越来越觉的各种安装都应该谨遵官网,不要自己上网看到一篇教程就不经大脑地敲到命令行里,非常冒险,而且往往要走很多弯路。接下来我直接粘贴官网地址:
一、Installing NVIDIA Graphics Drivers[安装显卡驱动]
https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html#installdriver
二、NVIDIA CUDA Installation Guide for Linux[安装CUDA]
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
因为涉及到多版本的TensorFlow的安装,所以有不同的cuda和cudnn的要求,也是多版本共存的
所以安装完cuda之后,要记得改变不同的环境变量。
一般cuda默认会创建一个软链接 /usr/local/cuda ->/usr/local/cuda-x.x
我们在设置环境变量的时候,要以原始的/usr/local/cuda-x.x 为准
最后记得:在 ~/.profile中加上:

The PATH variable needs to include /usr/local/cuda-9.1/bin
To add this path to the PATH variable:
$ export PATH=/usr/local/cuda-9.1/bin${PATH:+:${PATH}}
In addition, when using the runfile installation method, the LD_LIBRARY_PATH variable needs to contain /usr/local/cuda-9.1/lib64 on a 64-bit system, or /usr/local/cuda-9.1/lib on a 32-bit system
To change the environment variables for 64-bit operating systems:
$ export LD_LIBRARY_PATH=/usr/local/cuda-9.1/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
To change the environment variables for 32-bit operating systems:
$ export LD_LIBRARY_PATH=/usr/local/cuda-9.1/lib\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Note that the above paths change when using a custom install path with the runfile installation method.
三、Installing cuDNN on Linux[安装cudnn]
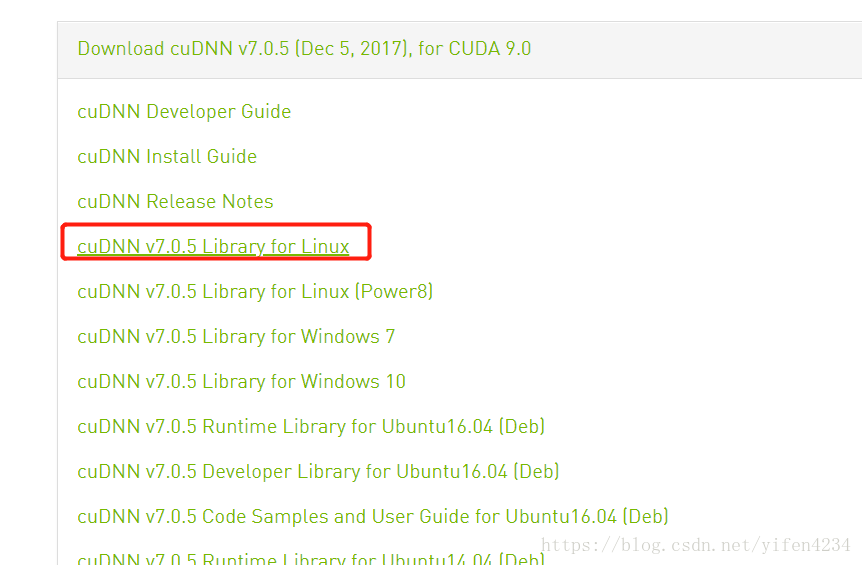
The following steps describe how to build a cuDNN dependent program. Choose the installation method that meets your environment needs. For example, the tar file installation applies to all Linux platforms. The debian installation package applies to Ubuntu 14.04 and 16.04.
2.3.1. Installing from a Tar File
- Navigate to your <cudnnpath> directory containing the cuDNN Tar file.
- Unzip the cuDNN package.
$ tar -xzvf cudnn-9.0-linux-x64-v7.tgz
- Copy the following files into the CUDA Toolkit directory.
$ sudo cp cuda/include/cudnn.h /usr/local/cuda-x.x/include
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda-x.x/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda-x.x/lib64/libcudnn*
都要注意的是,都是放在 /usr/local/cuda-x.x 这个特定的对应cuda文件夹中的
从而实现了多版本共存~
四、安装TensorFlow(我是用的virtualenv方式安装的,可以实现多版本tf共存~)
https://www.tensorflow.org/install/install_linux#InstallingVirtualenv
1、 要注意前面的cuda、cudnn等依赖的要求
2、这句话执行可能会出现问题说找不到之类,用deb其实一般是默认安装了不用再安装,如果没有的话就tab一下,会出现对应的cuda版本,找自己要的版本就可以了~
sudo apt-get install cuda-command-line-tools
3、我的服务器virtualenv默认是python3,但是我的脚本是python2,所以需要特定指定python为2版本
virtualenv --python=/usr/bin/python2.7 --system-site-packages <path/to/new/virtualenv/>4、遇到whl在服务器中无法下载的问题,问题还没有排查出来,我是在本机下载whl文件,然后上传到服务器
这时直接用 pip install xxx.whl即可。
-------------------------------------------------------------------------------------------------------------------------
曾经的笔记【再次声明,这应该是16年的笔记了,所以很多东西现在不一定靠谱,安装真的看官网有用!有问题找google、group和forum】
1. 安装Ubuntu16.04
不考虑双系统,直接安装 Ubuntu16.04,从ubuntu官方下载64位版本: ubuntu-16.04-desktop-amd64.iso 。
1)制作了 Ubuntu USB 安装盘,具体方法可参考: 在MAC下使用ISO制作Linux的安装USB盘,之后通过Bios引导U盘启动安装Ubuntu系统。
2)安装SSH Server,这样可以远程ssh访问这台GTX1080主机:
sudo apt-get install openssh-server(动态ip改变时推送邮件【自动给邮箱发送邮件提示ip改变】ssh 如何登录 ip 会变的电脑)
3)更新Ubuntu16.04源,用的是中科大的源:
sudo cp sources.list sources.list.bak
把下面的这些源添加到source.list文件头部:【曾经的现在不一定能用,optional】
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
sudo apt-get upgrade(更新安装包)【这个不要轻易做,是用于更新系统所有的软件包!】
2. 安装GTX1080驱动(这是之前的笔记现在不一定可用)
sudo add-apt-repository ppa:graphics-drivers/ppa
Fresh drivers from upstream, currently shipping Nvidia.
We currently recommend: `nvidia-361`, Nvidia's current long lived branch.
For GeForce 8 and 9 series GPUs use `nvidia-340`
For GeForce 6 and 7 series GPUs use `nvidia-304`
## What we're working on right now:
- Investigating how to bring this goodness to distro on a cadence.
This PPA is currently in testing, you should be experienced with packaging before you dive in here. Give us a few days to sort out the kinks.
Volunteers welcome! See also: https://github.com/mamarley/nvidia-graphics-drivers/
http://www.ubuntu.com/download/desktop/contribute
更多信息: https://launchpad.net/~graphics-drivers/+archive/ubuntu/ppa
sudo apt-get install nvidia-367(我安装的是NVIDIA-375)
sudo apt-get install mesa-common-dev
sudo apt-get install freeglut3-dev
之后重启系统让GTX1080显卡驱动生效。
3. 下载和安装CUDA
首先应该搞清楚各个东西的关系,CUDA和GPU之间的关系 - wonengguwozai的博客 - 博客频道 - CSDN.NET 而gpu作为硬件他的使用是需要驱动对应NVIDIA*.run(现在是375版本(这个要到官网上匹配http://www.nvidia.cn/Download/index.aspx?lang=cn 先提前下好吧,要是循环登录了用这个重装 )),这个装了驱动以后我们再装cuda(计算平台)的时候首先会有driver的选项,一定选择不要覆盖!!!否则就白装了,也可能导致最后循环登录的问题,切记!(如果装了的话重装驱动就可以啦!)
先看看这个:http://blog.csdn.net/abcjennifer/article/details/23016583 【百度大神!】Ubuntu12.04配置NVIDIA cuda5.5经验帖 - Rachel Zhang的专栏 - 博客频道 - CSDN.net
在安装CUDA之前,google了一下,发现在Ubuntu16.04下安装CUDA7.5问题多多,幸好CUDA8已出,支持GTX1080:
Out of box performance improvements on Tesla P100, supports GeForce GTX 1080
Simplify programming using Unified memory on Pascal including support for large datasets, concurrent data access and atomics*
Optimize Unified Memory performance using new data migration APIs*
Faster Deep Learning using optimized cuBLAS routines for native FP16 computation
Quickly identify latent system-level bottlenecks using the new critical path analysis feature
Improve productivity with up to 2x faster NVCC compilation speed
Tune OpenACC applications and overall host code using new profiling extensions
Accelerate graph analytics algorithms with nvGRAPH
New cuBLAS matrix multiply optimizations for matrices with sizes smaller than 512 and for batched operation
不过下载CUDA需要注册和登陆NVIDIA开发者账号,https://developer.nvidia.com/cuda-downloads提供了很详细的系统选择和安装说明,
这里选择了Ubuntu16.04系统runfile安装方案,千万不要选择deb方案,前方无数坑:
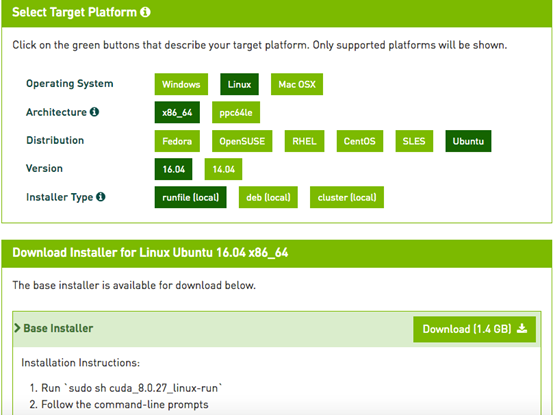
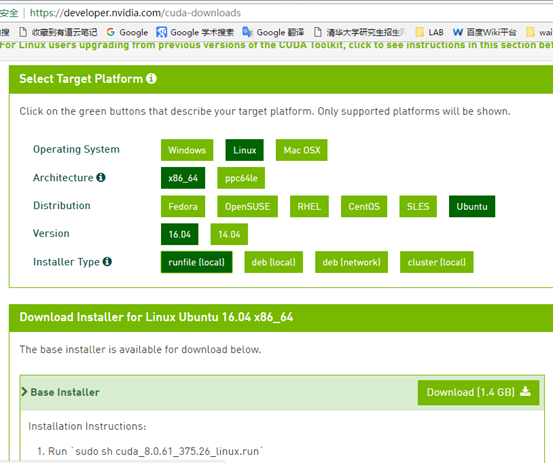
下载的"cuda_8.0.27_linux.run"有1.4G,按照Nivdia官方给出的方法安装CUDA8:
重启后,在登陆界面时同时按下:Ctrl + Alt + F1~F6进入字符界面。 (即tty1~6)
sudo service lightdm stop (其中lightdm根据自己使用的桌面做相应的调整: [KDM(KDE),GDM(GNOME) )
chmod +x cuda_8.0.27_linux.run (变成可执行文件)
sudo sh cuda_8.0.27_linux.run --tmpdir=/opt/temp/
这里加了--tmpdir主要是直接运行"sudo sh cuda_8.0.27_linux.run"会提示空间不足的错误,其实是全新的电脑主机,硬盘足够大的,google了以下发现加个tmpdir就可以了:
Not enough space on parition mounted at /.
Disk space check has failed. Installation cannot continue.
执行后会有一系列提示让你确认,非常非常非常非常关键的地方是是否安装361这个低版本的驱动:
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 361.62?
答案必须是n,否则之前安装的GTX1080驱动就白费了,而且问题多多。
Logging to /opt/temp//cuda_install_6583.log
The following contains specific license terms and conditions
for four separate NVIDIA products. By accepting this
agreement, you agree to comply with all the terms and
conditions applicable to the specific product(s) included
Do you accept the previously read EULA?
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 361.62?
(y)es/(n)o/(q)uit: n (对!这里一定要no不要再重装驱动了!!!)(如果选了yes后面就会有个x-config这里就可能更改了原来intel集显的设置,导致进不去系统桌面,因为intel是我们安装ubuntu默认的显卡,我们只是要利用nvidia的gpu的计算能力,所以不用改变原来的显卡设置!)
[ default is /usr/local/cuda-8.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
[ default is /home/textminer ]:
Installing the CUDA Toolkit in /usr/local/cuda-8.0 ...
Installing the CUDA Samples in /home/textminer ...
Copying samples to /home/textminer/NVIDIA_CUDA-8.0_Samples now...
Toolkit: Installed in /usr/local/cuda-8.0
Samples: Installed in /home/textminer
- PATH includes /usr/local/cuda-8.0/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-8.0/lib64, or, add /usr/local/cuda-8.0/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-8.0/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-8.0/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 361.00 is required for CUDA 8.0 functionality to work.
To install the driver using this installer, run the following command, replacing with the name of this run file:
Logfile is /opt/temp//cuda_install_6583.log
安装完毕后,再声明一下环境变量,并将其写入到 ~/.bashrc 的尾部:
export PATH=/usr/local/cuda-8.0/bin\:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-8.0/bin\${PATH:+:\${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\${LD_LIBRARY_PATH:+:\${LD_LIBRARY_PATH}}
也可以看百度大神的博客【百度大神!】Ubuntu12.04配置NVIDIA cuda5.5经验帖 - Rachel Zhang的专栏 - 博客频道 - CSDN.net
nvidia-smi (To check which driver mode is in use and/or to switch driver modes, use the nvidia-smi tool that is included with the NVIDIA Driver installation (see nvidia-smi -h for details).)
nvcc -V (The version of the CUDA Toolkit can be checked by running nvcc -V in a Command Prompt window. You can display a Command Prompt window by going to:)
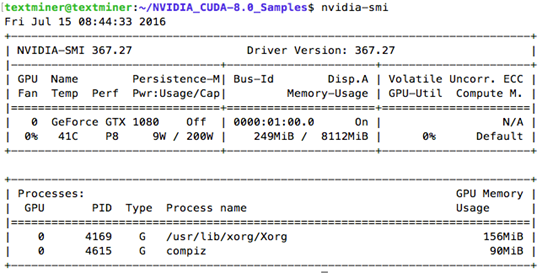
我是在NVIDIA的sample目录下直接make做了全局的检查,
找了so文件,如果没有创建链接就创建(ln -s nvcu*.so.0 nvcu*.so.375 之类的,一搜就有,这个是平常)
还有问题是明明有文件也创建链接了,但是还说找不到文件,这个是版本问题了
解决方式:ubuntu 14.04 - CUDA 7.0 Error while compiling samples - Stack Overflow
这里如果提示gcc版本过高,可以安装低版本的gcc并做软连接替换,具体方法请自行google,我用低版本的gcc4.9替换了ubuntu16.04自带的gcc5.x版本。
"/usr/local/cuda-8.0"/bin/nvcc -ccbin g++ -I../../common/inc -m64 -gencode arch=compute_20,code=sm_20 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_60,code=compute_60 -o deviceQuery.o -c deviceQuery.cpp
"/usr/local/cuda-8.0"/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_20,code=sm_20 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_60,code=compute_60 -o deviceQuery deviceQuery.o
mkdir -p ../../bin/x86_64/linux/release
cp deviceQuery ../../bin/x86_64/linux/release
执行 ./deviceQuery ,得到:(这里可能没有信息,sudo一下,如果有就是权限问题,我在自己用户目录下又安装了一遍,测试成功了)
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 8112 MBytes (8506179584 bytes)
(20) Multiprocessors, (128) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1835 MHz (1.84 GHz)
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = GeForce GTX 1080
./nbody -benchmark -numbodies=256000 -device=0
> Simulation data stored in video memory
> Single precision floating point simulation
> 1 Devices used for simulation
gpuDeviceInit() CUDA Device [0]: "GeForce GTX 1080
> Compute 6.1 CUDA device: [GeForce GTX 1080]
256000 bodies, total time for 10 iterations: 2291.469 ms
= 286.000 billion interactions per second
= 5719.998 single-precision GFLOP/s at 20 flops per interaction
Nvidia GTX 1080 on Ubuntu 16.04 for Deep Learning
Ubuntu 16.04下安装Tensorflow(GPU)
Ubuntu16.04+matlab2014a+anaconda2+OpenCV3.1+caffe安装
ubuntu 16.04 编译opencv3.1,opencv多版本切换
TensorFlow, Caffe, Chainer と Deep Learning大御所を一気に source code build で GPU向けに setupしてみた
feature request: support for cuda 8.0 rc
GTX 1080 CUDA performance on Linux (Ubuntu 16.04) preliminary results (nbody and NAMD)
Anyone able to run Tensorflow with 1070/1080 on Ubuntu 16.04/15.10/15.04?
Tensorflow on Ubuntu 16.04 with Nvidia GTX 1080
注:原创文章,转载请注明出处及保留链接"我爱自然语言处理":http://www.52nlp.cn
本文链接地址:深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0http://www.52nlp.cn/?p=9226
- 深度学习主机环境配置: Ubuntu16.04+GeForce GTX 1080+TensorFlow
- 深度学习主机攒机小记
- Mecab安装过程中的一些坑
- Ubuntu 64位系统下SRILM的配置详解
- Ubuntu8.10下moses测试平台搭建全记录
- 安装Srilm的一点新变化
- 翻译记忆产品小结
- Moses的一些新变化
- 斯坦福大学深度学习与自然语言处理第三讲:高级的词向量表示
- 基于哈希表和二叉树的词典研究(一)
-----------------------------------------------------------------------------
而我在安装过程中选择了重装驱动,这个驱动和我在官网上选择的不匹配,当然有问题,不过也可能是因为那个x-config选项我也选择了yes,这个涉及到了双显卡的问题,所以我这样貌似修改了默认显卡,导致了问题
解决方案:https://devtalk.nvidia.com/default/topic/996318/ubuntu-16-04-stuck-in-login-loop-after-attempting-to-install-nvidia-linux-x86_64-375-39-run/
I was able to resolve my issue by performing the following steps:
1. First reinstall the nvidia-375 repository graphic driver.
sudo apt-get install nvidia-375
During the installation, I noticed that nvidia-375.26 driver was being installed.
2. I moved the entire /lib/modules/4.4.0-64-generic/updates/dkms folder to my home directory backup folder. This was to make sure all old .ko files were removed.
cp -R /lib/modules/4.4.0-64-generic/updates/dkms ~/backup
3. I regenerated the .ko files for the installed driver using
sudo dpkg-reconfigure nvidia-375
dpkg-reconfigure命令是Debian Linux中重新配置已经安装过的软件包,可以将一个或者多个已安装的软件包传递给此指令,它将询问软件初次安装后的配置问题。
当用户需要再次对软件包配置的时候,可以使用dpkg-reconfigure命令来对指定的软件包进行配置。
来自: http://man.linuxde.net/dpkg-reconfigure)
It created a new dkms folder with the relevant nvidia kernel modules. I also checked their version using command:
sudo modinfo nvidia_375_drm.ko
sudo modinfo nvidia_375_modeset.ko
sudo modinfo nvidia_375_uvm.ko
Their output showed that they were for version 375.26.
Adapted from https://devtalk.nvidia.com/default/topic/525877/linux/api-mismatch-means-ubuntu-can-39-t-boot-i-can-39-t-fix-i-please-help-/1
-----------------------------------------------------------------------------------------
http://blog.csdn.net/triloo/article/details/52767412(bumblebee 工具)
http://blog.csdn.net/TriLoo/article/details/52678033?locationNum=14
-----------------------------------------------------------------------
.xsession-errors:openConnection: connect: No such file or directory cannot connect to brltty at :0
学会看日志啊,其实说的很明白,实在不懂可以拿着日志去找论坛,一定要翻墙!!
-------------------------------------------------------------------------
caffe安装系列——安装cuda和cudnn - 张学志の博客 - 博客频道 - CSDN.NET
http://blog.csdn.net/xuezhisdc/article/details/48651003
https://developer.nvidia.com/cudnn
The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN is part of the NVIDIA Deep Learning SDK.
Deep learning researchers and framework developers worldwide rely on cuDNN for high-performance GPU acceleration. It allows them to focus on training neural networks and developing software applications rather than spending time on low-level GPU performance tuning. cuDNN accelerates widely used deep learning frameworks, including Caffe, TensorFlow, Theano, Torch, and CNTK. See supported frameworks for more details. cuDNN is freely available to members of the Accelerated Computing Developer Program
NVIDIACUDA®深层神经网络库(cuDNN)是一种用于深层神经网络的GPU加速库原始图形。cuDNN为标准例程提供了高度调优的实现,如前向和后向卷积,池化,归一化和激活层。cuDNN是NVIDIA深度学习SDK的一部分。
全球深入学习的研究人员和框架开发人员依靠cuDNN来实现高性能GPU加速。它允许他们专注于训练神经网络和开发软件应用程序,而不是花时间在低级GPU性能调优。cuDNN加速了广泛使用的深度学习框架,包括Caffe,TensorFlow,Theano,Torch和CNTK。有关详细信息,请参阅支持的框架。加速计算开发者计划的成员免费提供cuDNN