本小节我们将学习一下Hystrix。
-
什么是Hystrix
hystrix对应的中文名字是“豪猪”,豪猪周身长满了刺,能保护自己不受天敌的伤害,代表了一种防御机制,这与hystrix本身的功能不谋而合,因此Netflix团队将该框架命名为Hystrix,并使用了对应的卡通形象做作为logo。简单来说Hystrix是一个断融机制以保证微服务架构下各个微服务节点始终保持高可用。 -
Hystrix能干什么
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。 -
Hystri的应与场景
在微服务架构中,根据业务来拆分成一个个的服务,服务与服务之间可以相互调用(RPC) 。为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自身的原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。如下图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。
()d
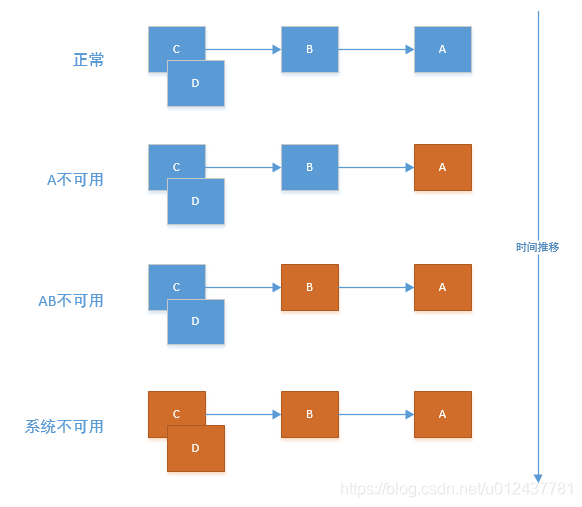
此时使用Hystrix的熔断器机制便可很好地解决服务间互相调用出现雪崩效应。
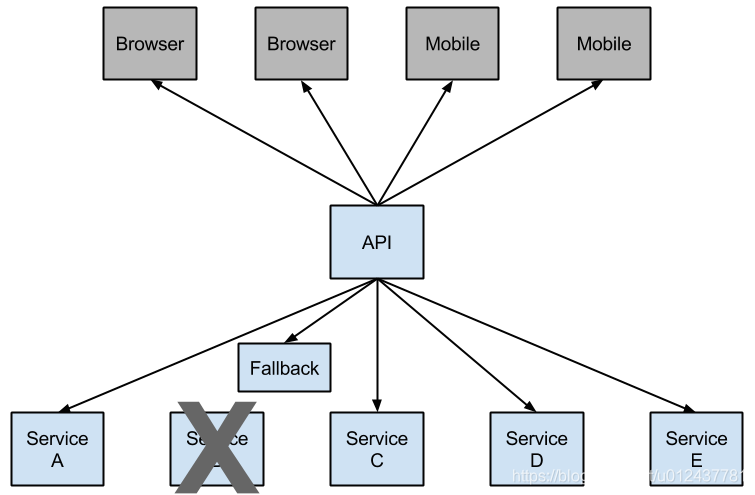
-
Hystrix熔断器(机制)
我们来先看一张图: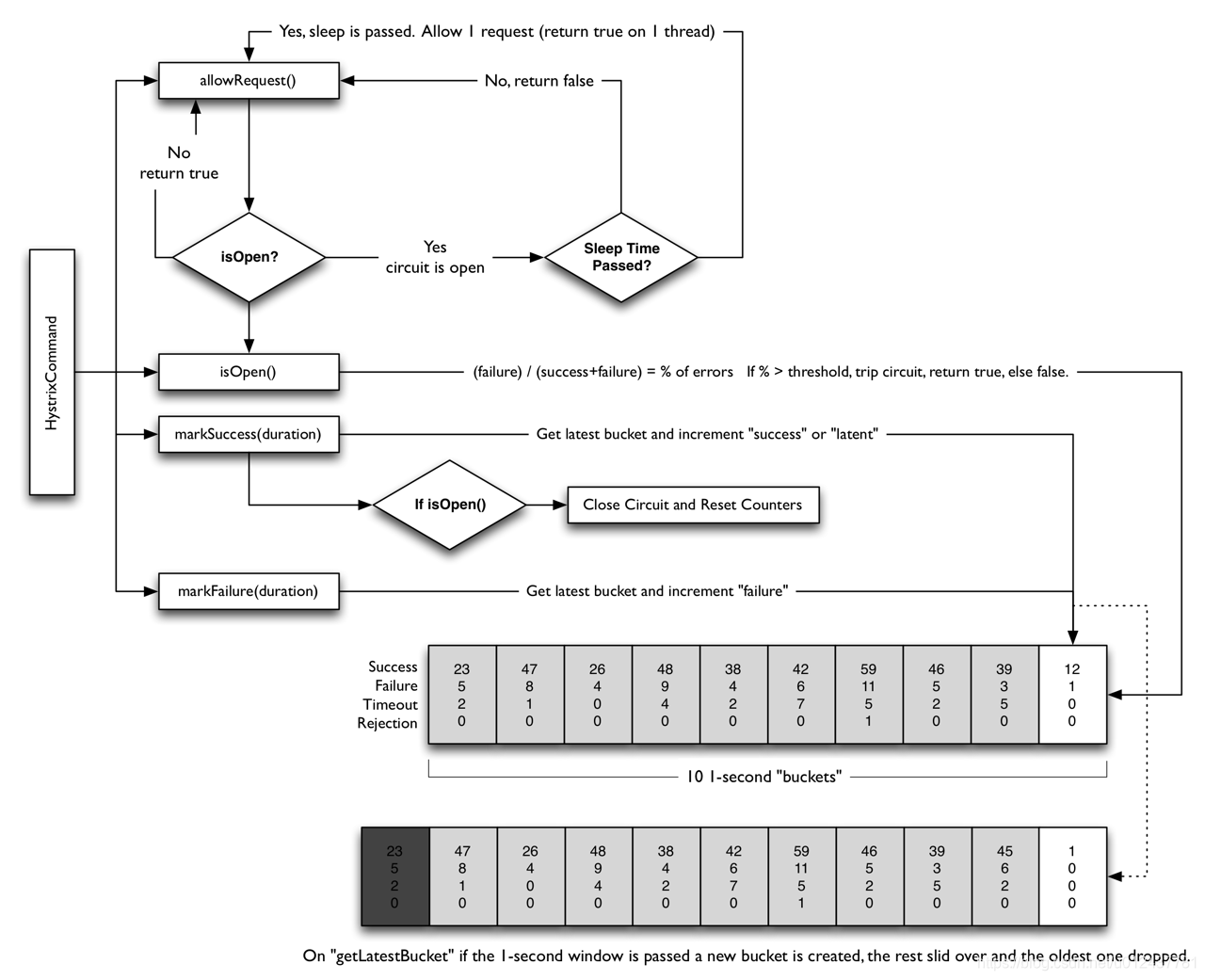
Hystrix的熔断器其实可以理解为就是一个统计中心,统计一定时间窗口内访问次数,成功次数,失败次数等数值判定是否发生熔断。发生电路熔断的过程如下:- 假设电路上的音量达到一定阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold)
- 并假设错误百分比超过阈值错误百分(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage)
- 然后断路器从CLOSED转换到OPEN。它是开放的,它使所有针对该断路器的请求短路。
- 经过一段时间(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds),下一个单个请求是通过(这是HALF-OPEN状态)。 如果请求失败,断路器将在睡眠窗口持续时间内返回到OPEN状态。 如果请求成功,断路器将转换到CLOSED,逻辑1.重新接管。
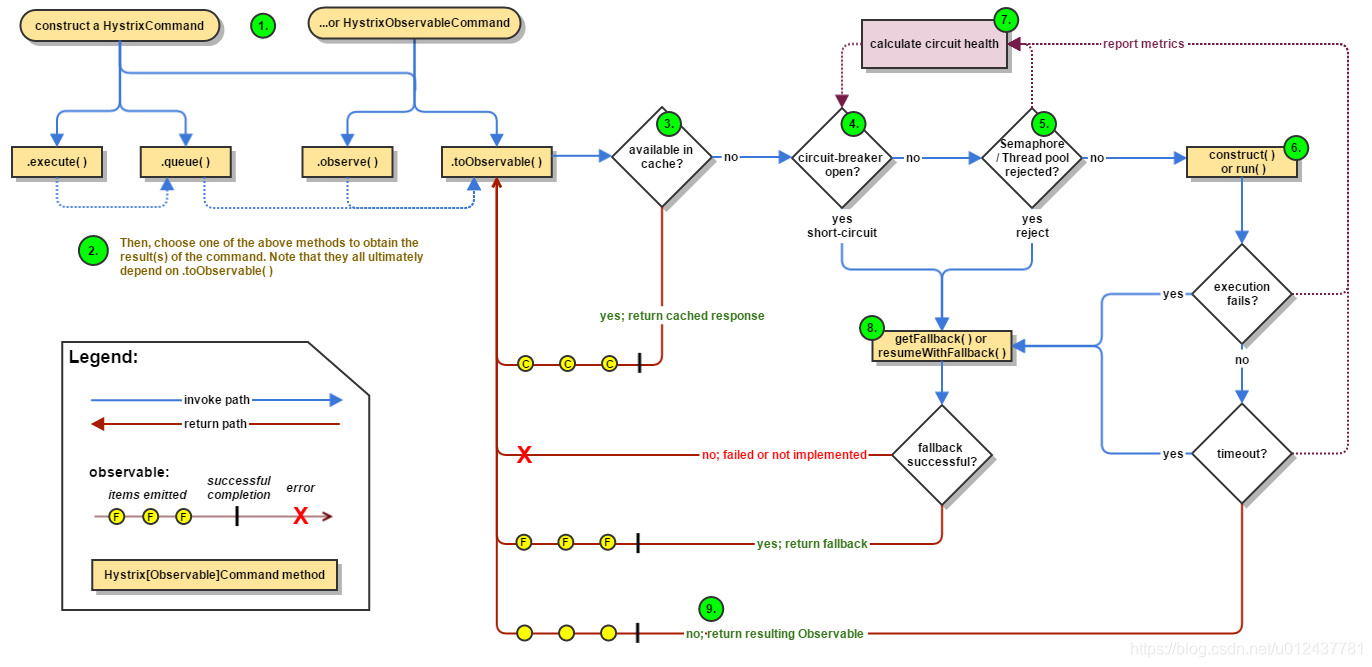
下面我们看一下Hystrix断路器的工作原理:
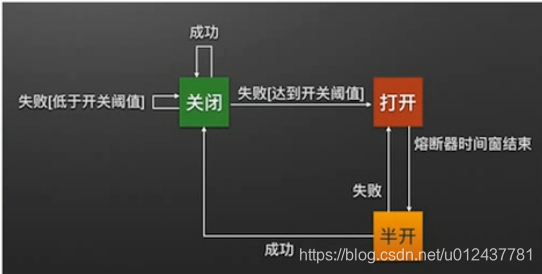
Hystrix的断路器总共有三种状态:
-
关闭:各个微服务节点正常可用是断路器是关闭的。
-
打开:当服务提供者节点非正常不可以时断路器打开,并对服务提供者提供消费降级服务(需自定义降级策略),简而言之就是提供一个FallBack。
-
半开:以第一张图为例,假设A服务不可用,并且断路器已打开,在接下来的一段时间内断路器将以半开的状态存在,所有来自C/D服务节点的请求都会被B服务以服务降级的方式响应并返回,即告诉C/D服务A服务不可用,同时B服务会用来自C/D服务中的小部分的请求流量去尝试访问A服务,若A服务一直不可用则B服务一直返回降级服务,若这小部分请求得到了A服务响应则B服务告知C/D服务可用,此时断路器关闭。从而回到所有服务节点都可用状态。
-
Hystrix的设计原则
- 资源隔离(线程池隔离和信号量隔离)机制:限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其它服务调用。
- 限流机制:限流机制主要是提前对各个类型的请求设置最高的QPS阈值,若高于设置的阈值则对该请求直接返回,不再调用后续资源。
- 熔断机制:当失败率达到阀值自动触发降级(如因网络故障、超时造成的失败率真高),熔断器触发的快速失败会进行快速恢复。
- 降级机制:超时降级、资源不足时(线程或信号量)降级 、运行异常降级等,降级后可以配合降级接口返回托底数据。
- 缓存支持:提供了请求缓存、请求合并实现
- 通过近实时的统计/监控/报警功能,来提高故障发现的速度
- 通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
-
Hystrix功能实现原理
- 通过HystrixCommand或者HystrixObservableCommand来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离
- 对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是99.5%的访问时间,但是一般我们可以自己设置一下
- 为每一个依赖服务维护一个独立的线程池,或者是semaphore,当线程池已满时,直接拒绝对这个服务的调用
- 对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计
- 如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
- 当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制
- 对属性和配置的修改提供近实时的支持
小结
- Hystrix是一个熔断机制,保证各个服务节点高可用。
- Hystrix提供了熔断、隔离、Fallback、cache、监控等功能。