Java基础–I/O流知识总结
文章目录
- Java基础--I/O流知识总结
- 引言
- Java中IO的结构体系
- 字节流(InputStream/OutputStream)
- FileInputStream/FileOutputStream
- ByteArrayInputStream/ByteArrayOutputStream
- PipedOutputStream/PipedInputStream
- BufferedInputStream/BufferedOutputStream
- DataOutputStream/DataInputStream
- ObjectInputStream/ObjectOutputStream
- PushbackInputStream
- PrintStream
- SequenceInputStream
- 字符流(Reader/Writer)
引言
I/O(输入/输出)应该算是所有程序都必需的一部分,使用输入机制,允许程序读取外部的数据资源、接收用户输入;使用输出机制,允许程序记录允许状态,并将数据输出到外部设备。Java的IO是通过java.io包下的类和接口来实现的,其下主要包括输入、输出两种IO流,根据流中操作的数据单元的不同又分为字节流(8位的字节)和字符流(16位的字符)。
Java中IO的结构体系
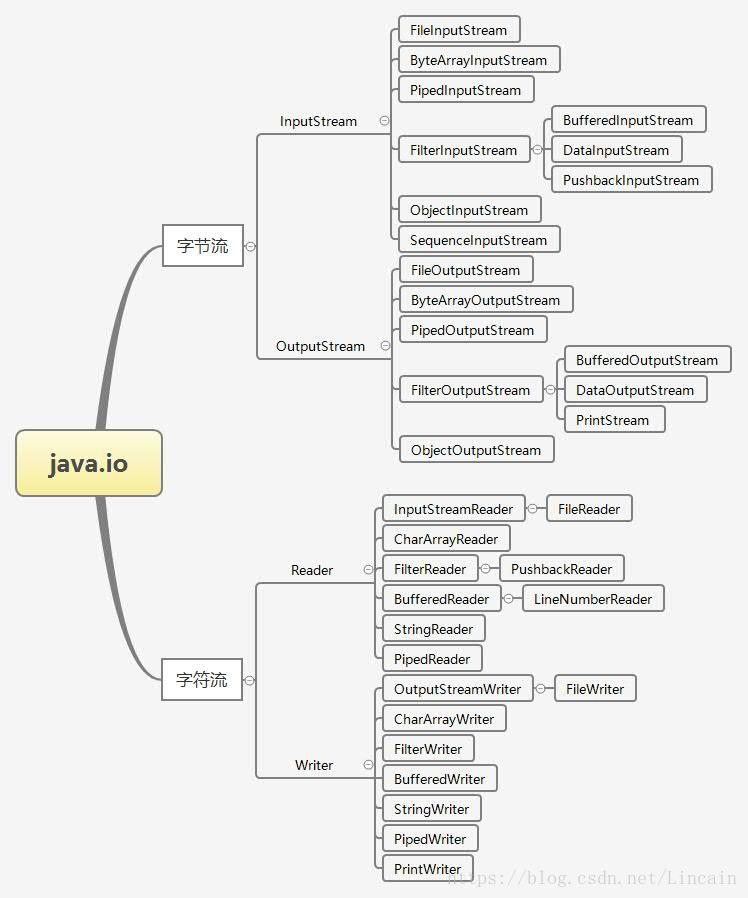
字节流(InputStream/OutputStream)
首先来看一看字节输入流InpuStream,此抽象类是表示字节输入流的所有类的超类,它有如下三个基本方法。
int read():从输入流中读取单个字节,返回所读取的世界数据。int read(byte[] b):从输入流中最多读取b.length个字节的数据,并将其存储在缓冲区数组b中,返回实际读取的字节数。int read(byte[] b,int off,int len):将输入流中最多len个数据字节读入缓冲区数组b中,off为数组 b 中将写入数据的初始偏移量,返回实际读取的字节数。
字节输出流OutputStream,此抽象类是表示字节输出流的所有类的超类,它有如下三个基本方法。
void write(int c):将指定的字节写入此输出流。void write(byte[] buf):将b.length个字节从指定的byte数组写入此输出流。void write(byte[] buf,int off,int len):将指定byte数组中从偏移量off开始的len个字节写入此输出流。
接下来逐个介绍字节流的各个子类。
FileInputStream/FileOutputStream
这两个类直接继承自InputStream和OutputStream,可实现对文件的读取和数据写入。如下代码即可实现对文件的复制操作。
package cn.lincain.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class FileStreamTest {
public static void main(String[] args) {
try (
// 创建一个字节输入流
FileInputStream fis = new FileInputStream("FileStreamTest .java");
// 创建一个字节输出流
FileOutputStream fos = new FileOutputStream("copy.txt"))
{
int hasRead = 0;
// 从ByteStreamTest.java文件读取数据到流中
while ((hasRead = fis.read()) != -1) {
// 将数据写入到指定的文件中
fos.write(hasRead);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
我们将输入流比作是一个水管,里面装的水就是文件的数据,read()和write(int c)方法相当于每次从中取一滴水,数据量不大的时候,效率还可以,但是当数据量非常大时,读取的效率就很低。
下面我们采用int read(byte[] b)和void write(byte[] b,int off,int len)方法来示范文件复制的效果。
package cn.lincain.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class FileStreamTest {
public static void main(String[] args) {
try (
// 创建一个字节输入流
FileInputStream fis = new FileInputStream("FileStreamTest .java");
// 创建一个字节输出流
FileOutputStream fos = new FileOutputStream("copy.txt"))
{
long start = System.currentTimeMillis();
byte[] buff = new byte[12];
int hasRead = 0;
// 从ByteStreamTest.java文件读取数据到流中
while ((hasRead = fis.read(buff)) > 0) {
// 将数据写入到指定的文件中
fos.write(buff, 0, hasRead);
}
long end = System.currentTimeMillis();
System.out.println("文件复制总共花了:" + (end - start) + "ms");
} catch (Exception e) {
e.printStackTrace();
}
}
}
同样的案例,当我们采用数组作为read()、write()的参数时,该数组就相当如一个“水桶”,每次将水桶的水接满了或者水管的水接完了才输出,这样就极大的提高了读取效率,其中第一个程序复制文件消耗了21ms,而第二个程序则只消耗了1ms,由此可见二者的差距。
后面对其他字节流流我们都采取就用缓冲效果的方法进行示范。
ByteArrayInputStream/ByteArrayOutputStream
以上两个字节流从字面意思可知,就是字节数组与字节输入输出流之间的各种转换。
ByteArrayInputStream的构造方法就包含一个字节数组作为它本身的内部缓冲区,该缓冲区包含从流中读取的字节。
ByteArrayOutputStream实现了一个输出流,其中的数据被写入一个 byte 数组,缓冲区会随着数据的不断写入而自动增长,可使用 toByteArray() 和 toString() 获取数据。
举个例子如下:
package cn.lincain.io;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
public class ByteStreamDemo {
public static void main(String[] args) {
// 创建内存中的字节数组
byte[] btyeArray = { 1, 2, 3 };
try (
// 创建字节输入流
ByteArrayInputStream bis = new ByteArrayInputStream(btyeArray);
// 创建字节输出流
ByteArrayOutputStream bos = new ByteArrayOutputStream())
{
byte[] bff = new byte[3];
// 从字节流中读取字节到指定数组中
bis.read(bff);
System.out.println(bff[0]+","+bff[1]+","+bff[2]);
// 向字节输出流中写入字节
bos.write(bff);
// 从输出流中获取字节数组
byte[] bArrayFromBos = bos.toByteArray();
System.out.println(bArrayFromBos[0] + "," + bArrayFromBos[1] + "," + bArrayFromBos[2]);
} catch (Exception e) {
e.printStackTrace();
}
}
}
需要注意的是:在ByteArrayInputStream里面直接使用外部字节数组的引用,也就是说,即使得到字节流对象后,当改变外部数组时,通过流读取的字节也会改变。
PipedOutputStream/PipedInputStream
PipedOutputStream和PipedInputStream分别是管道输出流和管道输入流。
它们的作用是让多线程可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedOutputStream和PipedInputStream配套使用。
使用管道通信时,大致的流程是:我们在线程A中向PipedOutputStream中写入数据,这些数据会自动的发送到与PipedOutputStream对应的PipedInputStream中,进而存储在PipedInputStream的缓冲中;此时,线程B通过读取PipedInputStream中的数据。就可以实现,线程A和线程B的通信。
package cn.lincain.io1;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class PipedStreamTest {
public static void main(String[] args) {
try (final PipedOutputStream pos = new PipedOutputStream();
final PipedInputStream pis = new PipedInputStream(pos))
{
ExecutorService es = Executors.newFixedThreadPool(2);
es.execute(new Runnable() {
@Override
public void run() {
try {
byte[] bArr = new byte[] { 1, 2, 3 };
pos.write(bArr);
pos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
es.execute(new Runnable() {
@Override
public void run() {
byte[] bArr = new byte[3];
try {
// 会导致线程阻塞
pis.read(bArr, 0, 3);
pis.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(bArr[0] + "," + bArr[1] + "," + bArr[2]);
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
}
BufferedInputStream/BufferedOutputStream
BufferedInputStream和BufferedOutputStream 分别是缓冲输入流和缓存输出流,他们分别继承自FilterInputStream和FilterOutputStream,主要功能是一次读取/写入一大块字节到缓冲区,避免每次频繁访问外部媒介,提高性能。
其中BufferedInputStream的作用是缓冲输入以及支持 mark()和reset ()方法的能力。
BufferedOutputStream的作用是为另一个输出流提供“缓冲功能”。
下面的案例演示了采用缓冲流进行文件的复制。
package cn.lincain.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class BufferedStreamTest {
public static void main(String[] args) {
try (BufferedInputStream bis =
new BufferedInputStream(new FileInputStream("ByteStreamTest.java"));
BufferedOutputStream bos =
new BufferedOutputStream(new FileOutputStream("copy.txt")))
{
int hasRead = 0;
while ((hasRead = bis.read()) != -1) {
bos.write(hasRead);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
该程序和上面的FileStreamTest .java的代码大致相同,但是该案例的效率显然更高,只用了不到1ms的时间。
DataOutputStream/DataInputStream
DataInputStream允许应用程序读取在与机器无关方式从底层输入流基本Java数据类型,应用程序可以使用数据输出流写入稍后由数据输入流读取的数据。
DataOutputStream允许应用程序以适当方式将基本 Java 数据类型写入输出流中。然后,应用程序可以使用数据输入流将数据读入。
package cn.lincain.io;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class DataStreamTest {
public static void main(String[] args) {
try (
DataOutputStream dos =
new DataOutputStream(new FileOutputStream("target.txt"));
DataInputStream dis =
new DataInputStream(new FileInputStream("target.txt")))
{
dos.writeBoolean(false);
dos.writeChar('夜');
dos.write(18);
dos.writeUTF("权利的游戏");
System.out.println(dis.readBoolean());
System.out.println(dis.readChar());
System.out.println(dis.read());
System.out.println(dis.readUTF());
} catch (Exception e) {
e.printStackTrace();
}
}
}
如果要想使用数据输出流,则肯定要由用户自己制定数据的保存格式,必须按指定好的格式保存数据,才可以使用数据输入流将数据读取进来。
ObjectInputStream/ObjectOutputStream
ObjectOutputStream用于将指定的对象写入到文件的过程,就是将对象序列化的过程。ObjectInputStream则是将储存在文件的对象读取出来,就是将对象反序列化的过程。
一个对象如果要实现序列化和反序列化,则需要该对象实现Serializable或者Externalizable接口。
class Person implements Serializable{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
package cn.lincain.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class ObjectStreamTest {
public static void main(String[] args) {
Person person = new Person();
person.setAge(28);
person.setName("Lincain");
writeObject(person);
readObject();
}
// 将对象写入指定的文件
public static void writeObject(Object object) {
try (
ObjectOutputStream oos =
new ObjectOutputStream(new FileOutputStream("object.txt")))
{
oos.writeObject(object);
} catch (Exception e) {
e.printStackTrace();
}
}
// 将文件中将对象读取出来
public static void readObject() {
try (
ObjectInputStream ois =
new ObjectInputStream(new FileInputStream("object.txt")))
{
Person person = (Person)ois.readObject();
System.out.println(person);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行上面程序,在磁盘上产生了object.txt文件,说明对象已将序列化到本地文件,如下图:
需要注意的是,反序列化过程读取的仅仅是Java对象的数据,而不是Java类,因此反序列化恢复Java对象时,必须提供该对象的class文件,否则会引起ClassNotFoundException异常。另外反序列化也无须通过构造器来初始化对象。
关于序列化的知识可参考:https://www.cnblogs.com/fnz0/p/5410856.html

PushbackInputStream
退回:其实就是将从流读取的数据再推回到流中。实现原理也很简单,通过一个缓冲数组来存放退回的数据,每次操作时先从缓冲数组开始,然后再操作流对象。
package cn.lincain.io;
import java.io.ByteArrayInputStream;
import java.io.PushbackInputStream;
public class PushBackInputStreamTest {
public static void main(String[] args) {
String str = "abcdefghijk";
try (
// //创建字节推回流,缓冲区大小为 7
ByteArrayInputStream bis = new ByteArrayInputStream(str.getBytes());
PushbackInputStream pis = new PushbackInputStream(bis,7))
{
byte[] hasRead = new byte[7];
// 从流中将7个字节读入数组
pis.read(hasRead);
System.out.println(new String(hasRead)); //abcdefg
// 从数组的第一个位置开始,推回 4 个字节到流中
pis.unread(hasRead,0,4);
// 重新从流中将字节读取数组
pis.read(hasRead);
System.out.println(new String(hasRead)); // abcdhij
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 创建字节推回流,同时创建了大小为7的缓冲区数组;要从字节输入流读取字节到
hasRead数组; - 从流中读取 7 个字节到
hasRead数组; - 现在要从
hasRead的 0 下标(第一个位置)开始,推回 4 个字节到流中去(实质是推回到缓冲数组中去); - 再次进行读取操作,首先从缓冲区开始读取,再对流进行操作。
PrintStream
PrintStream 为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式,使其它输出流能方便的通过print(), println()或printf()等输出各种格式的数据。
package cn.lincain.io;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class PrintStreamTest {
public static void main(String[] args) {
try (
// 创建打印流,并允许在文件末端追加
PrintStream ps = new PrintStream(new FileOutputStream("a.txt", true)))
{
// 将字符串“Hello,字节流!”+回车符,写入到输出流中
ps.println("Hello,字节流!");
// 97对应ASCII码的是'A',也就是说此处写入的是字符'A'
ps.write(97);
// 将字符串"97"写入输出流中,等价于ps.write(String.valueOf(97))
ps.print(97);
// 将'B'追加到输出流中,和ps.print('B')效果相同
ps.append('B');
// Java的格式化输出
String str = "CDE";
int num = 5;
ps.printf("%s is %d\n", str, num);
} catch (Exception e) {
e.printStackTrace();
}
}
}
关于PrintStream和DataOutputStream的区别,可阅读:https://www.cnblogs.com/skywang12345/p/io_16.html
SequenceInputStream
SequenceInputStream表示其他输入流的逻辑串联。它从输入流的有序集合开始,并从第一个输入流开始读取,直到到达文件末尾,接着从第二个输入流读取,依次类推,直到到达包含的最后一个输入流的文件末尾为止。
package cn.lincain.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.List;
public class SequenceInputStreamTest {
public static void main(String[] args) throws IOException {
enumMerge();
}
// 通过public SequenceInputStream(Enumeration<? extends InputStream> e)创建SequenceInputStream
public static void enumMerge() throws IOException {
List<FileInputStream> arrayList = new ArrayList<>();
FileInputStream is1 = new FileInputStream("1.txt");
FileInputStream is2 = new FileInputStream("2.txt");
FileInputStream is3 = new FileInputStream("3.txt");
arrayList.add(is1);
arrayList.add(is2);
arrayList.add(is3);
Enumeration<FileInputStream> enumeration = Collections.enumeration(arrayList);
BufferedInputStream bis =
new BufferedInputStream(new SequenceInputStream(enumeration));
BufferedOutputStream bos =
new BufferedOutputStream(new FileOutputStream("4.txt"));
int hasRead = 0;
while ((hasRead = bis.read()) != -1) {
bos.write(hasRead);
}
bis.close();
bos.close();
}
}
字符流(Reader/Writer)
字节流和字符流的操作方式几乎一样,只是他们操作的数据单元不同,体现在方法上时,就是方法的参数有所差别。
首先字符输入流Reader,它的三个方法分别是:
int read():从输入流中读取单个字符,返回所读取的世界数据。int read(char[] c):从输入流中最多读取b.length个字符的数据,并将其存储在缓冲区数组c中,返回实际读取的字符数。int read(char[] c,int off,int len):将输入流中最多len个数据字符读入缓冲区数组c中,off为数组 c 中将写入数据的初始偏移量,返回实际读取的字符数。
字符输出流Writer,因为它可以直接操作字符,可以用字符串代替字符数组,所以它有如下五个基本方法。
void write(int c):将指定的字符写入此输出流。void write(char[] c):将b.length个字符从指定的c数组写入此输出流。void write(char[] c,int off,int len):将字符数组中从偏移量off开始的len个字节写入此输出流。void write(String str):将str中包含的字符输出到指定的输出流中。void write(String str, int off,int len):将str从off位置开始,长度为len的字符输出到指定输出流中。
FileReader/FileWriter
通过FileReader/FileWriter我们可以实现对文本文件的读取、写入,从而实现文本文件的复制。
package cn.lincain.io;
import java.io.FileReader;
import java.io.FileWriter;
public class FileCopyTest {
public static void main(String[] args) {
try (
FileReader fr = new FileReader("FileCopyTest.java");
FileWriter fw = new FileWriter("copy.txt"))
{
char[] cbuf = new char[32];
int hasRead = 0;
while ((hasRead = fr.read(cbuf)) != -1) {
fw.write(cbuf, 0, hasRead);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
CharArrayReader/CharArrayWriter
CharArrayReader/CharArrayWriter就是字符数组与字符输入输出流之间的各种转换。和ByteArrayInputStream/ByteArrayOutputStream类似,它们都有一个内部缓冲区,区别是前者操作字符,后置操作字节。
package cn.lincain.io;
import java.io.CharArrayReader;
import java.io.CharArrayWriter;
public class CharArrayTest {
public static void main(String[] args) {
char[] charArray = "无边落木萧萧下,不尽长江滚滚来!!!".toCharArray();
try (
CharArrayReader cr = new CharArrayReader(charArray);
CharArrayWriter cw = new CharArrayWriter())
{
int hasRead = 0;
char[] buff = new char[1024];
while ((hasRead = cr.read(buff)) != -1) {
cw.write(buff, 0, hasRead);
}
// 将输入数据转换为字符串。
System.out.println(cw.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
同样需要注意的是,在CharArrayReader里面直接使用外部字符数组的引用,也就是说,即使得到字符流对象后,当改变外部数组时,通过流读取的字符也会改变。
BufferedReader/BufferedWriter
和缓冲字节流相似的,缓冲字符流可以用来装饰其他字符流,为其提供字符缓冲区,避免频繁的和外界交互,从而提高效率。被装饰的字符流可以有更多的行为,比如readLine()和newLine()方法等。
下来我们还是通过文件复制的案例,对其效果进行演示。
package cn.lincain.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
public class BufferedCopyTest {
public static void main(String[] args) {
try (
// 创建字符缓冲输入流
BufferedReader br =
new BufferedReader(new FileReader("BufferedCopyTest.java"));
// 创建字符缓冲输出流
BufferedWriter bw =
new BufferedWriter(new FileWriter("copy.txt")))
{
String line = null;
// 调用readLine()方法,每次读取一行
while ((line = br.readLine()) != null) {
// 将字符串写入到输出流中
bw.write(line);
// 向输出流写入一个换行符
bw.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
PipedReader/PipedWriter
通过阅读源码可知,PipedReader/PipedWriter分别将对方作为自己的成员变量,可知二者需要配套使用。通过二者建立联系,构建一个字符流通道,PipedWriter向管道写入数据,PipedReader从管道中读取数据,从而实现线程的通信。
如下示例:
package cn.lincain.io;
import java.io.IOException;
import java.io.PipedReader;
import java.io.PipedWriter;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class PipedTest {
public static void main(String[] args) throws IOException {
final PipedWriter pw = new PipedWriter();
final PipedReader pr = new PipedReader(pw);
ExecutorService eService = Executors.newFixedThreadPool(2);
eService.execute(new Runnable() {
@Override
public void run() {
try {
pw.write("线程交互!!!");
} catch (IOException e) {
e.printStackTrace();
}
}
});
eService.execute(new Runnable() {
@Override
public void run() {
char[] cbuf = new char[32];
try {
// 会导致线程阻塞
pr.read(cbuf);
pr.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(cbuf);
}
});
}
}
需要注意的是:一定要同一个JVM中的两个线程,且读写都会阻塞线程。
StringReader/StringWriter
这两个类和前面介绍的CharArrayReader/CharArrayWriter很相似,只是后者操作的数据类型为字符数组,而这里操作的是字符串,二者的方法也大致相同,下面通过案例来说明。
package cn.lincain.io;
import java.io.StringReader;
import java.io.StringWriter;
public class StringBufferTest {
public static void main(String[] args) {
String str = "字符串缓冲流";
try (
StringReader sr = new StringReader(str);
StringWriter sw = new StringWriter())
{
// 从输入流中读取数据
int hasRead = 0;
char[] cbuf = new char[32];
while ((hasRead = sr.read(cbuf)) != -1) {
System.out.println(new String(cbuf, 0, hasRead));
}
// 向输出流中写入数据
sw.write(str);
System.out.println(sw.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
PushbackReader
PushbackReader和PushbackInputStream的操作方式基本一样,这里就不在再详细的介绍,通过案例对其进行说明。
package cn.lincain.io;
import java.io.FileReader;
import java.io.IOException;
import java.io.PushbackReader;
public class PushbackReaderTest {
public static void main(String[] args) throws IOException {
PushbackReader pbr =
new PushbackReader(new FileReader("PushbackReaderTest.java"),30);
char[] cbuf = new char[24];
pbr.read(cbuf);
System.out.println(new String(cbuf)); // package cn.lincain.io3;
// 如果pbr中的缓冲区的大小小于回退数组的大小,则抛出异常
pbr.unread(cbuf);
pbr.read(cbuf);
System.out.println(new String(cbuf)); // package cn.lincain.io3;
pbr.close();
}
}
PrintWriter
PrintWriter和PrintStream的操作基本一致,只是前者多了两个方法:void write(String s)和void write(String s,int off,int len)。
但通过源码可知,PrintStream也有这两个方法,只是用private修饰,方法内容不一样,但是最终都指向了Writer类的void write(String str, int off, int len)方法。
package cn.lincain.io;
import java.io.PrintWriter;
public class PrintWriterTest {
public static void main(String[] args) {
try (
PrintWriter pw = new PrintWriter(System.out))
{
// 97对应ASCII码的是'A',也就是说此处写入的是字符'A'
pw.write(97);
// 将字符串"97"写入输出流中,等价于ps.write(String.valueOf(97))
pw.print(97);
// 将'B'追加到输出流中,和ps.print('B')效果相同
pw.append('B');
// Java的格式化输出
String str = "CDE";
int num = 5;
pw.printf("%s is %d\n", str, num);
} catch (Exception e) {
e.printStackTrace();
}
}
}