩阵。(假设我们用100维的向量表示一个词)。输出output embedding是一个50万x100维的矩阵。
我们把任务换一个角度。对于 w t w_t wt不要计算周围单词在整个词库上的概率。我们将词库的单词分为周围单词和非周围单词两类。这样就把一个50万分类问题变为2分类问题。如果单词 u k u_k uk是 w t w_t wt的周围单词,那就概率高一些。否则概率低一些。
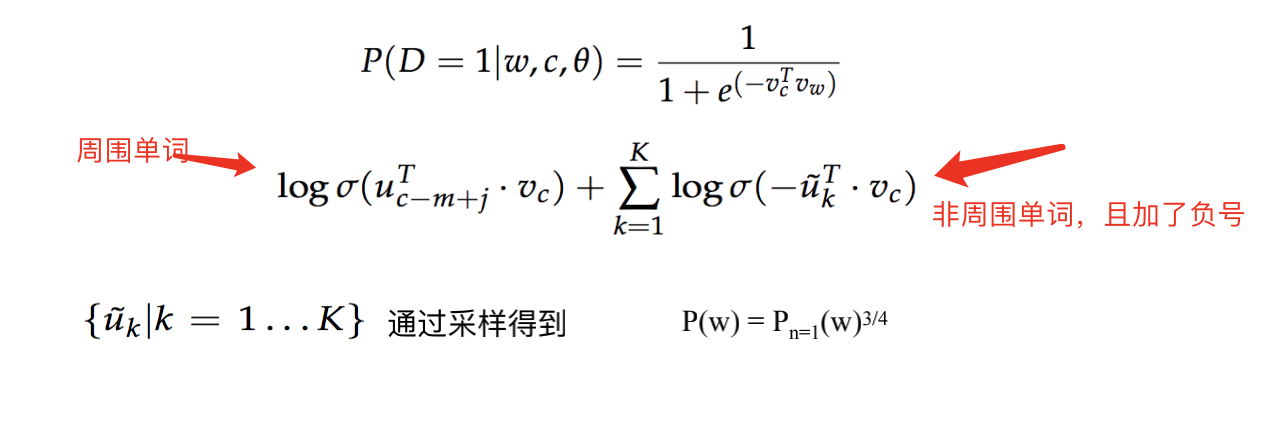
我们希望目标函数越大越好。
对于负利我们从词库中采样一部分单词即可。采样后的概率做了一下变换才参与到计算中。
最后对我们有用的数据是输入的embedding,这是词的稠密向量。可以很好的表示词之间的相关性。
最后模型代码实现。