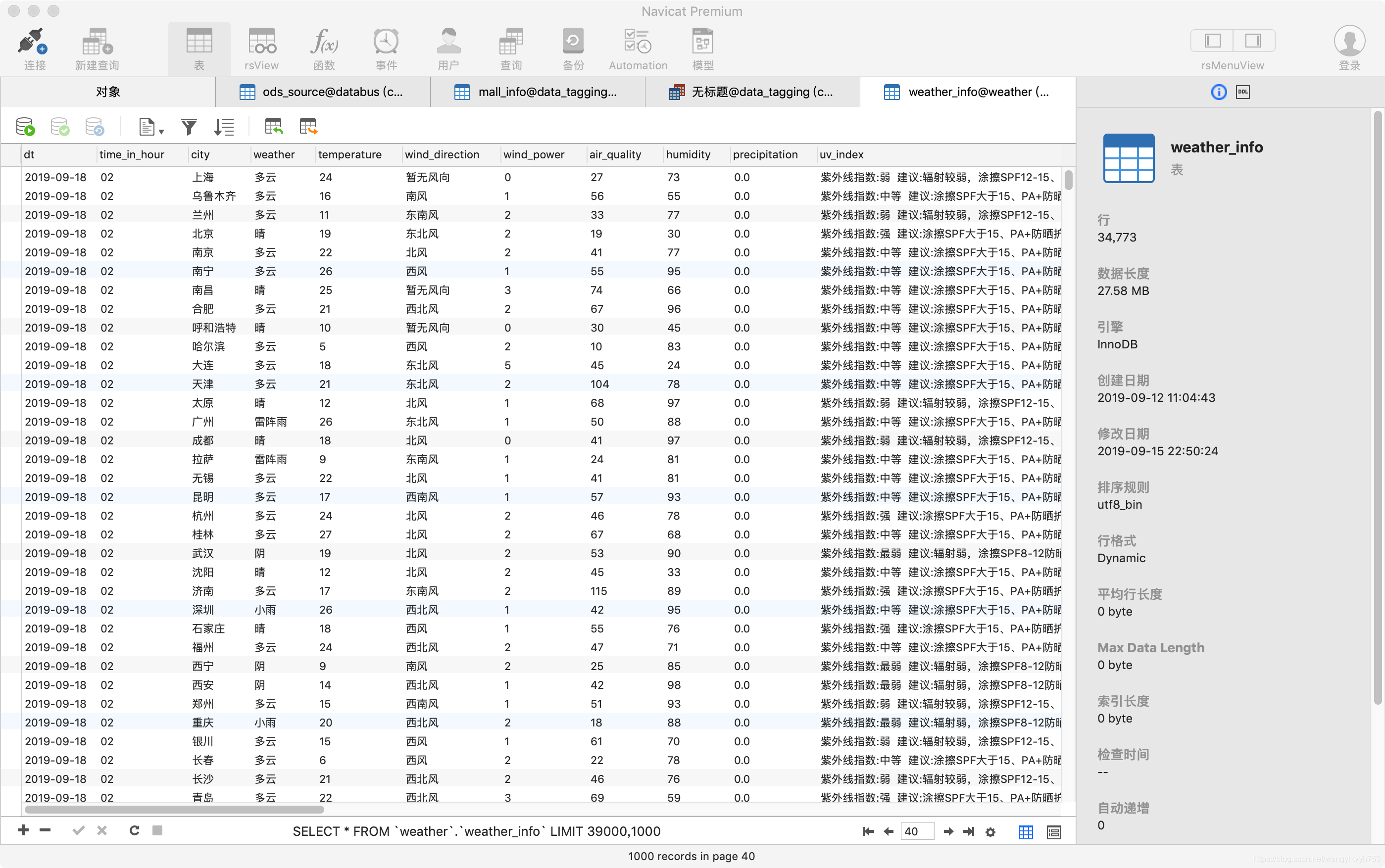
我的环境是python3,目标是爬取中国天气网(http://www.weather.com.cn)中的各大城市天气信息入MySQL库。
首先引入HTMLParser模块,request网络请求模块,pymysql(连接mySQL)模块,json模块,pandas模块,日期datetime模块
from html.parser import HTMLParser
from urllib import request
import pymysql
import json
from get_city_code import query_city_code
import pandas as pd
from datetime import datetime,date,timedelta其中,get_city_code是自己写的python,用来查询各个城市在天气网中的代码。这是因为在中国天气网上各个城市分别用不同的网页来显示,而网页名称常常是用编码来命名的。例如北京天气网页为http://www.weather.com.cn/weather1d/101010100.shtml,这里的101010100就是北京的城市编码,各个城市天气信息的差别就在这。
正常来说城市编码应该从网页上爬取,由于我只需要主要大城市的代码,所以这里直接列举查询。query_city_code入参是汉字城市名,出参是数字代码。具体可参考https://blog.csdn.net/ljheee/article/details/54134621。例:query_city_code('北京')返回结果就是'101010100'。各个城市都一样,所以这里以北京天气为例。
首先根据网页地址获取目标的网页。
url_address = "http://www.weather.com.cn/weather1d/101010100.shtml"
req = request.Request(url_address)
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
# 解析返回内容
with request.urlopen(req) as html:
# data为网页返回内容
data = html.read().decode("utf-8")其次要对获得的网页内容进行解析,这里定义了一个解析器的类(WeatherHtmlParser),专门用于天气网网页解析。
# 解析中国天气网HTML解析器,其继承了HTMLParser函数,主要重新定义了三个函数handle_starttag(tag,attrs),handle_endtag(tag,attrs),handle_data(data),主要是对这三个函数的理解,就能知道如何解析的。
class WeatherHtmlParser(HTMLParser):
#解析器(类)的初始化函数,这里的city表示城市的名字,date_t表示日期,需要在实力化的时候予以给定,这里主要是我爬的东西比较多(包含温度,湿度等信息),很多初始化是不必要的。
def __init__(self,city,date_t):
self.flag_daily = False
self.flag_24h = False
self.flag_index = False
self.date = date_t
self.date_next = self.get_diff_date(1)
self.city = city
self.weather_data_daily_frame = pd.DataFrame(columns=['日期','时刻','城市','天气'])
self.data_index_temp = ""
self.begin_index_cal = False
self.end_index_cal = False
self.weather_data_24h_frame = pd.DataFrame(columns=['日期','时刻','城市','温度','风向','风力','降水量','湿度','空气质量'])
self.weather_live_index_frame = pd.DataFrame(columns=['日期','时刻','城市','紫外线指数','减肥指数','血糖指数','穿衣指数','洗车指数','空气污染扩散指数'])
self.daily_frame = pd.DataFrame(columns=['日期','时刻','城市','天气','温度','风向','风力','空气质量指数','湿度','降水量','紫外线指数','减肥指数','血糖指数','穿衣指数','洗车指数','空气污染扩散指数'])
super(WeatherHtmlParser, self).__init__()
def get_diff_date(self,n):
date_diff = (datetime.strptime(self.date,'%Y-%m-%d') + timedelta(days=n)).strftime("%Y-%m-%d")
return date_diff
#这里是自定义的,用以获取标签属性值,从而更加精确定位
def _get_attr(self,attrs,attrname):
for attr in attrs:
if attr[0] == attrname:
return attr[1]
return None
# 解析器是从头到尾遍历每一个标签,参数tag是当前解析网页标签名。handle_starttag相当于处理<div></div>标签中的<div>
def handle_starttag(self, tag, attrs):
#我们发现天气信息是在<ul>标签内,并且ul标签属性"class"为clearfix内部。所以在解析器发现这个ul标签时,将预先定义的flag置为True。方便后面的handle_data处理。
if tag == "ul" and self._get_attr(attrs,'class') == 'clearfix':
self.flag_index = True
if tag == "script":
self.flag_daily = True
self.flag_24h = True
# 解析器是从头到尾遍历每一个标签,参数tag是当前标签名。handle_endtag相当于处理<div></div>标签中的</div>,注意</div>的标签tag也是div,之前以为是"</div>"还踩了各坑。这里配合handle_flag完成了一次flag的开和关。注意有可能flag会有多次的开和关,主要影响的是handle_data的处理。
def handle_endtag(self, tag):
if tag == "ul":
self.flag_index = False
if tag == "script":
self.flag_daily = False
self.flag_24h = False
#handle_data()是对标签内容进行处理,data表示标签内的内容。注意这个data表示的是最小标签内容,例如<div><p>hello</p><p> world</p><div>,如果你想获得div标签中的内容:hello world.但是这里解析的却是hello或者world。这里遇到的坑,希望能避免。
def handle_data(self, data):
#这里就体现出flag的意义了,只有flag为True(或者自设定条件)来获取想要的内容。下面是自己筛选的内容,实际上到这里整个解析网页已经结束了。
if self.flag_24h:
if "observe24h_data =" in data:
data = data.strip("\n")
data_index_od = data.index('"od2":')
data_temp = data[data_index_od+6:-3]
index_m = data_temp.rindex('}')
index_b = data_temp.rindex(']')
if index_b != (index_m + 1):
data_temp = data_temp[:(index_m+1)]+data_temp[index_b:]
print(data_temp)
# data_24 = data.strip("var observe24h_data = {'od)
weather_data_24h = json.loads(data_temp)
#self.date = weather_data_24h["od"]["od0"][:4] + '-' + weather_data_24h["od"]["od0"][4:6] + '-' +weather_data_24h["od"]["od0"][6:8]
#self.date_next = self.get_diff_date(1)
#print(isinstance(weather_data_24h,list))
weather_data_24h.reverse()
b_is_next = False
index = 0
for weather_item in weather_data_24h:
if weather_item['od22'] == 'null':
continue
if weather_item['od21'] == '00':
b_is_next = True
if b_is_next == False:
temp_item = [self.get_diff_date(-1),weather_item["od21"],self.city,weather_item["od22"],weather_item["od24"],weather_item["od25"],weather_item["od26"],weather_item["od27"],weather_item["od28"]]
else:
temp_item = [self.date,weather_item["od21"],self.city,weather_item["od22"],weather_item["od24"],weather_item["od25"],weather_item["od26"],weather_item["od27"],weather_item["od28"]]
#解析得到的温度,湿度,风向,风力等内容(对应代码中的"od21","od22"等)放到了self.weather_data_24h_frame中,这是一个pandas数据结构,后续将其依次放入mysql中
self.weather_data_24h_frame.loc[index] = temp_item
index += 1
#print(self.weather_data_24h_frame)
if self.flag_daily:
if "var hour3data=" in data:
data = data.strip("\n")
data = data.strip("var hour3data=")
self.weather_data = json.loads(data)
index = 0
for list_item in self.weather_data["1d"]:
list_item_value = list_item.split(',')
if '日' in list_item_value[0]:
index_1 = list_item.index('日')
index_2 = list_item.index('时')
date_now = list_item_value[0][:index_1]
hour_now = list_item_value[0][(index_1+1):index_2]
hour_next = str(int(hour_now) + 1)
if len(hour_next) < 2:
hour_next = '0' + hour_next
hour_after_2 = str(int(hour_now) + 2)
if len(hour_after_2) < 2:
hour_after_2 = '0' + hour_after_2
if int(hour_now) < 22:
if date_now == self.date[8:10]:
temp_item = [self.date,hour_now,self.city, list_item_value[2]]
temp_item1 = [self.date, hour_next,self.city, list_item_value[2]]
temp_item2 = [self.date, hour_after_2, self.city, list_item_value[2]]
else:
temp_item = [self.date_next, hour_now, self.city, list_item_value[2]]
temp_item1 = [self.date_next, hour_next, self.city, list_item_value[2]]
temp_item2 = [self.date_next, hour_after_2, self.city, list_item_value[2]]
elif int(hour_now) == 22:
if date_now == self.date[8:10]:
temp_item = [self.date, hour_now, self.city, list_item_value[2]]
temp_item1 = [self.date, hour_next, self.city, list_item_value[2]]
temp_item2 = [self.date_next, '00', self.city, list_item_value[2]]
else:
temp_item = [self.date_next, hour_now, self.city, list_item_value[2]]
temp_item1 = [self.date_next, hour_next, self.city, list_item_value[2]]
temp_item2 = [self.get_diff_date(2), '00', self.city, list_item_value[2]]
else:
if date_now == self.date[8:10]:
temp_item = [self.date,hour_now,self.city, list_item_value[2]]
temp_item1 = [self.date_next, '00',self.city, list_item_value[2]]
temp_item2 = [self.date_next, '01', self.city, list_item_value[2]]
else:
temp_item = [self.date_next, hour_now, self.city, list_item_value[2]]
temp_item1 = [self.get_diff_date(2), '00', self.city, list_item_value[2]]
temp_item2 = [self.get_diff_date(2), '01', self.city, list_item_value[2]]
self.weather_data_daily_frame.loc[index] = temp_item
index += 1
self.weather_data_daily_frame.loc[index] = temp_item1
index += 1
self.weather_data_daily_frame.loc[index] = temp_item2
index += 1
#print(self.weather_data_daily_frame)
if self.flag_index:
self.data_index_temp += data
self.begin_index_cal = True
else:
self.begin_index_cal = False
if self.data_index_temp and not self.begin_index_cal and not self.end_index_cal and "紫外线指数" in self.data_index_temp:
data_index_str_list = self.data_index_temp.split("\n")
data_index_1 = data_index_str_list.index('紫外线指数')
data_index_2 = data_index_str_list.index('减肥指数')
data_index_3 = data_index_str_list.index('健臻·血糖指数')
data_index_4 = data_index_str_list.index('穿衣指数')
data_index_5 = data_index_str_list.index('洗车指数')
data_index_6 = data_index_str_list.index('空气污染扩散指数')
for index in range(24):
temp_item = []
temp_item.append(self.date)
hour_temp = str(index)
if len(hour_temp) == 1:
hour_temp = "0" + hour_temp
temp_item.append(hour_temp)
temp_item.append(self.city)
temp_item.append(
'紫外线指数:' + data_index_str_list[(data_index_1 - 1)] + ' 建议:' + data_index_str_list[(data_index_1 + 1)])
temp_item.append(
'减肥指数:' + data_index_str_list[(data_index_2 - 1)] + ' 建议:' + data_index_str_list[(data_index_2 + 1)])
temp_item.append(
'血糖指数:' + data_index_str_list[(data_index_3 - 1)] + ' 建议:' + data_index_str_list[(data_index_3 + 1)])
temp_item.append(
'穿衣指数:' + data_index_str_list[(data_index_4 - 1)] + ' 建议:' + data_index_str_list[(data_index_4 + 1)])
temp_item.append(
'洗车指数:' + data_index_str_list[(data_index_5 - 1)] + ' 建议:' + data_index_str_list[(data_index_5 + 1)])
temp_item.append(
'空气污染扩散指数:' + data_index_str_list[(data_index_6 - 1)] + ' 建议:' + data_index_str_list[(data_index_6 + 1)])
self.weather_live_index_frame.loc[index] = temp_item
self.end_index_cal = True最后利用上述的解析器进行解析刚才得到的网页
#实例化解析器,得到对象html_parser
html_parser = WeatherHtmlParser(city_name, date.today().strftime('%Y-%m-%d'))
#将网页内容data送给对象html_parser解析
html_parser.feed(data)
#html_parser结束解析
html_parser.close()
#处理对象html_parser的相关内容,这里入了Mysql库。
put_result_to_sql(conn, html_parser.weather_data_daily_frame, html_parser.weather_data_24h_frame, html_parser.weather_live_index_frame)入MySQL库就不展开了,看下效果吧。