10月26日
CNCC大会的会议报告主要有上午特邀报告和下午各个分会场报告。26号是会议第一天,上午不紧不慢的出发到达会场的时候,总会场前排的位置已经满了,于是在中间找了个位置坐下,不过视野不错,可以很清楚的看到PPT。第一次参加计算机前沿的会议,而且此次会议着眼于“人工智能”较多,心情是很期待的。
现代几何学在计算机科学中的应用(丘成桐)
丘成桐教授是1982年的菲尔兹奖获得者,他的报告主要围绕现代几何在CS中的应用展开。在计算机图形学、计算机网络、计算机辅助几何设计、数字几何处理领域等,现代几何都有许多直接应用。丘教授从数学的视角对这些问题提出了解决方案,涉及的数学知识对于我而言是过于深奥了。
人工智能算法具有不可解释性,机器学习的理论基础薄弱(黑箱算法),未来需要有深度学习理论的建立。但是现有的证明是指数级别的难度,可以说是在瓶颈阶段。
对抗生成网络,是用深度神经网络来计算概率测度之间的变换。应用最有传输理论和蒙日-安培理论可以为机器学习的黑箱给出透明的集合解释,并有助于设计更为高效和可靠的计算方法。

软件定义一切:挑战和机遇(梅宏)
梅宏教授从宏观的角度谈了一下软件领域的前生今世及未来。伴随着信息技术的发展,梅宏教授认为我们正在进入一个软件定义的时代。他解释了软件定义的本质和聂晗:硬件资源虚拟化、管理功能可编程。未来在人机物融合的场景下,万物可互联,万物课编程,随之是对软件定义的机遇和挑战。
在互联网环境下软件有了新特性和新形态,网构软件是面向互联网计算的软件新范型。三个特点:软件通过网络交付分发提供服务;软件运行于网络之上;软件基于网络开发。
互联网环境下软件使用新方式:服务化。如可在线直接使用的软件。
- 软件是实现互联网核心价值的重要使能技术,互联网的核心价值是连接。
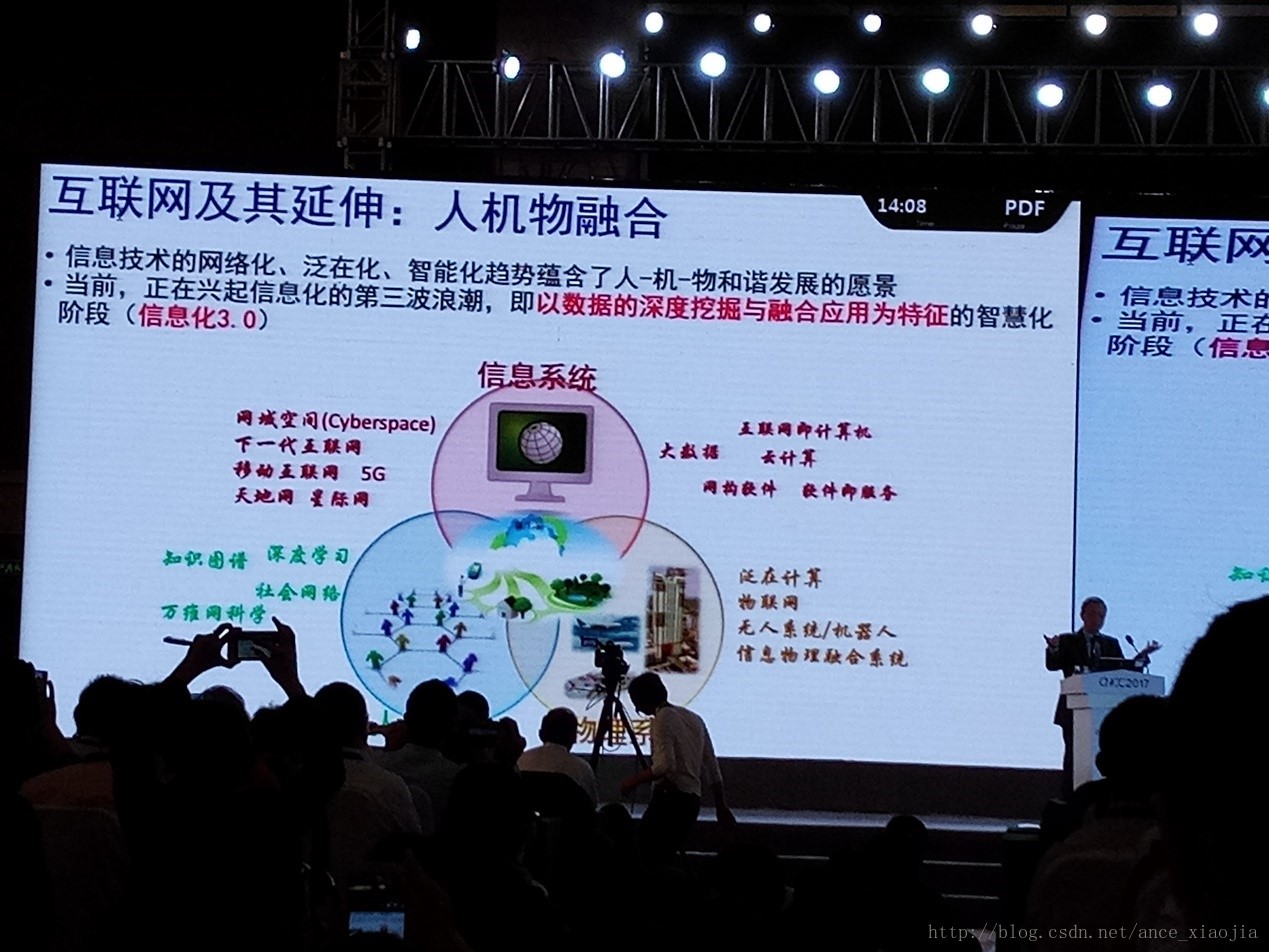
- 信息技术的网络化、范在化、智能化暗示了未来的人-机-物互联发展。现在是以数据的深度挖掘与融合应用为特征的智慧化阶段。
- 软件定义网络的技术原理:在不改动网络设备本身的情况下,通过一组API对网络设备进行任意的编程从而实现新型的网络协议。
- 未来的发展趋势:管理功能可编程+(API)+基础资源虚拟化。
- 现在的人工智能依然处于case by case、数据驱动的算法智能阶段。对未来的设想:软件平台提供智能应用支撑并允许按需深度定制;面向AI的操作系统。
- 制造业需要实现“硬件”、知识、工艺流程的软件化,进而实现软件的平台化。
理解自然语言(沈向洋)
沈向洋是微软全球执行副总裁,也是计算机视觉和图形学研究的世界级专家。这次报告的内容是围绕自然语言理解展开的,同时涉及到基于人工智能的图像语义理解。
- 从感知的视觉、语音到认知的语言、理解,理解自然语言有三个层次:机器学习(表述)、机器智能(对话)、机器意识(意境)。
Give your Apps a human side 。Knock down barriers between you and your ideas. Enable natural and contextual interaction with tools that augment users’ experiences via the power of machine-based AI. Plug them in and bring your ideas to life.
微软认知服务计算机视觉API-Image Caption(有官方网页)。视觉类:人脸识别、情绪识别、视频检测、计算机视觉;语音类:声纹识别、自定义智能识别、语音识别;语言类:必应拼写检查、文本分析、网络级语言模型、语言分析、语言理解;知识类:学术搜索、实体链接、推荐、知识搜索;搜索类,必应相关产品。
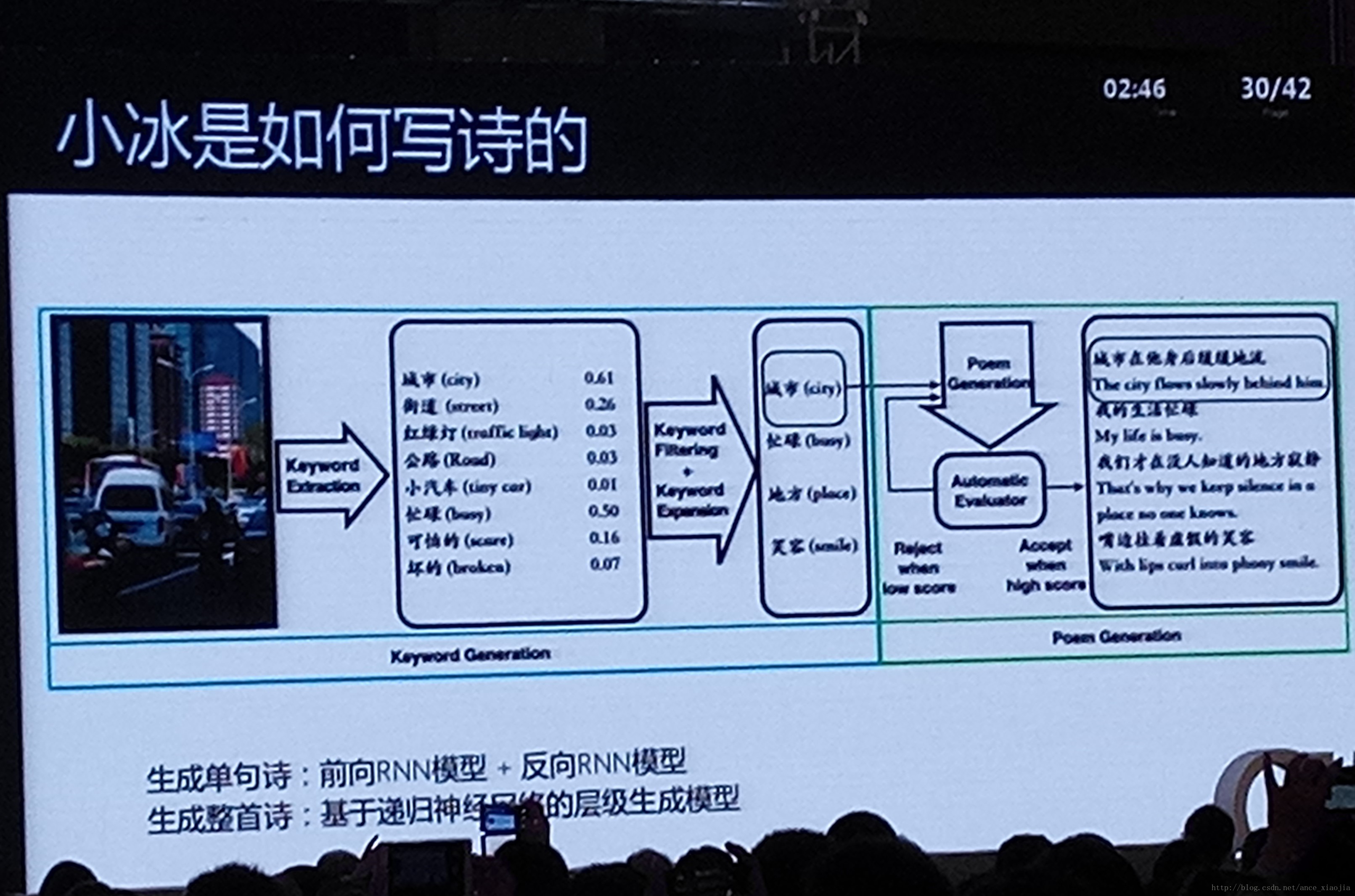
小冰写诗:前向RNN模型+后向RNN模型。生成整首诗:基于神经递归网络的层次生成模型
视觉智能(李飞飞)
李飞飞老师是斯坦福大学的教授,只要是计算机视觉领域的人估计是无人不知了吧,她主要讲的是图像数据中物体的关系识别。不仅要提取出图片中的物体信息,还要包含他们的关系,进行语义层次的提取,生成“场景图(scene graph)”。在scene gist之后,进一步通过对图像和语言的知识,来对图像作出“原因”的分析。飞飞的工作可以实现对图片的标注或是用一段话描述图片。具体的实现细节还需要读一读她的论文。

物联网+医疗(张黔)
张老师谈了“睡、吃、行”这些关乎医疗方面的问题。将物联网技术应用到这些人们生活的场景中,让人们更加健康的生活。
- 在睡眠方面张教授讲到了智能枕头在减少打鼾中的使用,通过智能穿戴设备检测血氧,可以判断用户打鼾(呼吸道阻塞)情况,然后和枕头联动来改变用户的姿势,减少打鼾。
吃这方面主要是检测用户摄入食品的种类。为了免去认为记录的麻烦,可以通过智能勺子、采用光谱分析的方法判断食物的种类,从而进行监控。可以给自己、给医生提供参考依据。
在行走方面是通过类似智能脚垫的装有多轴传感器的设备对行走姿态进行纠正和记录。
最后的安全是指,可以通过物联网设备进行身份识别等等应用提高应用安全。
平衡之美(张兰)
张兰是年轻的中科大的研究员,报告题目是“平衡之美”,谈的是对跨域感知数据的深度理解和隐私保护的问题。她围绕这个主题提到了很多她所在实验室的相关工作,我比较详细的记下了主要内容,也准备有时间将相关论文看一看。
非结构化数据占据网络流量的百分之八十以上,大量的感知数据还待理解。
对数据的理解需要动态情境和动态需求,并且语义层次丰富;对数据的使用,使用感知来源多样的数据,而不仅仅是使用有限的数据类型进行理解;普通设备资源有限,但是普遍模型开销大。
- 基于物理模型的数据理解:针对不同数据源和数据类型,通过对人、设备、环境构建物理模型,实现对数据语义的理解。采用多种方法来滤除噪音数据,提取更加准确的模型参数。
- 基于深度学习的数据理解:从运动传感器数据来挖掘出用户行为,感知数据的多层次语义理解模型,给出同一段数据的不同粒度的语义。(论文:Cihang Liu,Zhang Lan,Zongqian Liu,Kenbin Liu,Xiang-Yang Li,Yimhao Liu,Lasagna:Towards Deep Hieranchical Understanding and Searching over Mobile Sensing Data.ACM Mobicom,2016)
- 设备指纹(传感器硬件和软件环境的异质性使得产生的数据就像人的指纹一样具有独特的特征)基于深度学习、基于生成模型。
- 图像数据+用户交互,得出用户对图像的理解。(基于多层次图像语义的手机相册浏览和搜索,在交互过程中自动学习用户思维模式,优化浏览和搜索)
- 无线信号数据-》用户行为(这个和北大张大庆老师的研究基础是一样的,可以阅读这两篇论文,学习其研究方法),论文:Motion-Fi:基于无源节点的动作计数与识别
- 跨域感知数据的深度理解(跨域协同感知、多模态数据融合理解),这方面没有给出具体的论文,但是多模态数据融合和我的校级科研项目相关,可以学习相关的知识。
- 高性能深度学习移动计算框架(1. 移动端使用现有的深度学习模型,不损耗准确率,尽可能的减少电量开销、资源开销2. 提供API接口来获取良好的延展性3.可以保护用户的隐私)
- 保护隐私的云计算(支持Map-Reduce的隐私数据搜索框架,实现加密数据的索引构建,与现有的搜索技术和云计算框架兼容)(在小黄车系统中可用)
- 当前手机用户实时识别验证(论文可看)
10月27日
Motion planning Technologies for Human-Robot Interaction (Dinesh Manocha)
- 近期机器人的发展趋势:自动驾驶、仓储物流、大规模生产、服务机器人、用户应用
- 演讲者呼吁我们关注软件方法和算法解决问题,并且应用最近大热的计算机视觉、机器学习和并行计算方法,当然机器人和人的交互也是很重要的。硬件、软件及其接口,这三者的结合有助于提高机器人的性能。
- 这位演讲者的工作http://gamma.cs.unc.edu/software/#collision。
- 人类环境是杂乱和动态变化的,机器人要实时感知传感器的数据,尤其对于在线回应的抓取动作和动作规划而言,实时计算是非常重要的。
- 对于机器人而言,一个任务可以分解为很多原始的小任务,其中Move这个动作是占了大多数。
- 机器人可以对一些自然语言进行理解,接受人类的简单语言指令(Don’t),并且完成相应的操作。或者是根据人不同的举动或者干扰调整自己的行为。
从物体识别到场景理解(陈熙霖)
陈熙霖老师的报告主要着眼于对图片中的物体识别与场景理解,其中对场景的理解是在对物体识别的基础上的进步。超越单纯的物体识别是可视智能的重要表现,依赖于对物体和场景的深层次识别和推理以及相关背景知识,将视觉的感知和语言的推理认知结合起来。
- 人对一张图片从看、看见到看懂,涉及到大脑各个分区的共同工作。那么对于计算机而言,肯定是一个更加复杂的过程了。比如对一张图片从空间视角进行理解,就要对图像空间进行物理空间的时空采样,将图片中的元素对应到一个概念空间中去,以此解释这些元素之间的概念关系。
- 陈教授提到场景理解的挑战有以下三点:首先要实现从视力到视觉到视觉智能,其次建立元视觉概念集,以及将计算机视觉的研究从任务驱动走向事件/数据驱动。
- 在一个语义空间中对不同物体的类别进行划分,将同类别的物体划分到一个地方。在这里面涉及到一个从属性到隐属性的问题,因为属性不足以进行很优的划分,而隐属性可以构建类别之间的联系且不同类在隐属性空间具有区分性。
- 同时,陈教授建立了一个视觉问答模型,用以验证系统的性能。这个视觉问答模型根据句子的文本特征,将单次级别的图像上下文特征组合成一个句子级别的视觉特征。
- 同时建立了视觉问答数据库,以及Scene-Attribute、Object-Scene关系示例图,作为数据支撑。
27号下午还有一些精彩的移动感知方面的报告,打算另外仔细的记录下来。详情可见会议总结(二)