“Grounding DINO:Marrying DINO with Grounded Pre-Training for Open-Set Object Detection”的官方 PyTorch 实现:SoTA 开放集对象检测器。
一、Helpful Tutorial
论文地址:
https://arxiv.org/abs/2303.05499
在 YouTube 上观看介绍视频:
https://www.youtube.com/watch?v=wxWDt5UiwY8&feature=youtu.be
Try the Colab Demo:
https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb
Try Official Huggingface Demo:
https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo
二、相关的论文工作
2.1 相关的论文整理

- Grounded-SAM: Marrying Grounding DINO with Segment Anything
- Grounding DINO with Stable Diffusion
- Grounding DINO with GLIGEN for Controllable Image Editing
- OpenSeeD: A Simple and Strong Openset Segmentation Model
- SEEM: Segment Everything Everywhere All at Once
- X-GPT: Conversational Visual Agent supported by X-Decoder
- GLIGEN: Open-Set Grounded Text-to-Image Generation
- LLaVA: Large Language and Vision Assistant
2.2 论文的亮点
本工作的亮点:
- Open-Set Detection. Detect everything with language!
- High Performancce. COCO zero-shot 52.5 AP (training without COCO data!). COCO fine-tune 63.0 AP.
- Flexible. Collaboration with Stable Diffusion for Image Editting.
2.3 论文介绍

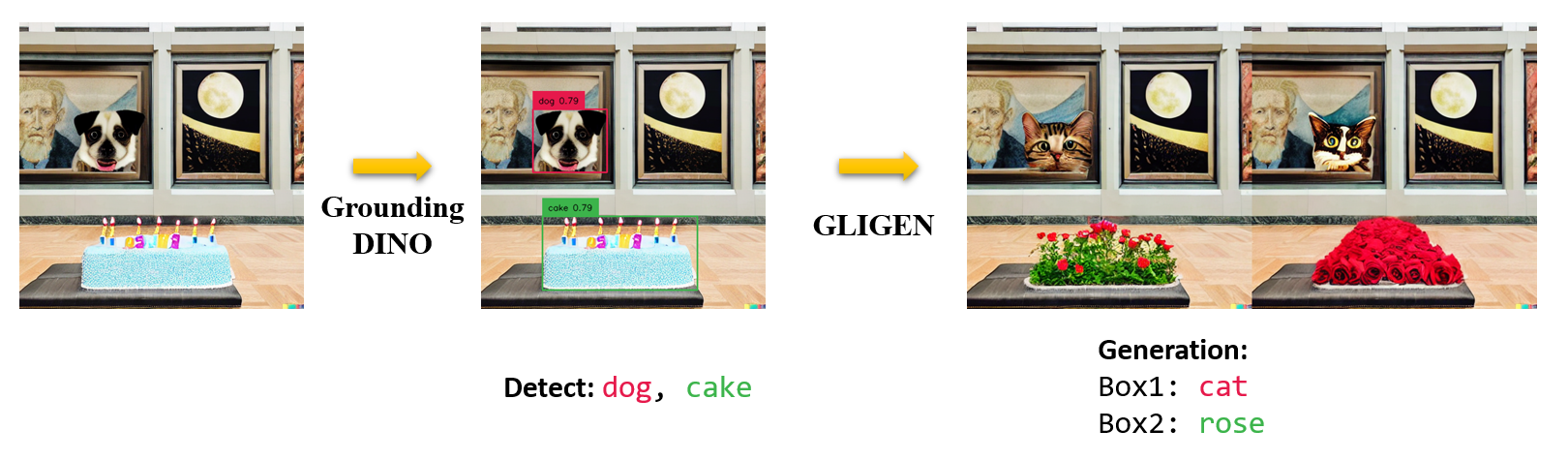
2.4 Marrying Grounding DINO and GLIGEN
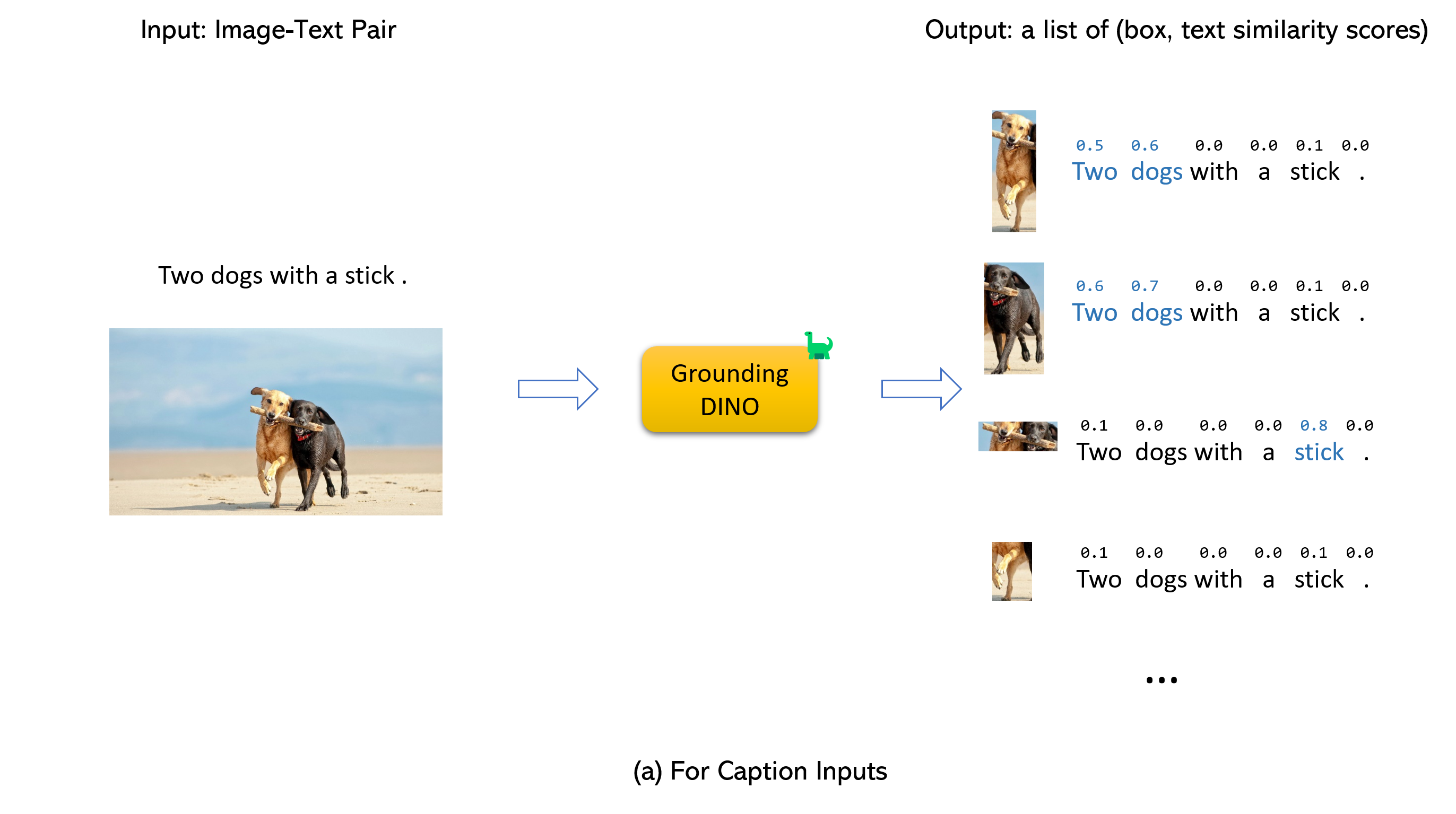
2.5 输入和输出的说明 / 提示
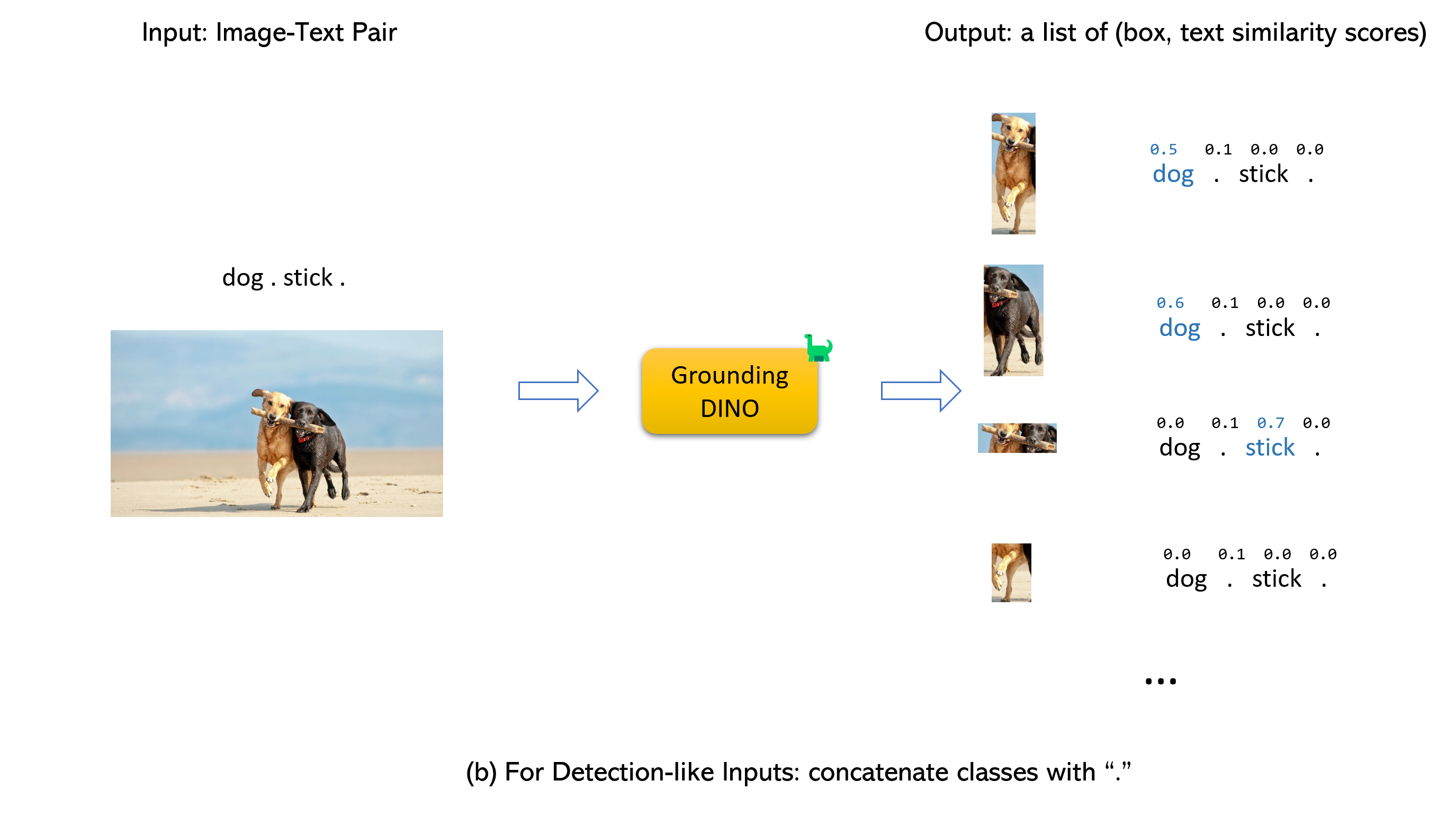
- Grounding DINO accepts an (image, text) pair as inputs.
- It outputs 900 (by default) object boxes. Each box has similarity scores across all input words. (as shown in Figures below.)
- We defaultly choose the boxes whose highest similarities are higher than a box_threshold.
- We extract the words whose similarities are higher than the text_threshold as predicted labels.
- If you want to obtain objects of specific phrases, like the dogs in the sentence two dogs with a stick., you can select the boxes with highest text similarities with dogs as final outputs.
- Note that each word can be split to more than one tokens with differetn tokenlizers. The number of words in a sentence may not equal to the number of text tokens.
- We suggest separating different category names with . for Grounding DINO.
三、环境配置过程
3.1 我的环境
系统:最新的ubuntu系统
显卡:3090
CUDA:11.3
如果您有 CUDA 环境,请确保设置了环境变量 CUDA_HOME。 如果没有可用的 CUDA,它将在 CPU-only 模式下编译。
3.2 配置过程
3.2.1 Clone the GroundingDINO repository from GitHub
git clone https://github.com/IDEA-Research/GroundingDINO.git
下载后即可找到对应的文件夹:
3.2.2 Change the current directory to the GroundingDINO folder
cd GroundingDINO/
3.2.3 Install the required dependencies in the current directory
pip3 install -q -e .
不知道为什么,我这个下载一直报错!换一个新的下载方式:
python setup.py install
但是也会飘红!
这个时候不要害怕,遇到错误的包,直接使用 pip 下载即可,耐得住性子,最后再运行上面的安装命令,即可顺利成功!
3.2.4 Create a new directory called “weights” to store the model weights
mkdir weights
Change the current directory to the “weights” folder:
cd weights
Download the model weights file:
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
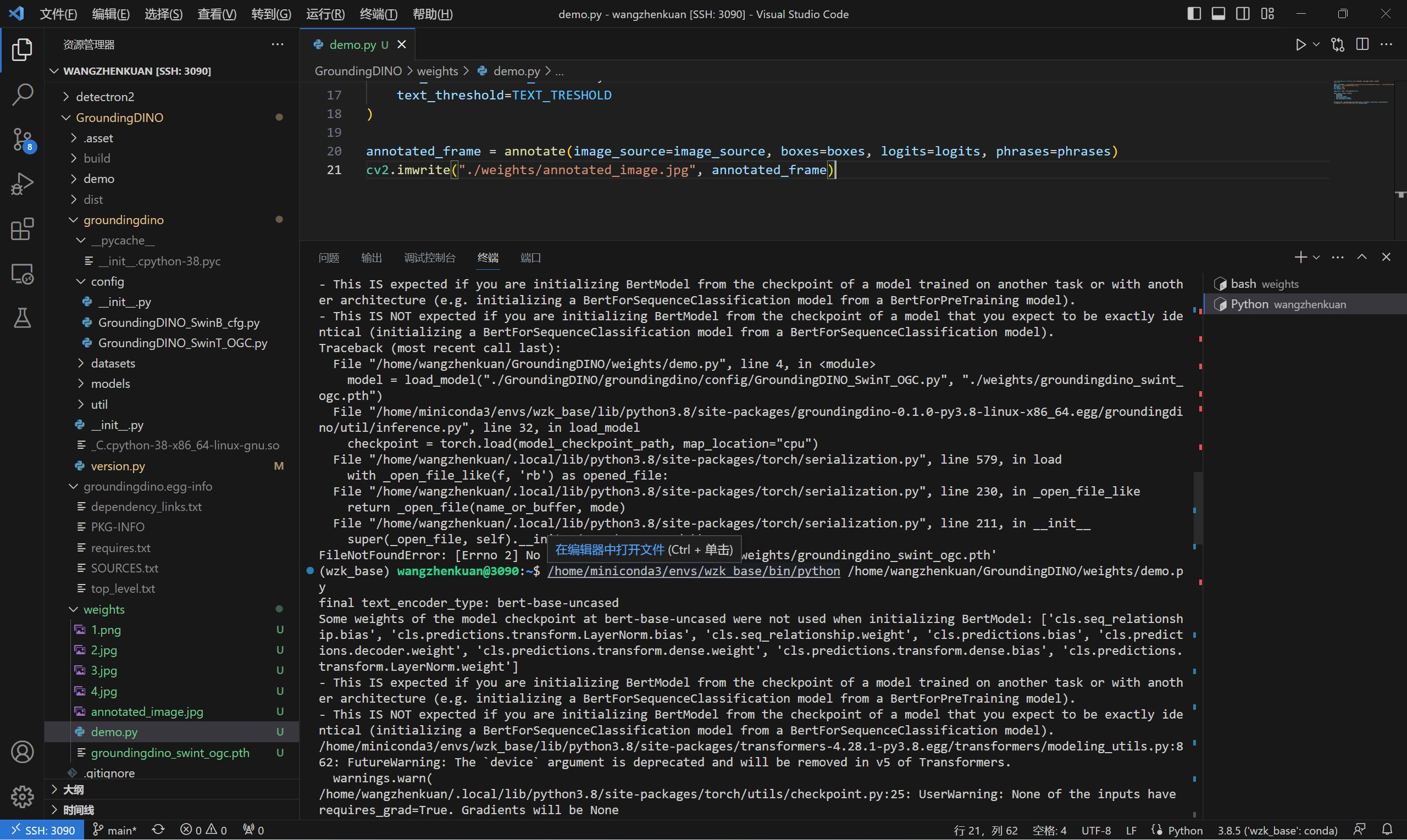
四、测试
Check your GPU ID (only if you’re using a GPU):
nvidia-smi
Replace { GPU ID}, image_you_want_to_detect.jpg, and “dir you want to save the output” with appropriate values in the following command:
CUDA_VISIBLE_DEVICES={
GPU ID} python demo/inference_on_a_image.py \
-c /GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \
-p /GroundingDINO/weights/groundingdino_swint_ogc.pth \
-i image_you_want_to_detect.jpg \
-o "dir you want to save the output" \
-t "chair"
[--cpu-only] # open it for cpu mode
当然了,我们也可以使用 Python 进行测试:
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
model = load_model("./GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py", "./GroundingDINO/weights/groundingdino_swint_ogc.pth")
IMAGE_PATH = "./GroundingDINO/weights/1.png"
TEXT_PROMPT = "person . bike . bottle ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
cv2.imwrite("./GroundingDINO/weights/annotated_image.jpg", annotated_frame)
我们的测试原图片为:

测试后的图片为: