一、索引
索引是一种快速访问数据的途径,可提高数据库性能。索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需的数据,就像书的目录,可以快速查找所需的信息,无须阅读整本书。
(一)索引的分类
逻辑分类:单列索引、组合索引、唯一索引、非唯一索引,函数索引。
物理分类:区分索引、非分区索引、B树索引、正向索引、反向索引,位图索引。
(二)索引的缺点:
1、索引占用表空间,创建太多索引可能会造成索引冗余。
2、索引会影响INSERT、UPDATE、DELETE语句的性能。
(三)使用索引的原则:
1、装载数据后再建立索引。
2、频繁搜索的列可以作为索引。
3、在联接属性上建立索引(主外键)。
4、经常排序分组的列。
5、删除不经常使用的索引。
6、指定索引块的参数,如果将来会在表上执行大量的insert操作,建立索引时设定较大的ptcfree。
7、指定索引所在的表空间,将表和索引放在不同的表空间上可以提高性能。
8、对大型索引,考试使用NOLOGGING子句创建大型索引。
不要在下面的列创建索引:
1、仅包含几个不同值得列。
2、表中仅包含几条记录。
二、索引的使用:
(一)创建索引
语法:
CREATE [UNIQUE] INDEX index_name ON table_name(column_list)
[TABLESPACE tablespace_name]
说明:
unique:指定索引列中值必须是唯一的
index_name:索引名
table_name:指定要建立索引的表
col_name:要建立索引的列,可以是多列,那样的索引叫多列索引
table_space_name:索引存储的表空间
实例1:
如果我们经常对emp表进行按照empno来查询某个员工的信息,
SQL> select * from emp where empno=7788;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
我们就应该对empno这一列建一个索引。
create index indx_on_empno
on emp(empno)
tablespace users;实例2:
如果我们经常查询某个部门工资大于1000的员工信息,
那么我们就可以在job和sal列上建立所以,这叫组合索引:
SQL> select * from emp
2 where job='SALESMAN' and sal>1000;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
----- ---------- --------- ----- ----------- --------- --------- ------
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
create index indx_on_job_sal
on emp(job,sal)
tablespace users;实例3:
我们还可以创建基于函数的索引,不过在此前,我们必须设置一下初始化参数:
conn system/chage_on_install as sysdba;
alter system set query_rewrite_enabled=true;
create index indx_lower_job
on emp(lower(job))
tablespace users;(二)修改索引
就像修改表一样,我们在创建索引后可以进行修改
实例1:分配和释放索引空间
alter index indx_on_empno
allocate extent(size 1m);
实例2:释放多余的索引空间
alter index indx_on_empno
deallocate unused;
实例3:重建索引
alter index indx_on_job_sal rebuild;
实例4:联机重建索引,
使用rebuild,若其他用户正在表上执行dml操作,重建会失败,
使用如下语句,就可以成功重建
alter index indx_on_job_sal rebuild online;
实例5:合并索引
当相邻索引块存在剩余空间,通过合并索引将其合并到一个索引块上
alter index indx_on_job_sal coalesce;
实例6:重命名索引
alter index indx_on_job_sal rename to indx_on_jobandsal;(三)删除索引
如果索引不再需要了,留在数据库中将会占用资源,我们可以将其删除
drop index indx_on_job_sal;(四)查看索引
我们可以从unser_indexes视图中查看有关某表的索引信息,
下面我先来看看unser_indexes视图的信息:
SQL> desc user_indexes;每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。
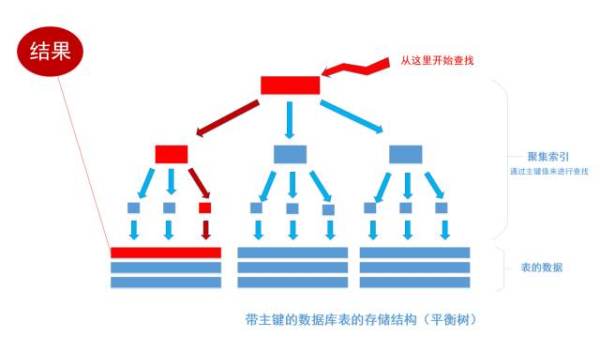
聚集索引
其中树的所有结点(底部除外)的数据都是由主键字段中的数据构成,也就是通常我们指定主键的id字段。最下面部分是真正表中的数据。 假如我们执行一个SQL语句:
select * from table where id = 1256;
首先根据索引定位到1256这个值所在的叶结点,然后再通过叶结点取到id等于1256的数据行。 这里不讲解平衡树的运行细节, 但是从上图能看出,树一共有三层, 从根节点至叶节点只需要经过三次查找就能得到结果。如下图
非聚集索引
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
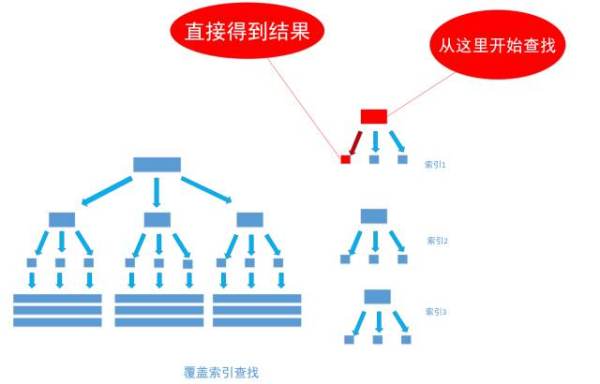
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图

我们把birthday字段上的索引改成双字段的覆盖索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
这句SQL语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图