谭东旭 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
汇编小知识
在用高级语言如C语言编程时,我们被屏蔽了程序的具体的机器实现。相比之下,在用汇编代码编写程序时候,程序员必须明确指定程序该如何管理存储器和用来执行计算的低级指令。我想作为一个严谨的程序员来说,要想了解程序的运行效率以及更好地提高程序效率,我认为能够阅读和理解汇编代码仍是一项很重要的技能。
我们知道汇编格式有两种:AT&T汇编格式与Intel汇编格式。linux GCC采用的是AT&T的汇编格式, 而微软采用Intel的汇编格式。下面我们就稍微介绍一下他们的一些不同之处:
| 格式 | 寄存器命名 | 源/目的操作数顺序 | 常数/立即数的格式 |
|---|---|---|---|
| AT&T | %eax | movl %eax, %ebx | movl $_value,%ebx |
| Intel | eax | mov ebx, eax | mov eax,_value |
| 说明 | Intel的不带百分号 | AT&T目的操作数在后,源操作数在前 | Intel立即数前面不带$符号 |
还有一点不同的是,在AT&T的格式中, 每个操作符都有一个字符后缀,例如 movl 传送双字(32位),movw 传送字(16位),movb 传送字节(8位)。因为在许多机器上, 32位数都称为长字(long word), 这是沿用以16位字为标准的时代的历史习惯造成的.
下面我们也给出一些常见的汇编指令的含义:
| 指令 | 含义 | 说明 |
|---|---|---|
| movl %eax,%edx | edx=eax | 寄存器寻址 |
| movl $0x123,%edx | edx=0x123 | 立即寻址 |
| movl 0x123,%edx | edx=*(int32_t*)0x123 | 直接寻址 |
| movl (%ebx),%edx | edx=*(int32_t*)ebx | 间接寻址 |
| movl 4(%ebx),%edx | edx=*(int32_t*)(ebx+4) | 变址寻址 |
汇编代码的工作过程中堆栈的变化
下面给出示例代码:
#include<stdio.h>
int g(int x)
{
return x + 2;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(7) + 5;
}上述是很简单的一个小程序,我的实验环境为实验楼所提供的虚拟机环境,使用命令gcc –S –o main.s main.c -m32生成汇编代码,注意该命令是在实验楼64位Linux虚拟机环境下适用,32位Linux环境可能会稍有不同。所得到的汇编代码如下:
g:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
addl $2, %eax
popl %ebp
ret
f:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl 8(%ebp), %eax
movl %eax, (%esp)
call g
leave
ret
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $7, (%esp)
call f
addl $5, %eax
leave
ret
有了汇编代码,但是我们不一定能看得懂,我们知道main中调用了函数f,f中调用了g,但是函数返回时为什么能返回到正确的位置?其实这个过程中用栈来保存参数及返回地址,函数返回时再从栈中取出保存的地址,这样就不影响主程序的继续执行。下面我就给出其中一些汇编指令的等价指令,让我们更能轻易理解这一代段汇编代码。
| 指令 | what it does |
|---|---|
| pushl %eax | subl $4,%esp ; movl %eax,(%esp) |
| popl %eax | movl (%esp),%eax ; addl $4,%esp |
| call 0x12345 | pushl %eip ; movl $0x12345,%eip |
| ret | popl %eip |
| enter | pushl %ebp ; movl %esp,%ebp |
| leave | movl %ebp,%esp ; popl %ebp |
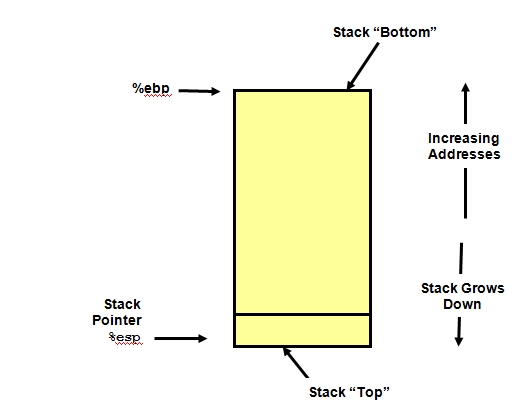
好了,有了上面的一些解释,我们就可以一步一步对代码进行分析。首先下面我先看看栈在计算中是如何操作变化的,ebp为栈的基址寄存器,esp为栈顶指针,栈是向低地址方向增长的。
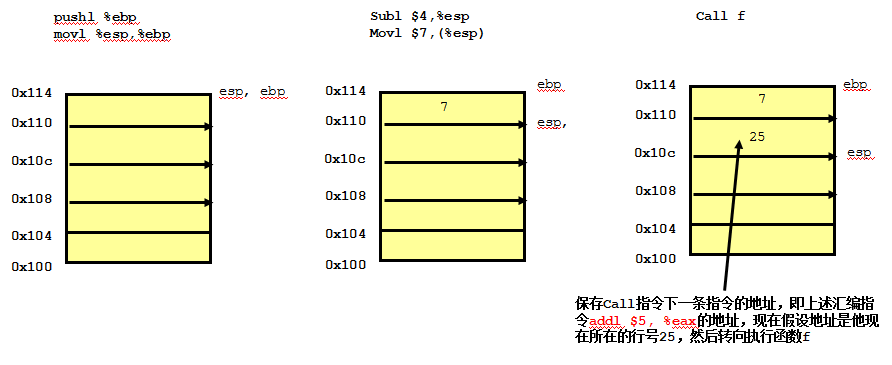
我们回到汇编代码,看到在每个汇编代码块的开始都有两句一样的汇编指令:
pushl %ebp
movl %esp, %ebp
- 1
- 2
其实这两句可以理解是保存上一个函数的栈底指针,然后从新开始一个新的栈。现在从main函数开始我们就以图的形式来描述汇编在栈中的变化(在这里我们假设栈的起始地址为0x114)。
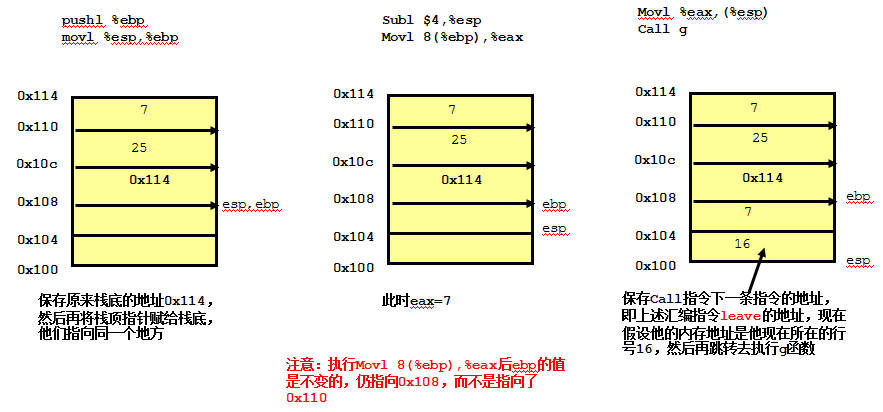
当mian函数运行到call指令时候,就跳转到了f函数的代码块,现在下图给出了f代码块的栈变化过程。
当f函数运行到call指令时候,就跳转到了g函数的代码块,下图给出了g代码块的栈变化过程。
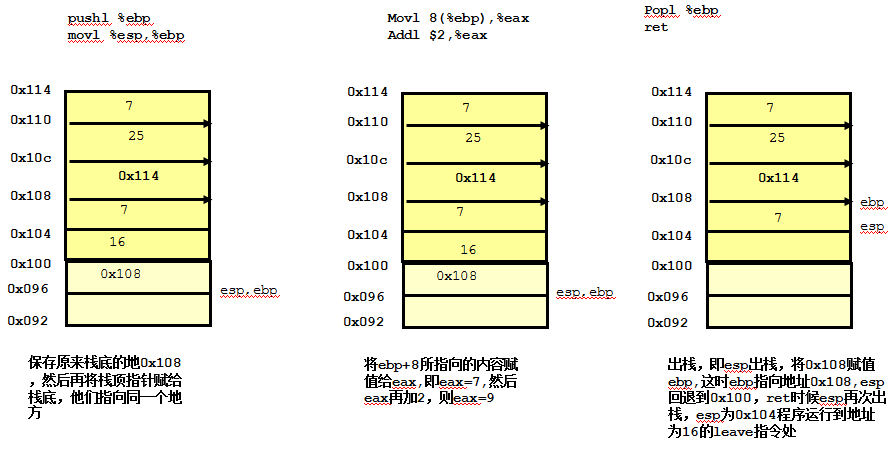
上述g函数代码块已经执行完毕,即f函数call执行完毕,计算机接着出栈16,运行到f函数中call的下一条指令即leave指令,leav指令在上面已经给出解释。leave指令后ebp指向0x114,esp指向0x10c,接着运行g函数ret,esp执行出栈,回到了main函数的call的下一条指令,即addl $5, %eax,此时eax=eax+5,最终eax=14.最后两条指令用法和上边的一样。esp和ebp回到初态,最后整个程序通过eax返回。
总结
总的来说计算机的运行就是存储器和cpu之间不停的取指令和运行指令的过程,准确的理解汇编代码的含义,对程序员来说能更好的深入理解计算机是如何工作的,编写代码过程中才能透过高级语言的现象看到计算机的机器语言的本质。