一、安装库
pip install wheel
pip install scrapy
pip install pywin32
'''
windows 可能需要安装 Microsoft Visual C++ Build Tools 和 Visual C++ 14.0,如果C++版本不够,需要安装后才能安装scrapy库
'''二、工作流程
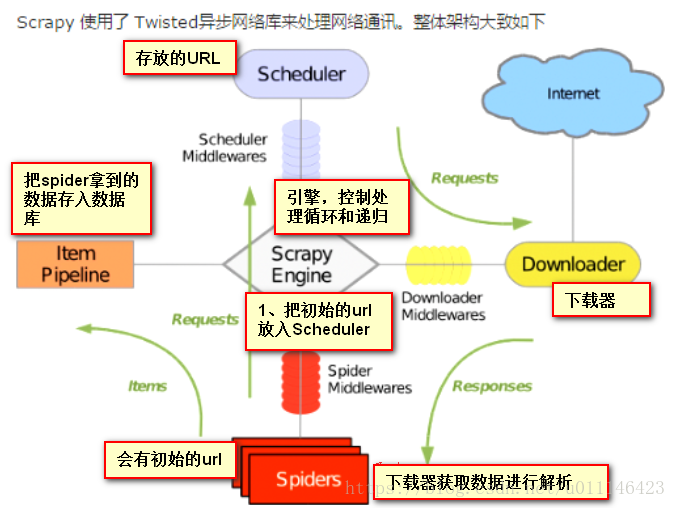
1、指定初始URL
2、解析响应内容
- 给到调度器(Scheduler)继续执行
- 给pipeline;item 用于存储数据;格式化
- twisted 基于事件循环的异步非阻塞模块。一个线程同时可以向多个目标发去Http请求三、创建项目
# 创建项目
scrapy startproject 项目名称
# 进入到项目名称文件夹
cd 项目名称
# 创建 蜘蛛spidet
scrapy genspider 蜘蛛名称 url地址
# 执行
scrapy crawl 蜘蛛名称
# 执行取消日志
scrapy crawl 蜘蛛名称 --nolog
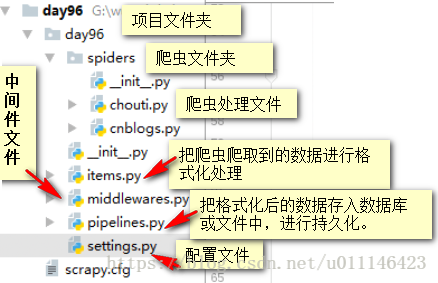
3.1、目录结构
四、scrapy操作
# windows 设置输出编码 Linux,mac不用
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
# 解析返回的数据
from scrapy.selector import Selector,HtmlXPathSelector
'''
Selector(response=response).xpath('查找的内容')找到所有标签,返回标签队形列表,通过for循环取出;
.extract() 将标签对象转换为字符串,通过for循环取出;
.extract_first() 只获取列表的第一个;
“//”表示整个标签文档查找,“.//”表示在当前标签下查找,“/”表示在当前标签的子集中查找;
“/div[@id="i1"]” 表示查找子集中div id=i1 的标签;
“/text()” 获取标签中的文本信息;
“div/@id” 获取id的值;
“//a[starts-with(@href,'/all/hot/recent/')]/@href” starts-with()获取属性值
“//a[re:test(@href,'/all/hot/recent\d+')]” 正则获取属性值
“//a[contents(@href,'link')]” 获取a标签中href包含link的标签对象
'''
# 语法
hxs = Selector(response=response).xpath('//标签名[@id="标签属性值"]/div[@class="标签属性值"]/text()').extract()
# 获取所有分页页码
- 利用set() 集合类型,来去除页面的重复信息;
- 获取所有的分页
yield Request(url=url,callback=self.parse) # 将获取到的新分页添加到调度器中
- 设置获取url的深度
settings.py 文件 DEPTH_LIMIT=1
# url进行加密存储,可以提高数据库查询效率
import hashlib
obj = hashlib.md5()
obj.update(bytes(url,encoding="utf-8")) # 进行加密
obj.hexdigest() # 得到加密的值
# 蜘蛛文件下 response
response.url # 获取请求url
response.text # 获取返回的结果
response.body # 获取返回内容
response.request # 发送请求
response.meta = {"depth":"抓取深度"}
content = str(response.body,encoding="utf-8") # windows转换编码 Linux,mac不用
4.1、抽屉小例子(分页的获取)
# -*- coding: utf-8 -*-
import scrapy
import sys
import io
from ..items import ChoutiItem
# from scrapy import Request,Selector
from scrapy.http import Request
# 解析返回的数据
from scrapy.selector import Selector,HtmlXPathSelector
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
class ChoutisSpider(scrapy.Spider):
name = 'choutis'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
visited_url = set() # 去除重复的分页页码
'''
从写start_requests() 方法后,就可以改变scrapy库默认的pacse()方法的名称,
同时改变callback 指向。
def start_requests(self):
for url in self.start_urls:
yield Request(url,callback=self.parse)
'''
# scrapy 库默认的方法pacse
def parse(self, response):
print(response.meta)
# 获取标题和url
hxs1 = Selector(response=response).xpath('//div[@id="content-list"]/div[@class="item"]')
for obj in hxs1:
title = obj.xpath('.//a[@class="show-content color-chag"]/text()').extract_first().strip() # strip() 去除空白
href = obj.xpath('.//a[@class="show-content color-chag"]/@href').extract_first().strip()
'''
这里需要引用 item 对象,才能对数据进行格式化
from ..items import ChoutiItem
'''
# 将获取到的值传入Item对象进行格式化处理
item_obj = ChoutiItem(title=title, href=href)
# 将item对象传递给 pipeline 必须是yield返回
yield item_obj
# 获取页码的url(正则方式)
hxs = Selector(response=response).xpath('//a[re:test(@href,"/all/hot/recent/\d+")]/@href').extract()
for url in hxs:
md5_url = self.md5(url)
# self.visited_url.add(md5_url) # 将分页url添加到set()集合中去重复
if md5_url in self.visited_url:
print('包含')
pass
else:
url_page = "https://dig.chouti.com%s" %url
print(url_page)
yield Request(url=url_page, callback=self.parse) # 将要访问新url添加到调度器中
def md5(self, url):
import hashlib
obj = hashlib.md5()
obj.update(bytes(url, encoding="utf-8")) # 进行加密
return obj.hexdigest() # 得到加密的值
4.2、items.py 文件
import scrapy
class ChoutiItem(scrapy.Item):
title = scrapy.Field()
href = scrapy.Field()
4.3、pipelines.py 文件
# 多个处理函数不再指定后续执行函数时必须将item丢弃掉,抛出dropiten异常
from scrapy.exceptions import DropItem
# pipeline操作事件钩子
class ChoutiPipeline(object):
# 初始化数据
def __init__(self,conn_str):
self.conn_str = conn_str
self.conn = None
# 每当数据要写入数据时会被调用
def process_item(self, item, spider):
print(item)
f = open('item.json','a+',encoding='utf-8')
tpl = '%s \n\n %s \r\n'%(item['title'],item['href'])
f.write(tpl)
f.close()
# return item # 如果有多个处理函数,必须返回item才能执行下一个处理函数
raise DropItem() # 将此item丢弃,不再有后续的函数进行内容处理
def open_spider(self,spider):
# 爬虫开启时调用
pass
def close_spider(self,spider):
# 爬虫关闭时调用
pass
@classmethod
def from_crawler(cls,crawler):
# 获取settings.py的内容 conn_str 的 key
val = crawler.settings.getint('DB') # 必须大写
return cls(val) #创建对象 cls() = ChoutiPipeline()
'''
将获得数据写入数据库或者文件中
self.conn_str 可以创建数据库连接
'''5、自定义去重复URL或者文件
5.1、settings.py 配置
# 配置 pipelines.py 中的执行函数
ITEM_PIPELINES = {
'chouti.pipelines.ChoutiPipeline' : 300, # 300 表示权重
'chouti.pipelines.ChoutiPipeline2' : 300,
}
# url 深度配置
DEPTH_LIMIT=1
# 配置自定义去重类的加载
DUPEFILTER_CLASS = "chouti.duplication.RepeatFilter"5.2、自定义去重配置
# 在项目中新建一个python文件duplication.py 这个返回的参数对应的是 Request(dont_filter=False) 参数
# 去重事件钩子
class RepeatFilter(object):
def __init__(self):
self.visited_set = set()
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request): # 表示请求是否被查看过
print('....')
if request.url in self.visited_set:
return True
self.visited_set.add(request.url)
return False
def open(self):
print('open')
def close(self, reason):
print('close')
def log(self, request, spider):
print('log....')5.3、choutis.py 配置
# -*- coding: utf-8 -*-
import scrapy
import sys
import io
from ..items import ChoutiItem
from scrapy import Request,Selector
# from scrapy.dupefilters import RFPDupeFilter # URL去重模块 自定义将覆盖原有的内容
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
class ChoutisSpider(scrapy.Spider):
name = 'choutis'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
# scrapy 库默认的方法pacse
def parse(self, response):
print(response.url)
# 获取标题和url
hxs1 = Selector(response=response).xpath('//div[@id="content-list"]/div[@class="item"]')
for obj in hxs1:
title = obj.xpath('.//a[@class="show-content color-chag"]/text()').extract_first().strip() # strip() 去除空白
href = obj.xpath('.//a[@class="show-content color-chag"]/@href').extract_first().strip()
'''
这里需要引用 item 对象,才能对数据进行格式化
from ..items import ChoutiItem
'''
# 将获取到的值传入Item对象进行格式化处理
item_obj = ChoutiItem(title=title, href=href)
# 将item对象传递给 pipeline 必须是yield返回
yield item_obj
# 获取页码的url(正则方式)
hxs = Selector(response=response).xpath('//a[re:test(@href,"/all/hot/recent/\d+")]/@href').extract()
for url in hxs:
url_page = "https://dig.chouti.com%s" %url
# 将要访问新url添加到调度器中 dont_filter 设置是否去除重复的URL False表示去重
yield Request(url=url_page, callback=self.parse,dont_filter=False)
6、cookice 相关知识
# cookies操作
# 引入处理 cookies 模块
import scrapy.http.cookies import CookieJar
# 创建对象
cookie = CookieJar()
# response.request 发送的请求
cookie_obj.extract_cookies(response,response.request)
# 获取所有 cookie
cookie_dict = cookie._cookies
print(cookie_dict)
6.1、登录抽屉点赞案例
# -*- coding: utf-8 -*-
import scrapy
import sys
import io
from ..items import ChoutiItem
from scrapy import Request,Selector
# 处理 Cookies 模块
import scrapy.http.cookies import CookieJar
# from scrapy.dupefilters import RFPDupeFilter
# 解析返回的数据
# from scrapy.selector import Selector,HtmlXPathSelector
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
class ChoutisSpider(scrapy.Spider):
name = 'choutis'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
cookie_dict = None
def parse(self,response):
pprint(dir(response))
cookie = CookieJar()
cookie.extract_cookies(response,response.request)
self.cookie_dict = cookie._cookies
yield Request(
url='http://dig.chouti.com/login',
method='POST',
cookies=self.cookie_dict,
body='phone=&password=&oneMone=1',# 请求体
headers={'Cobtebt-Type':''},
callback=self.chek_login,
)
def chek_login(self,response):
print(response.text)
yield Request(
url='http://dig.chouti.com',
method='GET',
callback=self.good
)
def good(self,response):
# 查找点赞的id
id_list = Selector(response=response).xpath('//div[@share-linkid]/@share-linkid').extract().strip()
for nid in id_list:
url = 'http://dig.chouti.com/link/vote?linksId=%s'%nid
yield Request(
url=url,
method='POST',
cookies=self.cookie_dict,
callback=self.show_good
)
# 找分页
page_urls = Selector(response=response).xpath('//div[@id="dig_lcpage"]//a/#href').extract()
for page in page_urls:
url = 'http://dig.chouti.ccom%s'%page
yield Request(
url=url,
callbcak=self.good
)
def show_good(self,response):
print(response.test)7、scrapy扩展
# settings.py设置
EXTENSIONS = {
'项目名.文件名.类名':300,
}7.1、自定义扩展格式(生命周期)
# extensions.py
'''
在scrapy运行期间过阶段的生命周期
engine_started = object() # 引擎开始
engine_stopped = object() # 引擎停止
spider_opened = object() # 爬虫开始
spider_idle = object() # 爬虫执行
spider_closed = object() # 爬虫结束
spider_error = object() # 爬虫出现错误
request_scheduled = object() # 请求
request_dropped = object() # 抛弃请求
response_received = object() # 收到响应
response_downloaded = object() # 下载响应数据
item_scraped = object() # 插入item
item_dropped = object() # 抛弃item
'''
from scrapy import signals
class MyExtend:
def __init__(self,crawler):
self.crawler = crawler
# 将函数注册到相应的生命周期
crawler.signals.connect(self.start,signals.engine_started)
crawler.signals.connect(self.close,signals.engine_closed)
@claamethod
# 注册方法
def from_crawler(cls,crawler):
return cls(crawler)
def start(self):
print('signals.engine_etarted.start')
def close(self):
print(signals.engine_etarted.close')8、配置文件settings.py
BOT_NAME = "" # 爬虫名称
USE_AGENT = "" # 请求头信息浏览器信息,系统信息
ROBOTSTXT_OBEY = False # 是否遵循 robors.txt
CONCURRENT_REQUESTS = 32 # 并发请求数
DOWNLOAD_DELAY = 3 # 延迟下载限制(秒)
CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 每个域名请求并发数量
CONCURRENT_REQUESTS_PER_IP = 16 # 每个IP请求并发数量
COOKIES_ENABLED = False # 是否爬取cookie
COOKIES_ENABLED = True # 是否开启cookie引擎
COOKIES_DEBUG = True # 是否开启cookie debug
DEPTH_PRIORITY = 0 # 0 和 1 表示爬取模式为深度优先Lifo,还是广度优先Fifo
- SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
- SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
DEPTH_PRIORITY = 1
- SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
- SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
DUPEFILTER_CLASS = "chouti.duplication.RepeatFilter" # 自定义去重
DEPTH_LIMIT = 2 # 设置爬虫爬取的层级
SCHEDULER = 'scrapy.core.scheduler.Scheduler' # 调度器队列
# 监听爬虫的状态
TELNETCONSOLE_ENABLED = False # 是否开启监听
TELNETCONSOLE_PORT = 6023 # 设置端口
TELNETCONSOLE_HOST= '127.0.0.1' # 设置地址
命令:telnet 127.0.0.1 6023
ext() # 查看爬虫的信息
# 默认的请求头信息
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 爬虫中间件
SPIDER_MIDDLEWARES = {
'chouti.middlewares.ChoutiSpiderMiddleware': 543,
}
# 扩展
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
# 自定义数据存储类
ITEM_PIPELINES = {
'chouti.pipelines.ChoutiPipeline': 300,
}
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
'chouti.middlewares.ChoutiDownloaderMiddleware': 543,
}
# 智能请求爬虫引擎时间
AUTOTHROTTLE_ENABLED = True
AUTOTHROTTLE_START_DELAY = 5 # 第一个请求延迟几秒
AUTOTHROTTLE_MAX_DELAY = 60 # 最大请求延迟多少秒
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 #
AUTOTHROTTLE_DEBUG = False
# 缓存
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache' # 缓存目录
HTTPCACHE_IGNORE_HTTP_CODES = [] # 忽略状态码
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'9、中间件(可以写在同一个文件内)
9.1、settings.py配置
# settings.py 配置
DOWNLOADER_WIDDLEWARES = {
'项目名.文件名.类名':500,
}9.2、scrapy 自定义代理
class ProxyMiddleWare(object):
def process_request(self,request,spider):
PROXIES = [
{'ip_port':'111.11.228.75:80','user_padd':'用户名@密码'},
]
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes('http://%s'%proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic'+encoded_user_pass)
else:
request.meta['proxy'] = to_bytes('http://%s'%proxy['ip_port'])9.3、scrapy 下载中间件
'''
在执行多个下载中间件时的执行循序:
DownMiddleWare1.process_request -> DownMiddleWare2.process_request ->
DownMiddleWare2.process_response -> DownMiddleWare1.process_response -> spider
ps:
1、只要一个下载中间件执行完成,后续的不执行
2、process_response 必须有 return response
'''
class DownMiddleWare1(object):
def process_request(self,request,spider):
pass
def process_response(self,request,response,spider):
'''
return:
Response 对象:转交给其他的中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
'''
return response
def process_exception(self,request,response,spider):
'''
在执行process_request时如果出现错误,将执行process_exception函数
return:
None:继续交给后续中间件process_exception函数处理异常
Response 对象:停止后续的process_exception方法
Request 对象:停止中间件 request将会被重新调用下载
'''
return None
class DownMiddleWare2(object):
def process_request(self,request,spider):
pass
def process_response(self,request,response,spider):
return response9.3、spider 中间件
class SpiderMiddleWare(object):
def process_start_requests(self,start_requests,spider): # spider 开始工作的时候执行
return start_requests
def process_spider_input(self,response,spider): # 执行parse之前执行
pass
def process_spider_output(self,response,result,spider):
# parse执行完之后执行 result 是parse yield 的结果
return result # 返回值必须包含 Request 或 item 对象的可迭代对象(iterable)
def process_spider_exception(self,response,exception,spider):
return None
# 返回值为None,继续交给后续中间件处理异常;包含 Response 或 item 对象的可迭代对象(iterable),交给调度器或pipline10、scrapy 自定义命令
在spiders同级创建任意目录,在目录中创建.py文件
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings
class Command(AcrapyCommand):
requires_project = True
def syntax(self):
return ''
def short_desc(self):
return 'Runs all of the spiders' # --help提示信息
def run(self,args,opts):
# 获取所有爬虫的名称
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name,**opts.__dict__)
self.crawler_process.start() # 执行所有的爬虫
settings.py 配置
COMMANDS_MODULE = '项目名称.目录名称'执行命令
scrapy crawlall