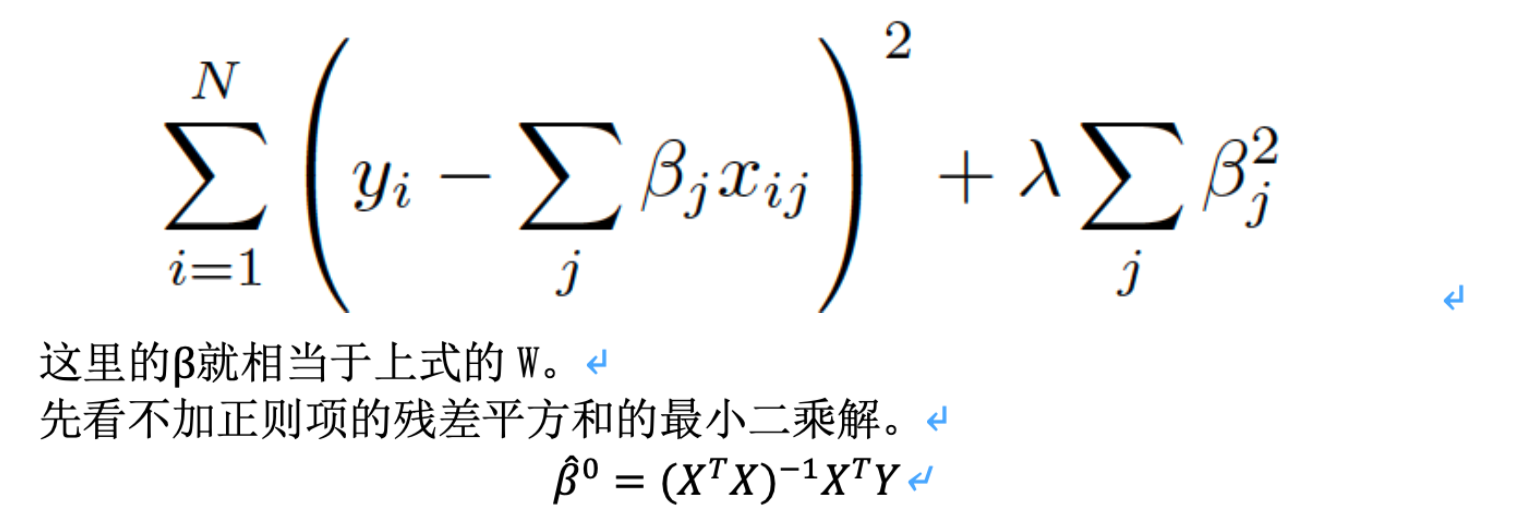最近课程作业让阅读了 这篇经典的论文,写篇学习笔记。
这篇经典的论文,写篇学习笔记。
主要是对论文前半部分Lasso思想的理解,后面实验以及参数估计部分没有怎么写,中间有错误希望能提醒一下,新手原谅一下。
1.整体思路
作者提出了一种收缩和选择方法Lasso,这是一种可以用于线性回归的新的估计方法。它具有子集选择和岭回归的各自的优点。像子集选择一样可以给出具有解释力的模型,又能像岭回归一样具有可导的特性,比较稳定。同时避免了子集选择不可导,部分变化引起整体巨大变化这一不稳定的缺点。以及岭回归不能很好的收缩到0的缺点。
2.对文章目的理解
为了理解这篇文章是做了什么事情,先要明白回归的收缩和选择是用来做什么的。
我们用某一个模型F来回归拟合某一问题时,往往容易遇到过拟合的问题。这是经常是由于,模型过于复杂,比如参数过多,变量指数过高。过度拟合了训练数据,导致模型的泛化能力变差。这是需要引入正则化项(惩罚项)来使模型最后训练的结果不至于太过于复杂(过拟合)。
正则化一般具有如下形式:
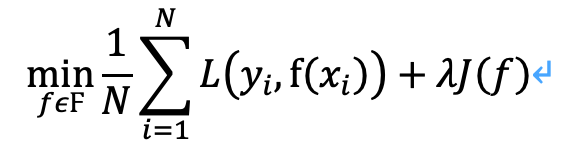
![]() 是经验风险。J(f)是正则化项,就代表了对模型复杂度的惩罚,只要它能做到模型越复杂,J(f)值越大。所以最小化损失函数时,就会令经验风险尽量小的同时,考虑让模型复杂度也不要太大。这样虽然会提高模型的训练误差,甚至可能某些正则化操作会使模型偏差(Bias)变大,但是会提高模型的稳定程度(方差更小,模型更简单),减少模型的泛化误差。
是经验风险。J(f)是正则化项,就代表了对模型复杂度的惩罚,只要它能做到模型越复杂,J(f)值越大。所以最小化损失函数时,就会令经验风险尽量小的同时,考虑让模型复杂度也不要太大。这样虽然会提高模型的训练误差,甚至可能某些正则化操作会使模型偏差(Bias)变大,但是会提高模型的稳定程度(方差更小,模型更简单),减少模型的泛化误差。
这里有两个问题!
(1) 模型的简单体现在什么方面?(模型如何简化)
(2) 正则化是怎么让模型变简单的?
先说问题(1),考虑模型![]() 。向量X是特征向量,向量W是其对应的参数。模型复杂,一是体现在特征过多,第二是体现在X的指数过高。那么如何令模型变得简单呢,自然而然的想到若某些参数为0,那么就相当于不考虑这些特征Xi了(这就是子集选择的思想)。或者令某些参数缩小,这样不重要的特征对结果造成的影响也会变小(这就是shrinkage的思想)。当然有些参数在缩小过程中会变成0,这就是在收缩过程中起到了子集选择的效果。
。向量X是特征向量,向量W是其对应的参数。模型复杂,一是体现在特征过多,第二是体现在X的指数过高。那么如何令模型变得简单呢,自然而然的想到若某些参数为0,那么就相当于不考虑这些特征Xi了(这就是子集选择的思想)。或者令某些参数缩小,这样不重要的特征对结果造成的影响也会变小(这就是shrinkage的思想)。当然有些参数在缩小过程中会变成0,这就是在收缩过程中起到了子集选择的效果。
那么关键的来了,问题(2)正则化是怎么让模型变简单的呢。上一段分析出,如果让某些不重要的参数进行收缩,能够使模型变得简化。再来看看正则化的例子:
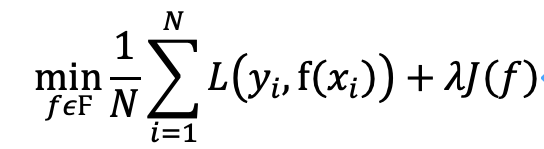
以J(f)取||w||为例,可以看出,如果参数W越多,或者整理模的平方和越大,||w||就越大。所以在最小化代价函数的过程,就会考虑让参数的平方和也尽可能小(整体最小的前提下)。所以设不加正则化项的估计出的向量为![]() ,加了正则化项的估计出得参数向量为
,加了正则化项的估计出得参数向量为![]() 。那么可以看出
。那么可以看出![]() 。所以正则化项起到了shrinkage参数的效果,如果有些参数在收缩过程中精确到0,就相当于子集选择的效果(我们是希望这样的)。
。所以正则化项起到了shrinkage参数的效果,如果有些参数在收缩过程中精确到0,就相当于子集选择的效果(我们是希望这样的)。
那么这篇文章的目的就可以理解了,作者提出的Lasso就是一种具有岭回归(可导可直接求最小值)和子集选择(部分参数为0)的优点的估计方法(也可以说一种正则化的方法)。
3.方法对比及Lasso引入
之前是在word写的,这里为了方便截图一下。