1 Yarn的MapReduce工作流程
经典的MapReduce顶层包括5个独立实体
- 客户端,提交MapReduce作业
- YARN资源管理器,协调集群上计算资源分配
- YARN节点管理器,负责启动和监视集群中的container
- MapReduce应用程序master,协调运行中的作业任务
- 分布式文件系统(一般为HDFS),与其他实体间共享作业文件
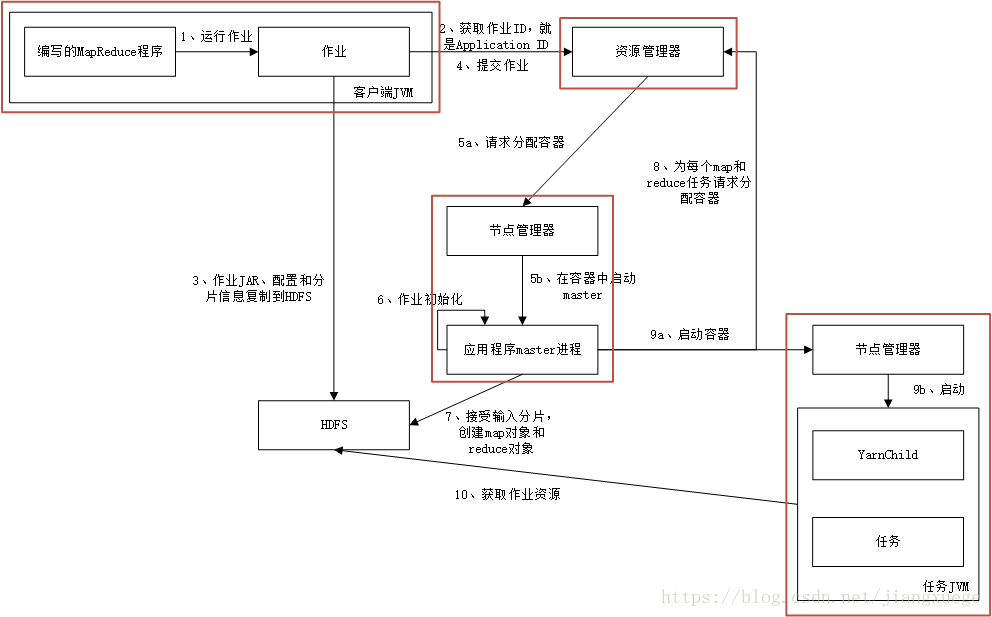
提交作业的步骤,一张图就可以了,照着书上画的,加了一些解释,红色框表示节点
第7个步骤之后,如果该任务很小,master则会决定在当前节点运行这个任务,称为uber任务
任务会向master进程汇报当前任务进程,而客户端会以给定时间间隔从master查询作业状态
2 Yarn失败
Yarn中的失败包括:
- 任务运行失败
- master
- 节点管理器
- 资源管理器
2.1 任务运行失败
master进程会注意到任务失败并尝试再次启动任务,最大尝试次数由mapreduce.map.maxattemps设定。如果作业失败次数超过mapreduce.map.failures.maxpercent或者mapreduce.reduce.failures.maxpercent,就判定作业失败
2.2 master运行失败
yarn.resourcemanager.am.max-retries设置允许master失败的次数,默认为1次
master向资源管理器发送心跳,master失败后资源管理器在一个新容器总启动master。如果设置了yarn.app.mapreduce.am.job.recovery.enable为true,master可以恢复之前运行的任务状态
客户端会缓存master的地址,如果请求超时会向资源管理器请求新的master地址
2.3 节点管理器运行失败
节点管理器也会向资源管理器发送心跳,yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms决定资源管理器认为节点管理器失败的等待时间
如果应用程序的运行失败次数过高,节点管理器可能被master拉黑,mapreduce.job.maxtaskfailures.per.tracker设置拉黑阈值
2.4 资源管理器运行失败
那就歇菜了(大误)
管理员启动一个新的资源管理器,并恢复保存的状态,资源管理器只保存节点管理器和master,任务由master管理,这样有助于降低资源管理器的压力