BeautifulSoup可以解析html文件,配合request库可以简单快速地爬取一些网页信息。
BeautifulSoup 参考资料:
https://blog.csdn.net/maverick17/article/details/79610050
https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
如下图所示,以爬取环球网中国新闻为例,我们需要与“中国”有关的新闻的标题和正文:
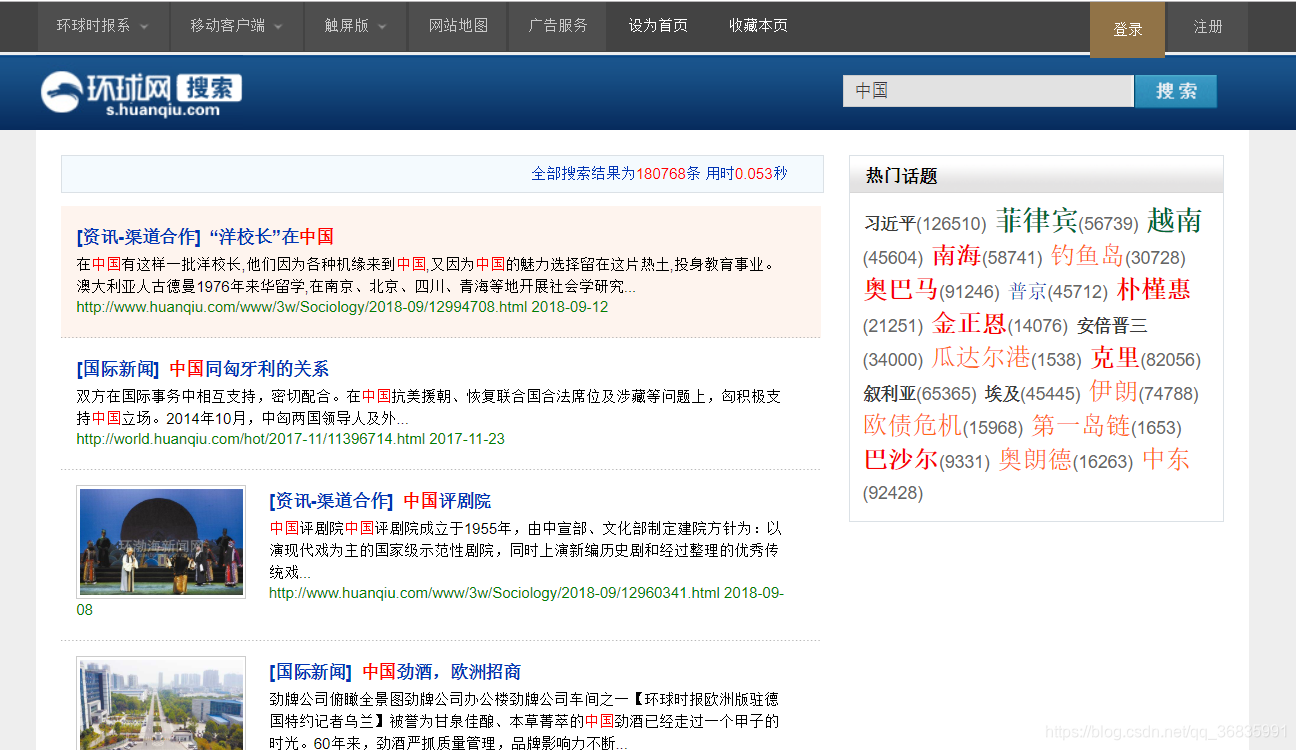
首先根据Python中的request库,定义一个页面请求函数,该函数可以返回url对应的html页面的内容:
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(url)
print("failed")
return ""
然后分析网页结构:
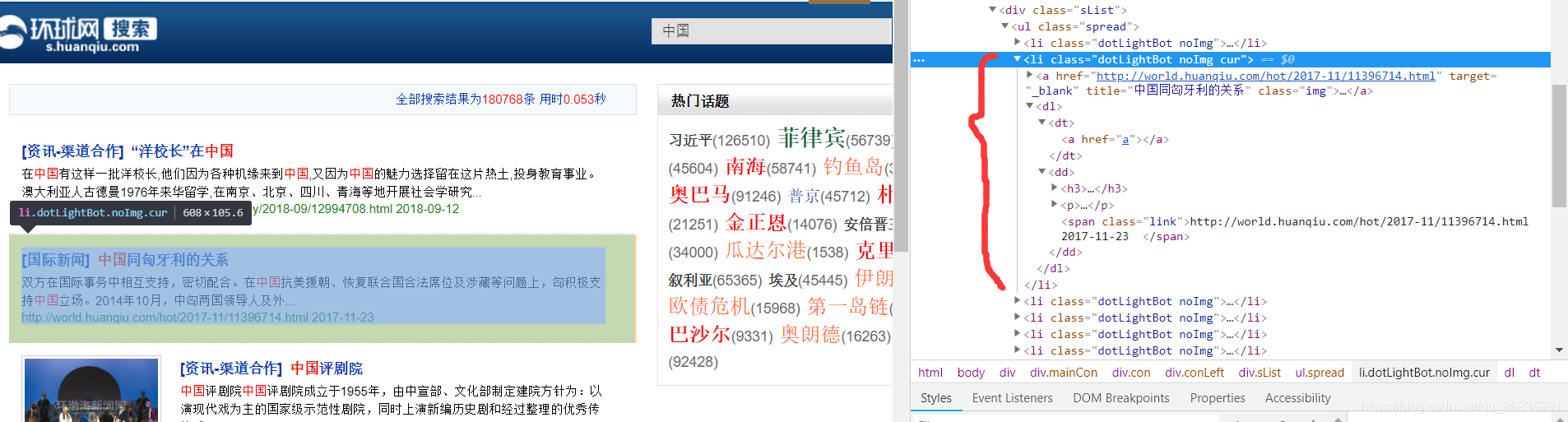
该页面是一个搜索结果页面,所有的搜索结果都是一个<li>标签,并且类名为dotLightBot,并且该标签下的第一个<a>标签保存了该条新闻的链接和标题信息。那么定义一个函数爬取该搜索结果下所有新闻的标题和链接。这里可使用BeautifulSoup中的html.parser解析页面内容,根据findAll()、find_all()、find()、select()等一系列函数筛选找到我们所需内容的标签,然后使用get_text()直接获取标签内容,或者如a['href']直接取得标签中的属性值,将其整合成列表后返回。
def findUrls(html):
ulist = []
soup = BeautifulSoup(html, "html.parser")
for item in soup.findAll("li", attrs={"class": "dotLightBot"}):
# 忽略掉图集新闻
if "图集" in item.get_text():
continue
a = item.find('a')
try:
ulist.append({'title': a['title'], 'href': a['href']})
except:
print(item)
print(a)
return ulist
此时可得到一系列新闻标题及其对应的超链接,但是我们需要得到新闻的正文,因此需要根据得到的链接再爬取新闻正文,打开一条新闻的链接对页面进行分析:
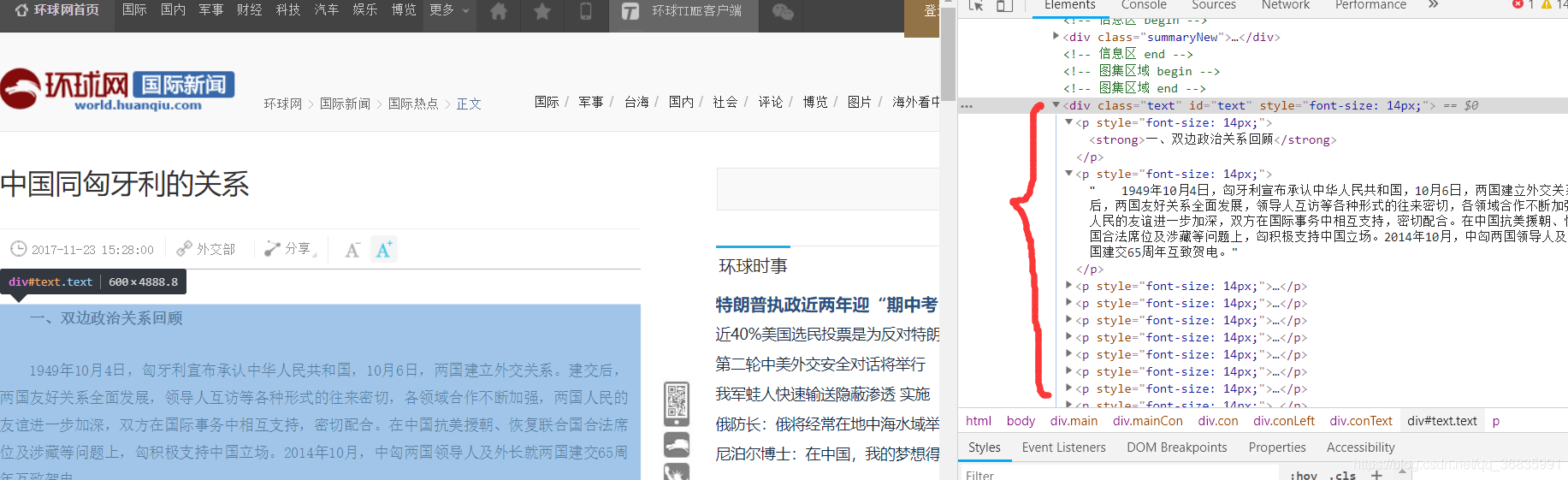
可以发现正文内容均被封装在id和class都为text的<div>下的<p>标签中,此时可根据id或类名筛选出所需<div>即可(最好根据所需标签的唯一属性进行设置筛选条件,如果同时得到了其他不需要的标签,需要进一步筛选)。
所以可定义一个函数爬取之前获得的新闻链接里的正文内容,首先访问新闻链接,然后筛选得到所需标签,获取其文本内容,然后将其拼接或其他处理即可。
在这个函数中,我将其正文中的空格和回车删除,拼接成了一长段话。考虑到小标题或者一些其他没有结尾符的段落,则拼接时对其加上一个句号,防止产生的句子不通顺。
def findArticles(ulist):
atlist = []
for url in ulist:
ht = getHTMLText(url['href'])
soup = BeautifulSoup(ht, "html.parser")
# 删除掉所有的脚本标签
[s.extract() for s in soup('script')]
for item in soup.select(".text"):
text = item.get_text().split()
ends = ('。', '?', '!', '。”',"?”", "!”")
article = ""
for s in text:
if s=="":
continue
if s.endswith(ends):
article += s
else:
article += s + '。'
at = {'title': url['title']}
at['article'] = article
if at['article']!="" and at['title']!="":
atlist.append(at)
return atlist
在这个过程中有一个小问题,比如使用a.get_text()或者a.string都可以获取标签内容,但是如果该标签下仍有子标签,a.string将会报错,get_text()会将子标签的内容一起返回。
最后,翻页时只需要修改初始url即可,一般网站搜索结果的分页显示都是url中的一个page参数递增记录的。爬取99页搜索结果,并且将所有内容转化成json文件,得到结果如下:

所有代码如下:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import bs4
import json
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(url)
print("failed")
return ""
def findUrls(html):
ulist = []
soup = BeautifulSoup(html, "html.parser")
for item in soup.findAll("li", attrs={"class": "dotLightBot"}):
# 忽略掉图集新闻
if "图集" in item.get_text():
continue
a = item.find('a')
try:
ulist.append({'title': a['title'], 'href': a['href']})
except:
print(item)
print(a)
return ulist
def findArticles(ulist):
atlist = []
for url in ulist:
ht = getHTMLText(url['href'])
soup = BeautifulSoup(ht, "html.parser")
# 删除掉所有的脚本标签
[s.extract() for s in soup('script')]
for item in soup.select(".text"):
text = item.get_text().split()
ends = ('。', '?', '!', '。”',"?”", "!”")
article = ""
for s in text:
if s=="":
continue
if s.endswith(ends):
article += s
else:
article += s + '。'
at = {'title': url['title']}
at['article'] = article
if at['article']!="" and at['title']!="":
atlist.append(at)
return atlist
def main():
atlist = []
url = "http://s.huanqiu.com/s/?q=%E4%B8%AD%E5%9B%BD&p="
for i in range(99):
print("page is " + str(i+1))
print("json size is " + str(len(atlist)))
html = getHTMLText(url + str(i+1))
ulist = findUrls(html)
at = findArticles(ulist)
atlist.extend(at)
print(len(atlist))
with open("huanqiu.json","w", encoding='utf-8') as fin:
json.dump(atlist, fin, ensure_ascii=False)
main()