最近在看动作识别的相关论文,其中有一篇名为two-stream convolutional networks for action recognition in videos的论文在做特征融合时使用到了FisherVector,之前没有接触过,所以搜了一下相关的帖子,看到一篇不错的转载过来,后期会对这篇论文写一下概要
这篇blog比较好的地方我认为是对GMM(高斯混合模型)以及似然函数(Likelihood Function)介绍的比较清楚,看过之后也确实对解决之前不了解的,存在疑惑的地方有所帮助
转自https://blog.csdn.net/shanyicheng1111/article/details/76978029
-------------------------------以下为原文-----------------------------
最近在研究动作识别(Action Recognize)领域的论文和方法。在视频动作识别领域,深度学习未进入前,传统方法最好的是iDT.
IDT采用FisherVector编码的方式比BOF(Bog of Features)提升了2%-10%.
BOF的编码方式,最终的视频特征维度是CodeBook的size大小。原理如图:)丑到不忍直视...

FiserVector编码方式,由两部分组成
首先是由样本分布估计GMM(高斯混合模型)参数,
然后用GMM模型对视频原始的iDT特征进行描述(编码)。
所以不管是BOF还是FisherVector都是相对于Codebook的一种描述。
GMM算法
GMM ,Gaussian Mixture Model,顾名思义,就是说该算法由多个高斯模型线性叠加 混合而成。GMM算法描述的是每一维数据的本身存在的一种分布,如果component足够多的话,GMM可以逼近任意一种概率密度分布。
我们知道,单个高斯模型的参数为均值和方差。
GMM是一种聚类算法,K代表用多少个高斯模型去描述数据分布。也就是说每个 GMM 由K个Gaussian分布组成,每个Gaussian称为一个“Component”,这些 Component 线性加成在一起就组成了 GMM 的概率密度函数:

根据数据来推算概率密度通常被称作 density estimation ,特别地,当我们在已知(或假定)了概率密度函数的形式,而要估计其中的参数的过程被称作“参数估计”。 表示第k个高斯模型的权重,
表示第k个高斯模型的权重, 是第k个高斯模型的均值。
是第k个高斯模型的均值。 是第k个高斯模型的方差。
是第k个高斯模型的方差。
在 GMM 中,我们就需要确定 、 和 这些参数。 找到这样一组参数,它所确定的概率分布生成这些给定的数据点的概率最大,而这个概率实际上就等于") ,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和
,我们把这个乘积称作似然函数 (Likelihood Function)。通常单个点的概率都很小,许多很小的数字相乘起来在计算机里很容易造成浮点数下溢,因此我们通常会对其取对数,把乘积变成加和") ,得到 log-likelihood function 。接下来我们只要将这个函数最大化,通常采用EM算法。
,得到 log-likelihood function 。接下来我们只要将这个函数最大化,通常采用EM算法。
进行GMM聚类后,得到的是K个高斯模型的参数,每个高斯模型的参数是 、 和 ,所以一共有3KD个参数。(其中D是原始数据的维度,因为每一个GMM是对每一维数据特征进行生成建模的)。
FisherVector编码
上述生成了GMM模型后,我们就可以在此基础上对原始数据特征进行编码。
定义fisher score:
X服从分布p,p的参数是(、 , k = 1...K)在fisher kernel中,p是一个GMM, 是一个视频的特征集合(iDT中D=426).这个log似然函数对 的梯度,描述了参数 在p生成特征点集合X的过程中如何作用,所以这个fisher score中也包含了GMM生成X的过程中的一些结构化的信息。所以有一种说法,FisherVector的本质是对高斯分布求偏导。
再定义特征由第i个Gaussian component生成的概率:
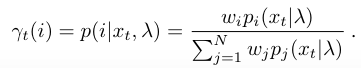
首先对参数求偏导可得到:
其中
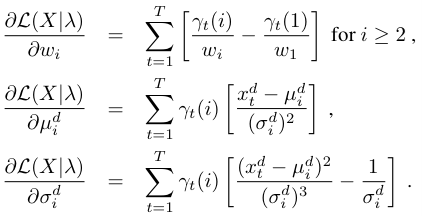
注意这里i是指第i个component,d是指特征 的第d维,偏导是对每个component,对特征每个维度都要计算,所以此时 的维度是(2D+1)*K,D是维度,K是component个数,wi是上述高斯混合模型中Gaussian 分布的权重。又由于 有约束,所以会少一个自由变量,所以 最终的维度是(2D+1)*K-1.
推导到这里,视频的原始特征iDT应该变为(2D+1)*K-1维FisherVector。在iDT论文中使用的是2DK维,可能是舍弃了高斯混个模型中对权重wi的求导。
参考博客 :
http://blog.csdn.net/happyer88/article/details/46576379
http://blog.csdn.net/ikerpeng/article/details/41644197
http://blog.pluskid.org/?p=39