一、概述
Java 类库定义了许多类专门负责各种方式的输入/输出,这些类都被放在 java.io 包中。它具有4个最基本的类,如下所示:
- InputStream:字节输入流,它的子类都含有
read()方法用于读入字节数据。 - OutputStream:字节输出流,它的子类都含有
write()方法用于写出字节数据。 - Reader:字符输入流,它的子类都含有
read()方法用于读入字符数据。 - Writer:字符输出流,它的子类都含有
write()方法用于写出字符数据。
这 4 个类均为抽象类,它们各自都有许多继承自它们的子类用以提供不同的功能,在使用过程中我们往往借助多态的特性来使用这些类及其它们的子类。
在 Java 中,对于待处理的数据我们将其抽象成了流(Stream),它屏蔽了实际的 I/O 设备中处理数据的细节,对于我们用户来说,就好像一条水流流入(InputStream)或流出(OutputStream)程序,这样就能使得我们更加方便地处理数据。
接下来我们就来看到这些类的继承体系结构,如下图所示:
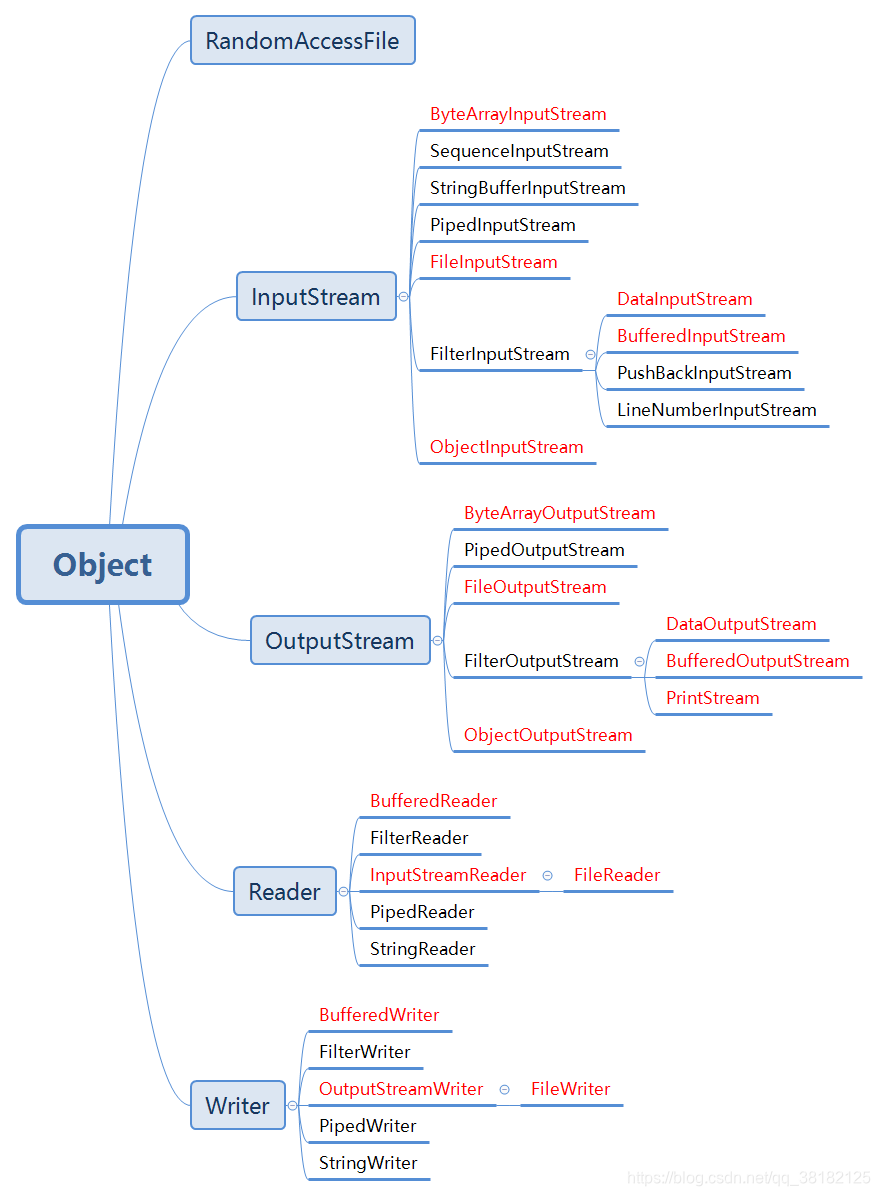
其中红色字体的类是在日常开发中使用较为频繁的类,也是我们接下来会介绍的类。除了前面所说的四个类外,我们还注意到一个类 RandomAccessFile,这个类独立于这 4 个类之外,提供了随机访问文件的方法,后面我们也会对其进行介绍。
需要特别注意一点的是:虽然上图所展示出来的类特别多,但是并不复杂,继承自同一父类的方法,它们的使用大多是大同小异的,所以只要学习了其使用的方式和思想,对于未学过的子类只需要翻阅官方文档也能快速上手。
二、InputStream & OutputStream
接下来我们就先从整体上来了解下两个基本的抽象类:InputStream 和 OutputStream。它们分别用于处理输入字节流和输出字节流,首先来看到 InputStream 及其提供的基本方法:
1. InputStream
InputStream 用于处理字节输入流,它主要提供了以下核心方法,如下表所示:
| 方法 | 说明 |
|---|---|
| read() | 从输入流读取数据的下一个字节,它的返回值即下一个字节的值,如果不存在下一个字节则返回-1 |
| read(byte[] b) | 从输入流读取一些字节数,并将它们存储到缓冲区b。它的返回值为读取的输入流字节数长度,如果已到达文件末尾则返回-1 |
| read(byte[] b, int off, int len) | 带有偏移量off和读取长度len的读取字节数的方法,数据会存储到缓冲区b,返回值为读取的字节数长度 |
| close() | 关闭此输入流并释放与此流相关联的任何系统资源。 |
这三个方法读取字节的方法我们可以用搬家的例子来类比:
read()方法就是蚂蚁搬家的方式,一个字节一个字节地读取。read(byte[] b)和read(byte[] b, int off, int len)方法就是卡车搬家的方式,将字节按数组的方式一组一组地读入。
接下来我们通过 3 个例子来展示这三个方法的使用:
read()
在这里及下面的例子中,我们会使用 FileInputStream 类来读入文件的数据。它是 InputStream 的子类,专门用于从文件中读入数据,后面我们会详细介绍它的使用,这里先了解即可。然后我们在电脑的桌面上创建一个 demo.txt 的文本文件,如下所示:

接着我们通过 Java 代码将其数据读入,打印输出,代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/demo.txt");
InputStream in = new FileInputStream(file);
// 读取的数据
int b = -1;
// 循环读取数据,直到到达文件末尾
while ((b = in.read()) != -1){
System.out.println((char) b);
}
}
}
需要注意的是 FileInputStream 的构造方法以及 read 方法均会抛出异常,这里我们将其直接抛给 main 方法来处理。输出结果如下所示:
T
o
b
e
o
r
n
o
t
t
o
b
e
可以看到确实是一个字节一个字节地输出的,在程序中我们将接收到的字节数直接强转成了字符输出。注意空格也是算作一个字符的。
read(byte[] b)
read(byte[] b) 方法我们前面说过是卡车搬家的方式,我们需要在程序中预先设置一个缓冲字节数组组,数组的长度就是缓冲区的大小。当缓冲区大于输入流长度时,输入流就相当于一次性被读入了字节数组;否则的话输入流就会被分段读入,方法的返回值即为读入的字节长度。当到达文件末尾时,返回值为-1。示例代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/demo.txt");
InputStream in = new FileInputStream(file);
// 设置缓冲区大小为 4byte
byte[] buffer = new byte[4];
int len = -1;
while ((len = in.read(buffer)) != -1){
System.out.println(new String(buffer));
}
}
}
运行结果如下:
To b
e or
not
to
be
由于我们设置的缓冲区长度为4个字节,所以每次循环都会读出4个字节的数据存储到 buffer 数组中。在最后一次读取时,只剩下两个字节的数据未读取,所以 buffer 只有前两个元素是有读取的数据的。
read(byte[] b, int off, int len)
该 read() 方法同样也是读取一组字节数缓存到 b 中,不同的是它可以指定偏移值 off 和 读取的长度 len。其中 off 为读入的数据在 b 中的起始偏移量,而 len 则是每次指定读入的字节数大小,示例代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/demo.txt");
InputStream in = new FileInputStream(file);
// 指定缓存大小为1kb
byte[] buffer = new byte[1024];
int len = -1, offset = 0;
while ((len = in.read(buffer, offset, 4)) != -1){
offset += len;
}
System.out.println(new String(buffer));
}
}
运行结果如下所示:
To be or not to be
以上就是关于 3 个 read() 方法的使用,接下来我们来看到 OutputStream 及其核心方法。
2. OutputStream
OutputStream 顾名思义就是用于处理输出流的类了,它有如下核心方法:
| 方法 | 说明 |
|---|---|
| write(int b) | 将指定的字节写入此输出流 |
| write(byte[] b) | 将b.length字节从指定的字节数组写入此输出流。 |
| write(byte[] b, int off, int len) | 从指定的字节数组写入 len个字节,从偏移off开始输出到此输出流。 |
| close() | 关闭此输出流并释放与此流相关联的任何系统资源 |
| flush() | 刷新此输出流并强制任何缓冲的输出字节被写出。 |
可以看到作为和 InputStream 相对应的类,OutputStream 的核心方法和 InputStream 非常类似,这里要特别说明一下 flush() 方法。
flush()
我们都知道,频繁地读写是代码低效的原因之一,所以为了提高代码的效率,在 OutputStream 中系统会设置一个缓冲区,当缓冲区填满时一次性将缓冲区的内容输出到目标区域,这样就可以防止频繁的写操作从而提高程序的效率。而如果我们需要每次写出都立即得到结果,那么我们就可以调用 flush() 方法强制将缓冲中的输出字节写出,而不是等待缓冲区满之后再写出。
write()
由于 write() 相关方法的使用和 InputStream 中的 read() 方法的使用非常类似,这里就只举一个例子来介绍 write 方法的使用。我们这里就以写一句话输出到文本文件中为例进行示例:
public class IODemo01 {
public static void main(String[] args) throws IOException {
// 输出的文本文件路径
File file = new File("C:/Users/Marck/Desktop/demo1.txt");
OutputStream out = new FileOutputStream(file);
// 要输出的文本内容
String outToTxt = "We have no choose but to win";
// 将字符串转化成字节数组
byte[] data = outToTxt.getBytes();
// 将数据写出
out.write(data);
}
}
运行该段代码之后,我们就能够在电脑桌面上看到一个名为 demo1.txt 的文本,文本中的文字就是我们想要写入的内容。需要注意的是 demo1.txt 文件如果原先不存在的话,那么程序会创建该文件。
三、Reader & Writer
接下来我们来从整体上介绍一下 Reader 和 Writer。这两个抽象类及其衍生的子类都是用于处理纯文本数据使用的。实际上 InputStream 和 OutputStream 同样可以处理文本数据,那么为什么还需要 Reader 和 Writer 呢?这就要涉及到字符集和字符编码的相关知识了。
1. 字符集和字符编码
我们都知道,计算机所存储的数据都是二进制数据,例如我们的一个文本文件,它同样是一堆二进制数据。但事实上我们打开文本文件之后所看到的并不是 0 和 1,而是有意义的字符。也就是说,计算机内部通过某种机制将二级制数和文本之间进行了转化。从二进制数据到字符的转化过程,我们称之为解码;从字符到二进制数据我们称之为编码。
多个字符的集合我们就称之为字符集,字符集种类非常多,有 ASCII字符集、Unicode字符集等。不同的字符集包含有不同的字符个数,例如 ASCII字符集含有128个字符,而 Unicode字符集则包含了英文、中文等字符。
因为具有不同的字符集,为了能让字符集被计算机准确地处理,不同的字符集就会采用不同的字符编码格式。例如 ASCII字符集采用的是 ASCII编码,在我们上面的例子中,我们将数字直接强转成字符的方式用的正是 ASCII解码的方式。但是在上面的例子中文本中的文字均是英文,所以强转不会出现乱码,如果我们的文本中出现中文的话,就会出现乱码的现象,因为 ASCII字符集中不存在中文字符,所以无法进行正确的解码。
回到上面为什么在 InputStream 和 OutputStream 已存在的情况下还要存在 Reader 和 Writer 的问题。理由如下:
Reader和Writer可以直接操作字符或字符串,而不必先将其转化为字节的形式;Reader和Writer的内部提供了相关的子类,可以指定字符编码格式,而InputStream和OutputStream处理非 ASCII码的字符会显得很麻烦。
以上是对字符和字符编码的简略介绍,想要详细了解的朋友可以自行搜索相关书籍进行了解,接下来我们就来介绍正文:Reader 和 Writer。
2. Reader
Reader 类用于读取文本数据,它提供了如下核心方法:
| 方法 | 说明 |
|---|---|
| read() | 读一个字符。返回值表示读取的字符数,返回-1则表示到达流的尾部 |
| read(char[] cbuf) | 将字符读入字符数组。返回值表示读取的字符数,返回-1则表示到达流的尾部 |
| read(char[] cbuf, int off, int len) | 将字符读入字符数组的一部分。返回值表示读取的字符数,返回-1则表示到达流的尾部 |
| close() | 关闭流并释放与之相关联的任何系统资源。 |
可以看到 Reader 所提供的核心方法和 InputStream 其实是非常相似的,只不过由于 Reader 是专门用于处理字符的类,所以它的参数均为 char 类型,下面对其方法进行举例。
read()
这里我们只以 read(char[] cbuf) 方法进行举例,其它方法与前面例子的使用非常相似,这里不再赘述。这里我们仍然以读取文本文件为例,将读取到的字符打印出来,不同的是这次我们使用的是中文字符,文本内容如下所示:

示例代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/play_ball.txt");
Reader reader = new FileReader(file);
// 字符缓冲区长度为4
char[] buffer = new char[4];
int len = -1;
while ((len = reader.read(buffer)) != -1){
System.out.println(new String(buffer, 0, len));
}
reader.close();
}
}
运行代码,结果如下所示:
蔡徐坤出
来打球!
需要注意的是我们的文本编码格式必须和我们的工程编码格式保持一致,如下所示:
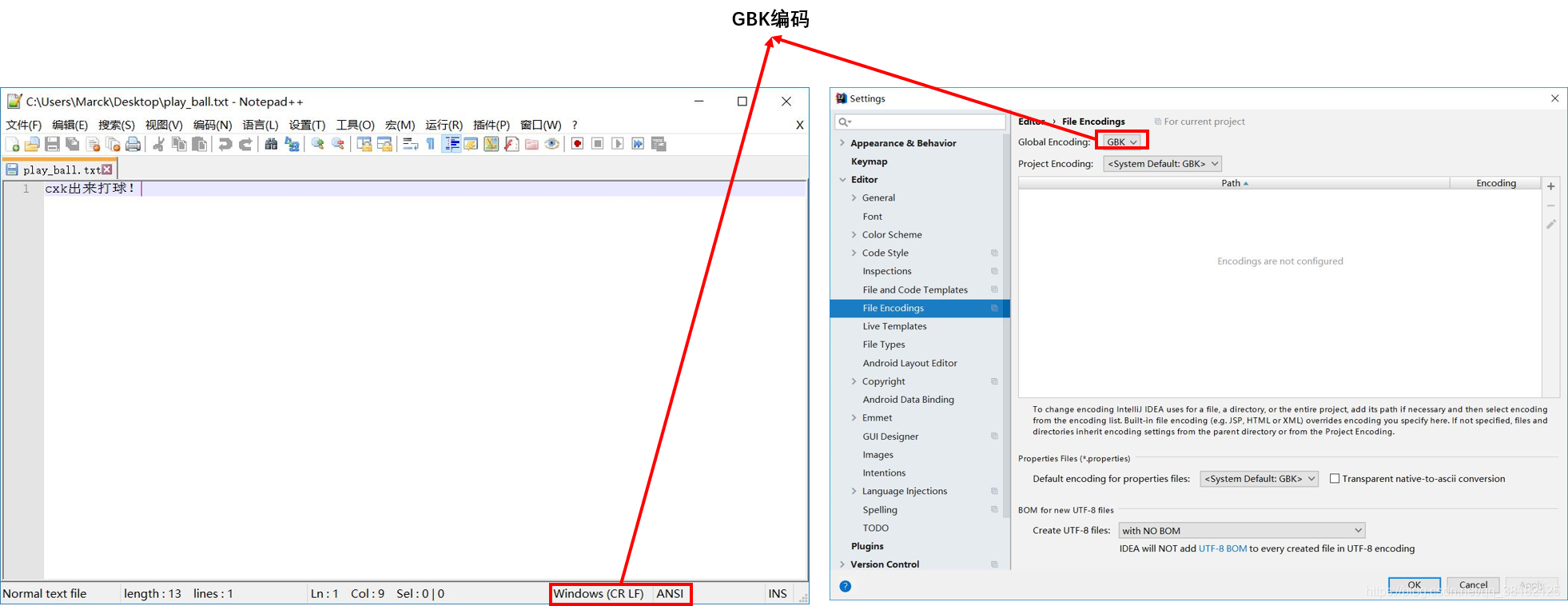
例如这里笔者工程所使用的编码为GBK编码,而 play_ball.txt 文件采用的是ANSI标准编码,在我们的系统中即为 GBK 编码,所以我们能够正确地输出文本信息,如果工程采用的编码方式与文本文件不一致,例如采用 UTF-8 进行编码,那么就会出现乱码,如下所示:
锘胯敗寰
愬潳鍑烘
潵鎵撶悆
锛
?
遇到这种编码格式与工程不一致的情况,我们需要手动指定字节解码格式。但是 FileReader 不支持解码格式设置,所以我们应当使用 FileReader 的父类 InputStreamReader,通过明确指定解码格式的方式来得到正确的字符,代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/play_ball.txt");
InputStream is = new FileInputStream(file);
// 指定解码格式为UTF-8
Reader reader = new InputStreamReader(is, "UTF-8");
// 字符缓冲区长度为4
char[] buffer = new char[4];
int len = -1;
while ((len = reader.read(buffer)) != -1){
System.out.println(new String(buffer, 0, len));
}
reader.close();
}
}
通过这种方式我们依然能够得到正确的字符。FileReader 和 InputStreamReader 均会在后面的文章进行详细的介绍,这里我们先初步了解即可。
3. Writer
Writer 类用于写出文本数据,它提供了如下核心方法:
| 方法 | 说明 |
|---|---|
| append(char c) | 将指定的字符附加到此Writer对象 |
| append(CharSequence csq) | 将指定的字符序列附加到此Writer对象 |
| write(char[] cbuf) | 写入一个字符数组。 |
| write(char[] cbuf, int off, int len) | 写入字符数组的一部分。 |
| write(String str) | 写一个字符串 |
| write(String str, int off, int len) | 写一个字符串的一部分 |
| flush() | 刷新流 |
| close() | 关闭流及其相关的系统资源 |
write()
同样的,这里我们只演示 write(String str) 的使用,其它的方法请大家自行模仿前面的示例进行摸索。这里我们将一段文字写出到文本文件 demow.txt 中,代码如下所示:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/demo2.txt");
Writer writer = new FileWriter(file);
String outToTxt = "你打球就像蔡徐坤";
writer.write(outToTxt);
writer.flush(); // 刷新流
writer.close(); // 关闭流
}
}
运行之后我们就会发现桌面上出现了 demo2.txt 文件,里面的文本信息就是我们 outToTxt 当中的内容,并且文本中字符的编码格式与工程的编码格式保持一致。可以看出 Writer 可以直接操作字符串或字符,相比起 OutputStream 来说使用更为简单。同样的,如果我们需要为字符指定编码格式,我们就应当使用 FileWriter 的父类 OutputStreamWriter。
append()
append() 方法也是写出字符或字符串的方法,它的用法和 StringBuider#append() 非常类似,下面通过一个例子来展示它的使用:
public class IODemo01 {
public static void main(String[] args) throws IOException {
File file = new File("C:/Users/Marck/Desktop/demo2.txt");
Writer writer = new FileWriter(file);
String text1 = "你打球就像蔡徐坤";
String text2 = ",你打野更像蔡徐坤!";
writer.append(text1).append(text2);
writer.flush(); // 刷新流
writer.close(); // 关闭流
}
}
输出结果如下:

可以看到 append() 方法采用的是追加字符或字符串的形式,和 StringBuilder#append() 的使用几乎是一模一样的。
四、补充部分
在这一部分我们会介绍 IO 相关的注意事项及其使用步骤。
1. 及时地关闭资源
通过上面的介绍,我们很容易发现 InputStream 、OutputStream、Reader 和 Writer 所提供的核心方法都存在 close(),它用于关闭我们的输入/输出流以及释放相关的系统资源。
在前面的读写文件的例子中,我们就使用了操作系统的相关资源。Java 程序是靠虚拟机来运行的,但是虚拟机并没有读写文件的权限,所以虚拟机实际上所做是的操作系统来读写文件,所以在使用完相关的输入/输出流之后,我们应当及时地调用 close() 方法,关闭相应的流和资源,避免造成不必要的资源浪费。
但在前面的部分示例代码中我们并没有调用 close() 方法,那么相关的系统资源释放了吗?答案是肯定的,系统资源的释放除了调用 close() 方法主动释放之外,还会在程序运行结束时释放。前面示例的代码都很短,所以不会造成差错,但在实际使用中,为了保证代码的健壮性,我们应当在合适的时机调用 close() 方法及时释放相关资源,避免不必要的差错。
2. 输入/输出的使用步骤
根据上面的相关描述,我们可以总结出输入/输出流的使用步骤:
- 创建源。无论是输入流还是输出流,我们首先都需要明确这些流是来源于何处的,即找到它的源头。
- 选择流。选择合适的流对象对数据进行处理,例如纯文本的我们可以选择字符流,而图片、视频等文件类型的则选择字节流。
- 操作。根据我们的需求对流进行相关的操作。
- 关闭资源。在操作结束之后,我们应当及时地释放系统资源。
接下来我们通过一个复制文件例子来展示上面的步骤。接下来我们根据上面的步骤逐步分析复制文件每一步所做的事。
- 创建源。由于是复制文件,所以我们需要两个源,一个是待复制(输入流)的文件,一个是复制文件(输出流)。
- 选择流。由于我们复制的对象是文件,所以选择的流是文件字节流
FileInputStream和FileOutputStream。 - 操作。我们采用的方式是将输入流字节数据存储在一个字节数组中,然后将该字节数组作为输出流的写出数据写出,从而达到复制的效果。
- 关闭资源。在操作结束之后,及时地释放系统资源。
下面我们就将上述步骤封装成一个静态方法,方法名字为 copy,方法的参数为待复制的文件以及复制文件路径,如下所示:
public class FileUtils {
public static void main(String[] args) throws FileNotFoundException {
File src = new File("C:/Users/Marck/Desktop/demo.png");
File dest = new File("C:/Users/Marck/Desktop/demo-copy.png");
copy(src, dest);
}
/**
* 拷贝的工具类方法
* @param src 源文件
* @param dest 复制文件
*/
public static void copy(File src, File dest){
// 如果源文件不存在或者文件长度为0,直接结束该方法
if (src == null || src.length() == 0){
return;
}
InputStream is = null;
OutputStream os = null;
try {
// 2. 选择合适的流
is = new FileInputStream(src);
os = new FileOutputStream(dest);
// 3. 操作
byte[] buffer = new byte[1024];
int len = -1;
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
os.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 关闭资源
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
这里需要特别注意一点的是释放资源的操作一定要放在 finally 块中进行,这是为了避免在运行过程中发生异常时无法正确释放资源的情况。而放在 finally 语句块中,无论是否抛出异常,最终都能够释放资源。
3. 释放资源的三种方式
释放资源有三种方式可以使用,第一种方式就是上述直接在 finally 块中进行资源释放操作,除此之外我们还有下列两种比较简略的方式:
- 封装释放资源的方法,使用可变参数提高灵活性;
- 采用 try…with…release 的方式。
封装相关方法
查看 InputStream、OutputStream、Reader 和 Writer 的源码,可以发现它们都实现了 Closeable 接口,而这个接口内部只定义了一个方法,即 close()。所以我们可以封装一个方法,方法的参数类型我们定义为 Closeable,这样就可以为上面 4 个基本的类及其子类所使用了,并且为了提高其灵活性,我们采用可变参数的形式设置参数,代码如下所示:
/**
* 释放IO资源的工具类方法
* @param ios 要关闭的IO流
*/
public static void close(Closeable... ios){
for (Closeable io : ios){
try {
if (io != null){
io.close();
}
} catch (IOException e){
e.printStackTrace();
}
}
}
封装好该方法之后,我们就只需要在 finally 语句块中调用该方法即可,例如上述 copy 方法可变为如下所示:
public static void copy(File src, File dest){
......
try {
......
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 关闭资源
close(is, os);
}
}
try…with…release
除了上述方法之外,在 jdk1.7 及其之后的版本,Java 还提供了一种更为简洁的方式来释放相关的资源。上面的 copy 方法代码可修改如下:
public static void copy(File src, File dest){
// 如果源文件不存在或者文件长度为0,直接结束该方法
if (src == null || src.length() == 0){
return;
}
try (InputStream is = new FileInputStream(src);
OutputStream os = new FileOutputStream(dest)){
// 3. 操作
byte[] buffer = new byte[1024];
int len = -1;
while ((len = is.read(buffer)) != -1){
os.write(buffer, 0, len);
}
os.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
这种方式就是直接将在执行完毕后要释放资源的对象在关键字 try 后面的括号进行初始化,这样子做之后系统会在 try/catch 块执行结束之后自动地释放资源,而不需要为其设置 finally 块。
五、总结
本篇文章主要从整体上对 IO 操作中的四大基本类:InputStream、OutputStream、Reader 以及 Writer 从整体上进行介绍。
InputStream和OutputStream为字节输入/输出流,它们可以处理所有的文件,核心方法为read和write,分别用于读入和写出字节数据;Reader和Writer为字符输入/输出流,它们主要用于处理文本数据,它们可以直接对字符和字符串进行操作,核心方法同样为read和write;- 输出流有一个刷新的方法
flush(),用于将缓冲区中的数据强制写出,如果我们需要在写出操作后立即看到写出的数据,即可调用该方法; - IO 的四大基本类均有
close()方法,在相关操作完成之后我们要注意及时地释放系统资源,避免造成对系统资源不必要的浪费;
希望这篇文章对您有所帮助~