十岁的小男孩
目录
引言
论文
A. MobileNets
B. ShuffleNet
C. Xception
D. Squeezenet
E. ResNeXt
引言
在保证模型性能的前提下尽可能的降低模型的复杂度以及运算量。除此之外,还有很多工作将注意力放在更小、更高效、更精细的网络模块设计上,使用特定结构,如 ShuffleNet, MobileNet, Xception, SqueezeNet,它们基本都是由很小的卷积(1*1和3*3)组成,不仅参数运算量小,同时还具备了很好的性能效果。
A. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址 GitHub源码 MobilenetV1 MobilenetV2 论文解读
这篇论文是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,取名为MobileNets。核心思想就是卷积核的巧妙分解,可以有效减少网络参数。所谓的卷积核分解,实际上就是将a × a × c分解成一个a × a × 1的卷积和一个1 ×1 × c的卷积,,其中a是卷积核大小,c是卷积核的通道数。其中第一个a × a × 1的卷积称为Depthwise Separable Convolutions,它对前一层输出的feature map的每一个channel单独进行a × a 的卷积来提取空间特征,然后再使用1 ×1 的卷积将多个通道的信息线性组合起来,称为Pointwise Convolutions,如下图:
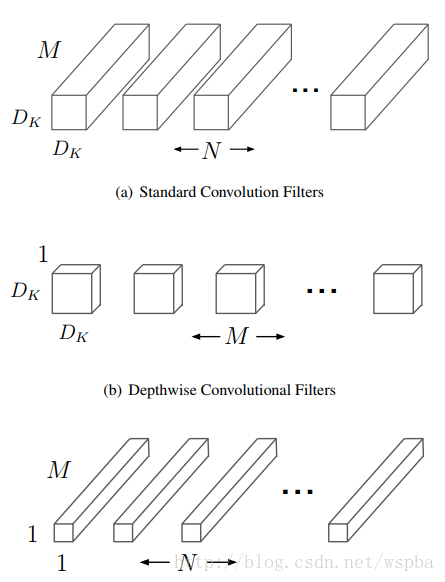
这样可以很大程度的压缩计算量:
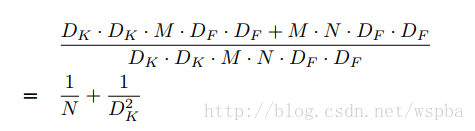
其中DK为原始卷积核的大小,DF为输入feature map的尺寸, 这样相当于将运算量降低DK^2倍左右。
MobileNet中Depthwise实际上是通过卷积中的group来实现的,其实在后面也会发现,这些精细模型的设计都是和group有关。
B. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址 GitHub源码 论文解读
作者提出,虽然MobileNet、ResNeXt等网络能够大大的降低模型的复杂度,并且也能保持不错的性能,但是1 ×1卷积的计算消耗还是比较大的,比如在ResNeXt中,一个模块中1 ×1卷积就占据了93%的运算量,而在MobileNet中更是占到了94.86%,因此作者希望在这个上面进一步降低计算量:即在1 ×1的卷积上也采用group的操作,但是本来1 ×1本来是为了整合所有通道的信息,如果使用group的操作就无法达到这个效果,因此作者就想出了一种channel shuffle的方法,如下图:
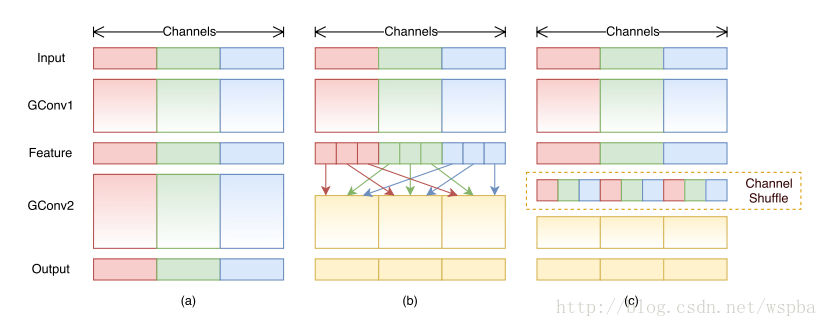
如上图b和c,虽然对1 ×1的卷积使用了group的操作,但是在中间的feature map增加了一个channel shuffle的操作,这样每个group都可以接受到上一层不同group的feature,这样就可以很好的解决之前提到的问题,同时还降低了模型的计算量,ShuffleNet的模块如下: 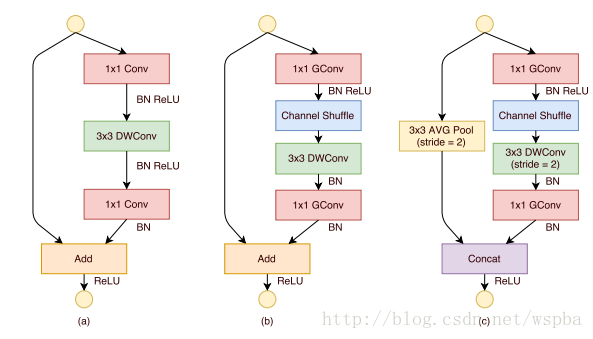
作者使用了不同的group数进行实验,发现越小的模型,group数量越多性能越好。这是因为在模型大小一样的情况下,group数量越多,feature map的channel数越多,对于小的模型,channel数量对于性能提升更加重要。
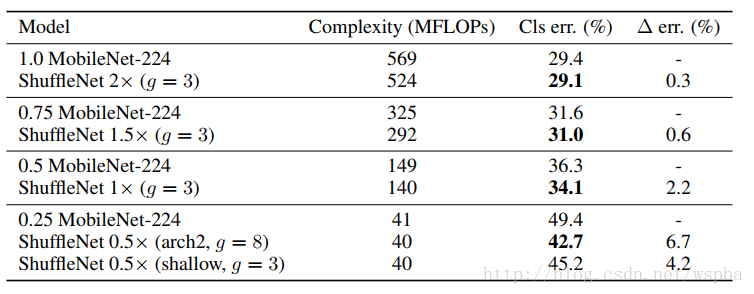
最后作者将shufflenet的方法和mobilenet的方法进行了比较,性能似乎更胜一筹:
C. Xception: Deep Learning with Depthwise Separable Convolutions
论文地址 GitHub源码 论文解读
D. Squeezenet: Alexnet-level Accuracy with 50x Fewer Parameters and <0.5MB Model Size
E. ResNeXt:Aggregated Residual Transformations for Deep Neural Networks
作者提出,在传统的ResNet的基础上,以往的方法只往两个方向进行研究,一个深度,一个宽度,但是深度加深,模型训练难度更大,宽度加宽,模型复杂度更高,计算量更大,都在不同的程度上增加了资源的损耗,因此作者从一个新的维度:Cardinality(本文中应该为path的数量)来对模型进行考量,作者在ResNet的基础上提出了一种新的结构,ResNeXt: 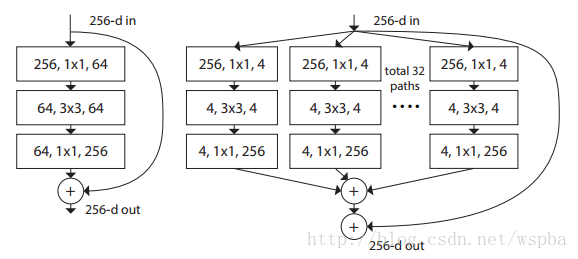
上图中两种结构计算量相近,但是右边结构的性能更胜一筹(Cardinality更大)。
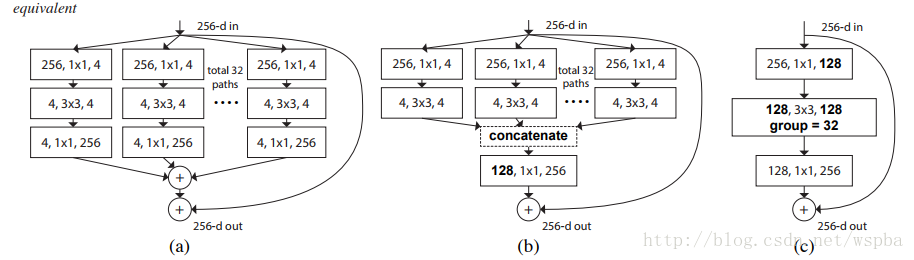
以上三种结构等价,因此可以通过group的形式来实现ResNeXt。其实ResNeXt和mobilenet等结构性质很相近,都是通过group的操作,在维度相同时降低复杂度,或者在复杂度相同时增加维度,然后再通过1*1的卷积将所有通道的信息再融合起来。因此全文看下来,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
知识应该是开源的,欢迎斧正。[email protected]