OpenCV是一个非常强大的计算机视觉库,特别是进入3.X时代以后,它抛弃了整体统一架构,采用内核+插件的架构形式,使得主体更加稳定,附加的库更加灵活多变。
目前的OpenCV3分为稳定的核心功能库和contrib库(包含了特征匹配等)。OpenCV3.3以后,contrib库中的dnn模块支持caffe、TensorFlow和torch三种深度学习框架,可以直接读取已经训练好的模型完成相应的检测任务。
因此,需要通过Cmake对OpenCV和Contrib库进行编译。
step1 运行环境和前期准备
笔者使用的环境和准备如下:
1、Windows 10 64位
2、Visual Studio 2017 Professional
https://visualstudio.microsoft.com/zh-hans/downloads/
建议使用VS2015及以上版本 (VS2015—vc14 VS2017—vc15)
因为OpenCV3.3及以后的版本直接下载进行解压后不支持vc12(VS2013)版本的配置,需要使用Cmake自己编译出vc12的文件再进行配置。
如果实在需要使用VS 2013配置OpenCV3.3的话,可以参考下面的文章:https://www.cnblogs.com/lifeofershisui/p/7445062.html
3、Cmake 3.13.0
https://cmake.org/download/
可以在上述网站中根据自己的需要选择版本进行下载
笔者下载的是cmake-3.13.0-rc1-win64-x64.msi
4、OpenCV 3.4.3
https://opencv.org/releases.html
可以在上述网站中根据自己的需要选择版本进行下载
3.3及以后的版本都支持深度学习
5、OpenCV Contrib 3.4.3
https://github.com/opencv/opencv_contrib/releases
建议选择与自己OpenCV版本相同的Contrib库
笔者第一次下载的版本不对应导致Cmake编译出错,踩了个坑。
step2 编译OpenCV和Contrib库
笔者配置的过程参考了一些文章:
https://www.cnblogs.com/jliangqiu2016/p/5597501.html
https://blog.csdn.net/guyubit/article/details/51994171
总体配置过程还算顺利,除了在Contrib库的版本那里踩了个坑。
1、
安装完Cmake后打开gui界面,对OpenCV源码进行编译。
source code是OpenCV源码目录,build binaries是编译后生成文件的输出目录,需要自己提前建一个文件夹:
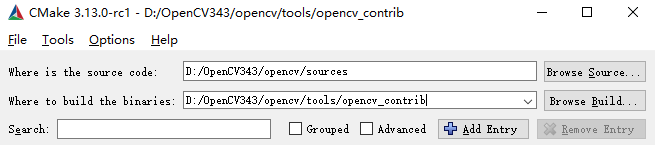
点击configure弹出选择对应的VS版本,选择自己使用的版本就可以,注意是否为x64:

2、
点击finish后等待第一次configure done。之后我们需要将额外的opencv_contrib加到工程中进行第二次编译,在配置表中找到“OPENCV_EXTRA_MODULES_PATH”,设置其参数值为open_contrib源码包中的modules目录,我的目录是“D:\OpenCV343\opencv\tools\opencv_contrib-3.4.3\modules”。
设置完成后再次点击configure,不报错的话点击generate,generate的速度比较快。
注:一定要configure到没有红色的出现才能进行generate。
3、
编译完成后直接点击open project或者到编译输出目录下找到OpenCV.sln使用自己的VS打开此解决方案:

打开解决方案后在x64 debug下重新生成解决方案:

不配置CUDA的情况下重新生成解决方案的速度还是很快的,大概十几分钟就能完成了。
接着找到CMakeTargets中的INSTALL,然后右键选择“仅用于项目”–>“仅生成INSTALL”:

生成结束后,在编译输出目录下会多一个install目录,打开发现里面的内容与下载下来的OpenCV很类似,只要按照之前的配置方法把包含目录、库目录和附加依赖项配置好就可以使用这个Contrib库了。

附加依赖项:
opencv_aruco343.lib
opencv_bgsegm343.lib
opencv_bioinspired343.lib
opencv_calib3d343.lib
opencv_ccalib343.lib
opencv_core343.lib
opencv_datasets343.lib
opencv_dnn343.lib
opencv_dpm343.lib
opencv_face343.lib
opencv_features2d343.lib
opencv_flann343.lib
opencv_fuzzy343.lib
opencv_highgui343.lib
opencv_imgcodecs343.lib
opencv_imgproc343.lib
opencv_line_descriptor343.lib
opencv_ml343.lib
opencv_objdetect343.lib
opencv_optflow343.lib
opencv_photo343.lib
opencv_plot343.lib
opencv_reg343.lib
opencv_rgbd343.lib
opencv_saliency343.lib
opencv_shape343.lib
opencv_stereo343.lib
opencv_stitching343.lib
opencv_structured_light343.lib
opencv_superres343.lib
opencv_surface_matching343.lib
opencv_text343.lib
opencv_tracking343.lib
opencv_ts343.lib
opencv_video343.lib
opencv_videoio343.lib
opencv_videostab343.lib
opencv_xfeatures2d343.lib
opencv_ximgproc343.lib
opencv_xobjdetect343.lib
opencv_xphoto343.lib
step3 深度学习模型下载及调用
深度学习目标检测主要用到的方法有SSD、SSD_MOBILENET和YOLO。
三种方法的一些区别参考以下文章:
https://www.sohu.com/a/195905376_823210
SSD论文中文版:
http://lib.csdn.net/article/deeplearning/57860
这里可以下载到已经训练好的模型(SSD):
models_VGGNet_VOC0712_SSD_300x300.tar.gz
包含:
VGG_VOC0712_SSD_300x300_iter_120000.caffemodel
deploy.prototxt
https://github.com/weiliu89/caffe/tree/ssd#models
这里可以下载到SSD_MOBILENET的模型:
mobilenet_iter_73000.caffemodel
deploy.prototxt
https://github.com/chuanqi305/MobileNet-SSD
YOLO的官方实例及使用方法:
https://github.com/AlexeyAB/darknet
https://blog.csdn.net/baidu_36669549/article/details/79798587
OpenCV中使用YOLO的实例:(放在自己的百度云上了,有测试视频、模型和原代码)
链接:https://pan.baidu.com/s/1dOWk9Rw5NpRVCwgHi0xjPg
提取码:4qdm
这里可以找到三种方法的示例代码:
ssd_object_detection.cpp
ssd_mobilenet_object_detection.cpp
yolo_object_detection.cpp
https://github.com/opencv/opencv/tree/3.4.1/samples/dnn
示例
找到示例代码中的以下部分,在两个竖线中间将proto和model加入自己下载的模型文件名,video改成自己的视频名或者图片名。
const char* params
= "{ help | false | print usage }"
"{ proto | | model configuration }" //这里加上自己的deploy.prototxt
"{ model | | model weights }" //这里加上自己的*.caffemodel
"{ camera_device | 0 | camera device number}"
"{ video | | video or image for detection}"
"{ min_confidence | 0.5 | min confidence }";
这是用SSD_MOBILENET跑出来的视频截图:

这是用YOLO跑出来的图片效果图:

总结
使用深度学习实现对目标检测总体来说准确度还可以,但是跑视频速度较慢,可能需要使用gpu加速,这一块笔者还在探索中。
本文还参考了以下文章:
https://blog.csdn.net/maweifei/article/details/81045281
https://blog.csdn.net/hunzhangzui9837/article/details/82837873
Juliet 于 2018.11