大数据从获取到分析的各个阶段都可能会涉及到数据集的存储,考虑到大数据有别于传统数据集,因此大数据存储技术有别于传统存储技术。大数据一般通过分布式系统、NoSQL数据库等方式(还有云数据库)进行存储。同时涉及到以下几个新理念。
本篇summary主要围绕以下三方面内容:
- 大数据存储方案(分布式系统、NoSQL数据库系统);
- 分布与集群、数据分布的途径;
- 数据库设计时涉及到的原则与遵循的定理。
集群
将多台服务器集中在一起,每台服务器(节点)实现相同的业务。
因此每台服务器并不是缺一不可,集群的目的是缓解并发压力和单点故障转移问题。
例如:新浪网微博的访问量巨大,因此可以通过群集技术,几台服务器完成同一业务。当有业务访问时,选择负载较轻的服务器完成任务。

分布式
传统的项目中,各个业务模块存在于同一系统中,导致系统过于庞大,开发维护困难,无法针对单个模块进行优化以及水平扩展。因此考虑分布式系统:
将多台服务器集中在一起,分别实现总体中的不同业务。每台服务器都缺一不可,如果某台服务器故障,则网站部分功能缺失,或导致整体无法运行。因此可大幅度的提高效率、缓解服务器的访问存储压力。
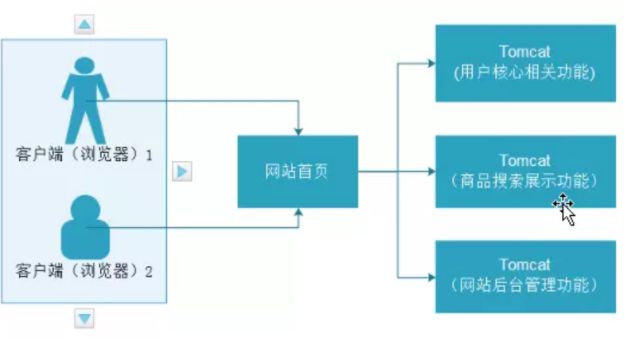
从上图中可看出:每个Web服务器(Tomcat)程序都负责一个网站中不同的功能,缺一不可。如果某台服务器故障,则对应的网站功能缺失,也可以导致其依赖功能甚至全部功能都不能够使用。
分布式与集群的关系、区别
关系:
分布式方便我们系统的维护和开发,但是不能解决并发问题,也无法保证我们的系统崩溃后的正常运转。
集群则恰好弥补了分布式的缺陷,多个服务器处理相同的业务,这可以改善系统的并发问题,同时保证系统崩溃后的正常运转。
因此,分布式和集群技术一般同时出现,密不可分。(分布式中的每一个节点,都可以做集群)
区别:
分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
【补充】例如:
如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行改任务需10小时。
- 采用分布式方案:提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。(这种工作模式的一个典型代表就是Hadoop的Map/Reduce分布式计算模型)
- 而采用集群方案:同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,10小时后,10个任务同时完成。整身来看,还是1小时内完成一个任务。
文件系统 & 分布式文件系统
文件系统——是一种存储和组织计算机数据的方法。
- 数据是以文件的形式存在,提供 Open、Read、Write、Seek、Close 等API 进行访问;
- 文件以树形目录进行组织,提供重命名(Rename)操作改变文件或者目录的位置。
分布式文件系统——允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
几种常见的分布式文件存储系统有GFS(Google分布式文件系统)、HDFS(Hadoop分布式文件系统)、TFS、Swift、Ceph等。
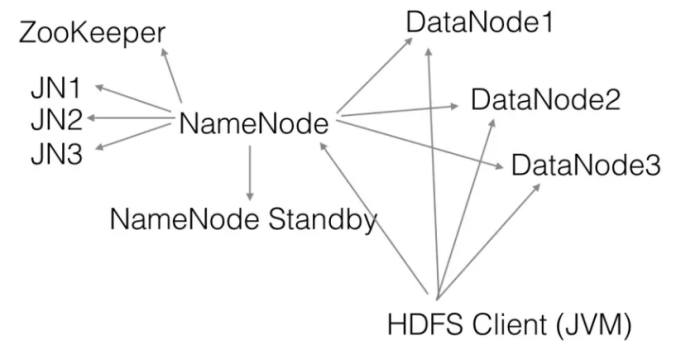
HDFS系统示意图
NoSQL(非关系型数据库)
NoSQL(Not Only SQL),意即"不仅仅是SQL"。NoSQL数据库可同时存储结构化、非结构化数据、半结构化数据。
相比于关系型数据库,非关系型数据库提出另一种理念:每一个样本(元组)根据需要可以有不同的字段,这样就不局限于固定的结构,调取数据时也更方便。可以减少一些时间和空间的开销。因此为了获取用户的不同信息,不需要像关系型数据库中,对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询,通过XQuery、SPARQL等查询语言完成查询过程。
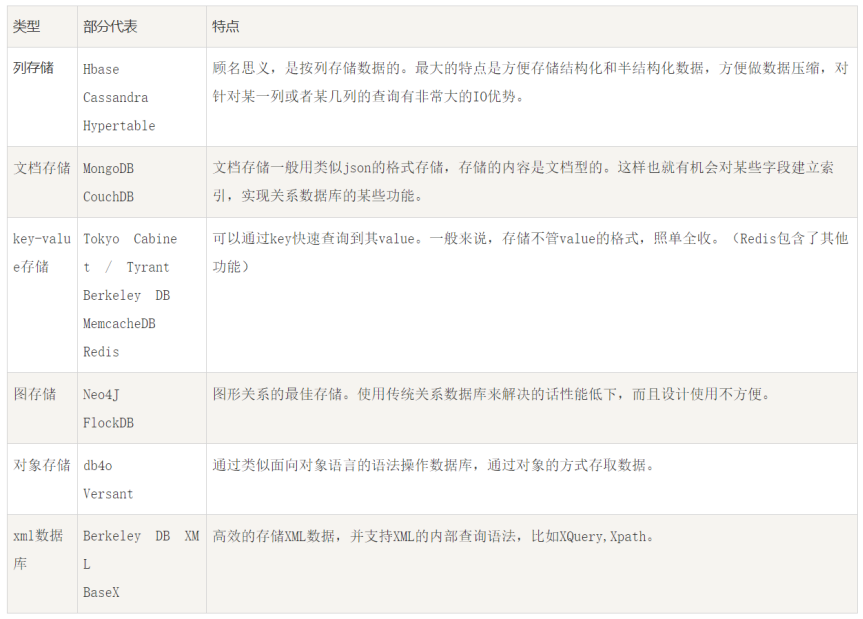
非关系型数据库有以下几种类型:
大数据集的数据量巨大,单机无法存储与处理如此规模的数据量,只能依靠大规模集群以进行存储和处理,因此系统需要具备可扩展性。
目前主流的大数据存储与计算系统往往采用横向扩展(Scale Out)的方式。因此,对于待存储处理的海量数据,需要用过数据分片将数据进行切分,并分配到各服务器中。
数据分布的两条途径:复制 & 分片
分布式NoSQL的两大特性:复制和分片。
数据分片与数据复制是紧密联系的两个概念。对于海量数据,可通过数据分片实现系统的水平扩展,通过数据复制保证数据的高可用性。

数据分片与数据复制的关系
分片(sharding/partition)——将数据的各个部分存放在不同的服务器/节点中,每个服务器/节点负责自身数据的读取与写入操作,以此实现横向扩展。
复制(replication)——将同一份数据拷贝到多个节点。分为主从复制master-slave方式、对等式复制peer-to-peer。
- 主从式复制:master节点用于存放权威数据,通常负责数据的更新,其余节点都叫做slave节点,复制操作就是让slave节点的数据与master节点的数据同步。适用于读请求密集的负载。
- 对等式复制:两个节点相互为各自的副本,也同时可以接受写入请求,丢失其中一个不影响整个数据库的访问。但同时接受写入请求,容易出现数据(写入)不一致问题,实际使用上,通常是只有一个节点接受写入请求,另一个master作为stand-by,在对方出现故障的时候自动承接写操作请求。
分片与复制可以组合,即同时采用主从复制与分片、对等复制与分片。
【补充】优缺点对比:
分片可以极大地提高读取性能,但对于要频繁写的应用,帮助不大。另外,分片对改善故障恢复能力并没有帮助,但是它减少了故障范围,只有访问这个节点的那些用户才会受影响,其余用户可以正常访问。虽然数据库缺失了一部分,但是还是其余部分还是可以正常运转。
复制除保证可用性之外,还可增加读操作的效率。(即客户端可以从多个备份数据中选择物理距离较近的进行读取,这既增加了读操作的并发性又可以提高单次读的读取效率。)
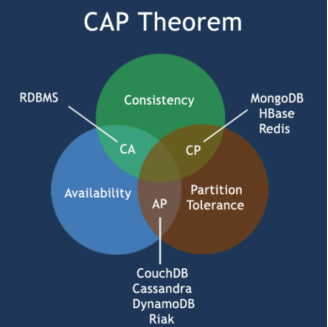
对于分布式数据库系统的设计过程,需遵循CAP定理:
CAP定理(布鲁尔定理)
布式数据库系统不可能同时满足以下三点,最多只能同时满足两个:
- 一致性(Consistency)——所有节点在同一时间具有相同的数据;
- 可用性(Availability)——保证每个请求不管成功或者失败都有响应;
- 分区容忍(Partition tolerance)——系统中任意信息的丢失或失败不会影响系统的继续运作。
因此,当代的分布式数据存储服务,均是针对各自服务的内容、性质取舍。
而NoSQL数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类。
关系型数据库的设计原则与事务管理遵循ACID规则:
ACID
事务(transaction),具有如下四个特性:
- A (Atomicity) 原子性——事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务失败,需要回滚。
- C (Consistency)一致性——数据库要一直处于一致的状态,事务的运行不会改变数据库原本的约束。
- I (Isolation) 独立性——并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。
- D (Durability) 持久性——是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使系统崩溃也不会丢失。
基于CAP定理演化而来BASE数据库设计原则:
BASE
包括:Basically Available(基本可用)、Soft state(软状态)、Eventually consistent(最终一致性)。
针对数据库系统要求的可用性、一致性,BASE放宽要求,形成基本可用和软状态/柔性事务。而一致性是最终目的。
ACID vs.BASE
