hdfs shell的基本操作以及hdfsWeb查看文件
在安装好hadoop集群并成功的启动了hdfs之后,我们就可以利用hdfs对文件进行操作了,一下是对文件的一些基本操作
特别注意:访问HDFS目录时,一定要带有/ 否则命令会出错!
hdfs基本操作
1、查询命令
hdfs dfs -ls / 查询/目录下的所有文件和文件夹
hdfs dfs -ls -R 以递归的方式查询/目录下的所有文件
2、创建文件夹
hdfs dfs -mkdir /test 创建test文件夹
3、创建新的空文件
hdfs dfs -touchz /aa.txt 在/目录下创建一个空文件aa.txt
4、增加文件
hdfs dfs -put aa.txt /test 将当前目录下的aa.txt文件复制到/test目录下(把-put换成-copyFromLocal效果一样-moveFromLocal会移除本地文件)
5、查看文件内容
hdfs dfs -cat /test/aa.txt 查看/test目录下文件aa.txt的内容(将-cat 换成-text效果一样)
6、复制文件
hdfs dfs -copyToLocal /test/aa.txt . 将/test/aa.txt文件复制到当前目录(.是指当前目录,也可指定其他的目录)
7、删除文件或文件夹
hdfs dfs -rm -r /test/aa.txt 删除/test/aa.txt文件(/test/aa.txt可以替换成文件夹就是删除文件夹)
8、重命名文件
hdfs dfs -mv /aa.txt /bb.txt 将/aa.txt文件重命名为/bb.txt
9、将源目录中的所有文件排序合并到一个本地文件
hdfs dfs -getmerge / local-file 将/目录下的所有文件合并到本地文件local-file中
10、查看hadoop日志的方法 ---tail命令
tail -500 hadoop-root-resourcemanager-VM-0-10-ubuntu.log
11、关闭HDFS
可以使用下面的命令关闭HDFS。
$ stop-dfs.sh
hdfsWeb查看文件
1、概述:
在本地的浏览器输入namenode节点服务器的ip或域名+端口(例如:我namenode几点机器ip是132.232.28.164:9870),就可以看到hdfs集群的概述:

2、查看文件:
点击导航栏的Utilities按钮,选择查看文件或者日志,选择查看文件之后会出现以下的界面:
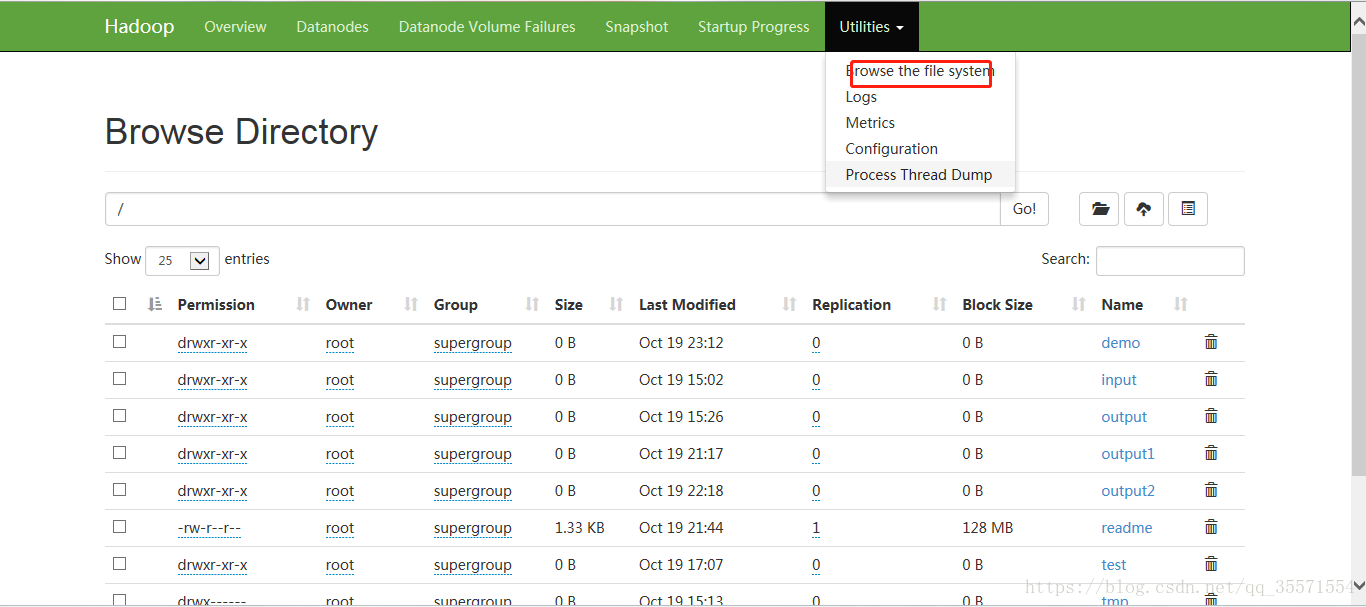
3、查看数据节点信息:
点击导航栏的Datanodes按钮,然后出现以下页面:
此时假如点击查看具体的数据节点的时候会报错,因为你windows操作系统不能识别node101~node103,此时需要配置下widows的hosts文件,配置完了就好了。hdfs的web操作就说这么多了,剩下的大家有兴趣可以去慢慢的看了