什么是I/O流
所谓I/O(Input/Output缩写),即指应用程序对数据在设备或者文件上的输入与输出。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象(java万物皆对象的特性)。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。数据流是一串连续不断的数据的集合,数据写入程序可以是一段一段地向数据流管道中写入数据 ,这些数据段会按先后顺序形成一个长的数据流,而从管道中读取数据的时候,数据会按照先进先出的原则,进行读取和展示。
Java IO流的层次结构
这个是面试官很喜欢考察的一个题目,就是问你java.IO包中类的结构和继承关系。其实,在整个Java.io包中最重要的就是5个类和一个接口。5个类指的是File、OutputStream、InputStream、Writer、Reader;一个接口指的是Serializable。按照类别可以分为下面三个层次:
- 流式部分――IO的主体部分,OutputStream、InputStream、Writer、Reader级其子类;
- 非流式部分――主要包含一些辅助流式部分的类,如:File类、RandomAccessFile类和FileDescriptor等类;
- 其他类–文件读取部分的与安全相关的类,如:SerializablePermission类,以及与本地操作系统相关的文件系统的类,如:FileSystem类和Win32FileSystem类和WinNTFileSystem类。
I/O流的分类
根据操作分为:输入流和输出流;根据类型分为:字节流和字符流。可以看一下大体的结构图:
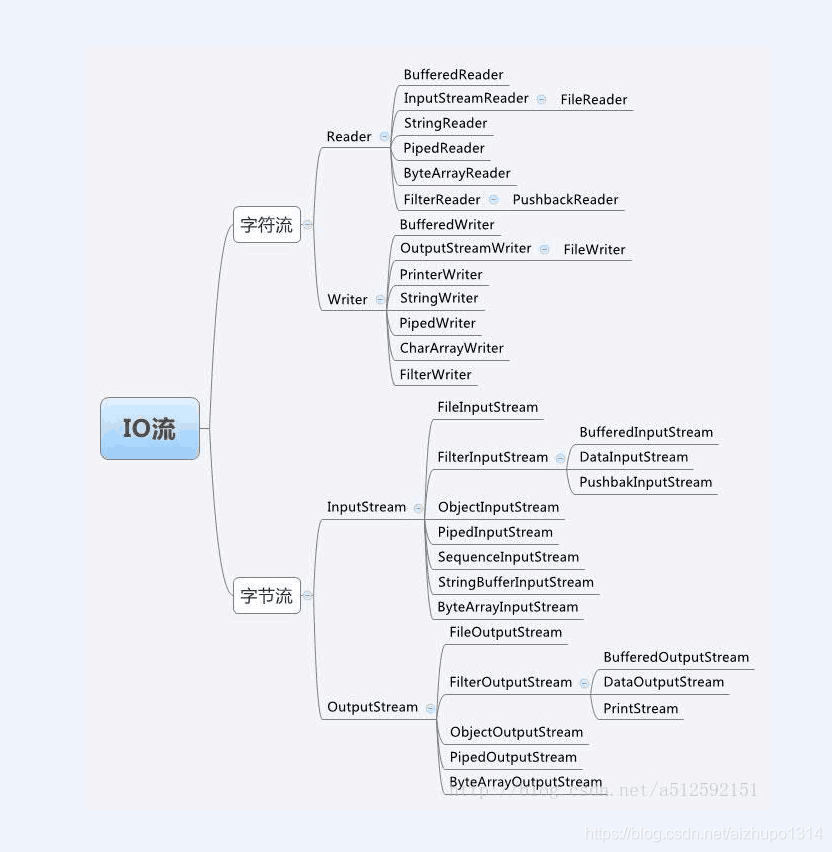
字节流和字符流的区别:
(1)读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
(2)处理对象不同:字节流能处理所有类型的数据(如图片、视频等),而字符流只能处理字符类型的数据。
(3)字节流在操作的时候本身是不会用到缓冲区的,是文件本身的直接操作的;而字符流在操作的时候下后是会用到缓冲区的,是通过缓冲区来操作文件,我们将在下面验证这一点。
字符流对于字符的文本的处理是一个很好的选择,但是字节流应用更加广泛,我们再项目中要结合具体的应用场景选择具体的I/O流进行处理。
输入字节流InputStream
InputStream 是所有的输入字节流的父类,它是一个抽象类。输入,其实就是讲数据读取到内存中,供程序使用。
ByteArrayInputStream、StringBufferInputStream、FileInputStream 是三种基本的介质流,它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。PipedInputStream 是从与其它线程共用的管道中读取数据,与Piped 相关的知识后续单独介绍。
ObjectInputStream 和所有FilterInputStream的子类都是装饰流(装饰器模式的主角)。意思是FileInputStream类可以通过一个String路径名创建一个对象,FileInputStream(String name)。而DataInputStream必须装饰一个类才能返回一个对象,DataInputStream(InputStream in)。
FilterInputStream可能大家看着都不熟,其实他就是缓冲流BufferedInputStream和BufferedOutputStream的父类
而这里面,最重要的就是FileInputStream,也是和我们打交道最多的,以这个作为分析对象,进行练习。

由上面,我们可以看出,他有三个构造函数,分别是传入一个String的文件路径,传入一个File对象和传入一个FileDescriptor对象。public FileInputStream(File file) throws FileNotFoundException,当找不到文件的时候,会抛一个文件找不到的异常。
File类比较简单,他的构造函数就是传入一个路径,获取这个文件对象,ublic File(String pathname),然后可以看他的一些属性,比如是否存在,是否可读,名称,路径,是否为文件夹等,这个大家可以去看一下,方法都比较简单。
File file = new File("D:" + File.separator + "a.txt");
InputStream inputStream = null;
//找不到文件会抛异常,所以try/catch
try {
//第一种方式:传入一个File对象
inputStream = new FileInputStream(file);
//第二种方式:传入文件路径
inputStream = new FileInputStream("D:\\"a.txt");
读取数据,public int read() throws IOException,调用的是private native int read0() throws IOException,返回的是读取的下一个字节,如果没有了则返回-1。另外一个是public int read(byte b[]) throws IOException,边读边往数组中写入数据,返回数组中数据的大小,读取完后下次读取返回-1;其实,这里就是使用了缓存,先把数据放在内存中的数组中。
这里,一个很重要的就是native修饰符,表示这个方法时调用本地的非java开发的方法,比如C语言的。一个native method方法可以返回任何java类型,包括非基本类型。其实,JDK底层有很多关于native的方法调用,毕竟对于操作系统的访问和操作,java是不擅长的,而调用c语言程序则很好的实现。而这个实现也很简单,大家可以去看一下,试着自己写一个。
我们在刚刚的a.txt文件中加入一些数据,然后,去读取并打印出来:
#read()方法,一个个字节读取
int n = 0;
StringBuilder sb = new StringBuilder();
while((n = inputStream.read()) != -1){
#注意这里一定要存byte字节,不然不能解析为字符
sb.append((byte)n);
}
System.out.print(sb.toString());
#第二种读取数据的方法,使用数组缓冲
inputStream = new FileInputStream("D:\\a.txt");
int n = 0;
byte[] bytes =new byte[1024];
StringBuilder sb = new StringBuilder();
while ((n = inputStream.read(bytes)) != -1) {
sb.append(new String(bytes, 0, n));
}
System.out.print(sb.toString());
输出字节流OutputStream
OutputStream是所有的输出字节流的父类,它是一个抽象类。输出,对于java程序来说,从程序写入文件或者设备叫做输出。
输出字节流对象和输入字节流对象是一一对应的,这里就不再进行过多分析和编写了。可以看到,构造方法和目录结构基本都类似:
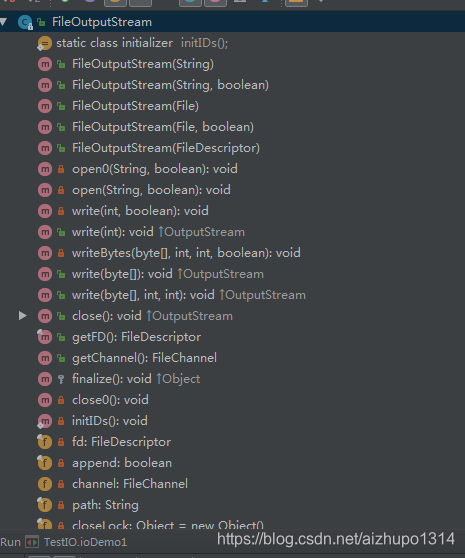
像文件或者设备上写数据,或者说从数据流中读数据的方法public void write(byte b[]) throws IOException,也是调用的native方法,通过c语言实现的,private native void writeBytes(byte b[], int off, int len, boolean append) throws IOException;,直接传入一个字节的数组,会将数据全部输出到对应文件和显示设备上。
当传入一个路径或者File对象创建FileOutputStream对象时,fileOutputStream = new FileOutputStream("E:\\a.txt");,如若没有文件,则会自动生成一个文件。
File file = new File("D:" + File.separator + "a.txt");
if (file.exists()) {
log.info(file.getAbsolutePath());
InputStream inputStream = null;
FileOutputStream fileOutputStream = null
try {
inputStream = new FileInputStream(file);
inputStream = new FileInputStream("D:\\a.txt");
new BufferedInputStream(inputStream);
int n = 0;
byte[] bytes =new byte[1024];
StringBuilder sb = new StringBuilder();
while ((n = inputStream.read(bytes)) != -1) {
sb.append(new String(bytes, 0, n));
}
System.out.print(sb.toString());
fileOutputStream = new FileOutputStream("E:\\a.txt");
fileOutputStream.write(sb.toString().getBytes());
/* while((n = inputStream.read()) != -1){
sb.append((char)n);
}*/
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
这样,相当于进行了文件的复制粘贴,我们的e盘下面就会生成一个a.txt的文件,内容和d盘下的一样。
缓冲流
首先,我们要知道JDK提供缓冲流是为了什么?其实,缓冲流是针对于字节流处理较麻烦,同时,他是直接操作数据源,不使用缓冲区的,而我们知道,涉及磁盘的IO操作相比内存的操作要慢很多。所以,JDK提供了缓冲流的实现,这里使用了装饰模式,他的构造函数就是传入一个对应的字节流,进而拥有你所有的属性和方法,并可以增加自己的实现。
BufferedInputStream和BufferedOutputStream这两个类分别是FilterInputStream和FilterOutputStream的子类,作为装饰器子类,使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
同时正因为它们实现了缓冲功能,所以要注意在使用BufferedOutputStream写完数据后,要调用flush()方法或close()方法,强行将缓冲区中的数据写出。否则可能无法写出数据。与之相似还BufferedReader和BufferedWriter两个类。
其实,缓冲流的底层实现原理很简单,内部自己封装了一个固定长度的byte数组,读取数据的时候,先把数据放到数组中,也就是内存中,等到数据满了,再刷新到磁盘中。
private static int DEFAULT_BUFFER_SIZE = 8192;
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8;
/**
* The internal buffer array where the data is stored. When necessary,
* it may be replaced by another array of
* a different size.
*/
protected volatile byte buf[];
- BufferedInputStream有两个构造方法,
BufferedInputStream(InputStream in),这个是使用默认大小的数组,BufferedInputStream(InputStream in, int size),这个是使用指定大小的容量的数组。内部方法和字节流一样,主要是read方法。关于角标和重置指针之后详细讲。
int available(); //返回底层流对应的源中有效可供读取的字节数
void close(); //关闭此流、释放与此流有关的所有资源
boolean markSupport(); //查看此流是否支持mark
void mark(int readLimit); //标记当前buf中读取下一个字节的下标
int read(); //读取buf中下一个字节
int read(byte[] b, int off, int len); //读取buf中下一个字节
void reset(); //重置最后一次调用mark标记的buf中的位子
- BufferedOutputStream和BufferedInputStream类似,也是有两个构造方法,
BufferedOutputStream(OutputStream out)和BufferedOutputStream(OutputStream out, int size),也是初始化数组容量的区别,而其内部方法和输出字节流也类似,主要就是调用write方法。但是,一定要注意,他是缓冲流,不会自己主动刷新到文件中,必须我们手动操作,调用close或者flush方法刷新数据到磁盘上。
void flush(); 将写入bos中的数据flush到out指定的目的地中、注意这里不是flush到out中、因为其内部又调用了out.flush()
write(byte b); 将一个字节写入到buf中
write(byte[] b, int off, int len); 将数组b的指定长度的数据写入buf中
所以,使用缓冲流,我们复制文件的代码可以这样写:
@Test
public void testBufferIoDemo1() {
InputStream inputStream = null ;
BufferedInputStream bufferedInputStream = null ;
OutputStream outputStream = null ;
BufferedOutputStream bufferedOutputStream = null ;
try {
inputStream = new FileInputStream( "D:\\a.txt" ) ;
bufferedInputStream = new BufferedInputStream( inputStream ) ;
outputStream = new FileOutputStream( "E:\\b.txt" ) ;
bufferedOutputStream = new BufferedOutputStream( outputStream ) ;
byte[] b=new byte[1024]; //代表一次最多读取1KB的内容
int length = 0 ; //代表实际读取的字节数
while( (length = bufferedInputStream.read( b ) )!= -1 ){
//length 代表实际读取的字节数
bufferedOutputStream.write(b, 0, length );
}
//缓冲区的内容写入到文件
bufferedOutputStream.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}finally {
if( bufferedOutputStream != null ){
try {
bufferedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if( bufferedInputStream != null){
try {
bufferedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if( inputStream != null ){
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if ( outputStream != null ) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
至此,字节流和缓冲流基本有了一个大概的了解,程序中的使用和源码也有了一定的研究,之后,我会针对读取数据的pos,也就是指针和reset,mark这些方法做一些学习和分享。然后就是分享一下字符流的使用和注意事项。