语音识别学习笔记(二)【基于矢量量化的识别技术】
- 概述
量化分为标量量化和矢量量化(Vector Quantization,VQ)。标量量化是将采样后的信号值逐个进行量化,而适量量化是将若干个采样信号分成一组,即构成一个矢量,然后对此矢量一次进行量化。矢量量化实际是一种极其重要的信号压缩的方法,广泛应用于语音编码,语音识别和合成,图像压缩等领域。 - 知识预备
VQ相当于一种逼近,类似于传统的四舍五入,如:

如上图所示,小于-2都量化成-3;-2和0之间的量化成-1;以此类推,任意一个输入都可以量化成-3,-1,1,3其中的一个,而这1dimension的四个数我们可以用2个bit表示,因此,量化速率为:2bit/dimension;
一个2dimension的VQ实例如下图所示:
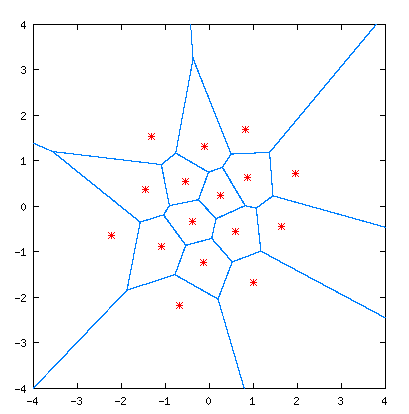
蓝线为编码区域,将空间划分为16个区域,每个区域的红星代表该区域的码矢,共16个;任意一个数据对(x,y)会落在与其“距离”最小的码矢所在的区域。这里,2 dimension的16个码矢,我们可以用4个bit来表示,因此,量化速率为2bit/dimension;另,码矢的集合叫做码书或码本,编码区域的集合叫做空间的划分。
3. VQ描述

4. 优化准则
1)最近邻原则 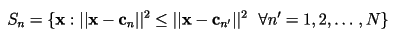
编码区域Sn应该包含所有与cn最接近的矢量(相比于与其他码矢的距离)。对于在边界(蓝色线)上面的矢量,需要采用一些决策方法(any tie-breaking procedure)。
2)质心原则 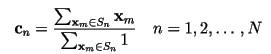
码矢cn是编码区域Sn内所有的训练样本向量的平均向量。在实现中,需要保证每个编码区域至少要有一个训练样本向量,这样上面这条式的分母才不为0。
5. K-means算法
1)初始化:选择合适的方法设置N个初始码本中心的码字ci,i ∈[1,N];
2)最近邻分类:将矢量源(训练数据)按照最近邻原则分配到“距离”最近的包腔内;
3)码本更新:然后,根据质心原则重新计算每一个包腔内的码字,生成新的码本;
4)结束:重复步骤2和3,直到相邻迭代误差的阈值达到一定要求。
6. LBG算法
K-means算法是在码书大小已知的情况下对样本聚类的方法,若不知码书大小,则需要用LBG算法:
1)初始化: N=1, 计算初始码本中心c1;
2)分裂: 将所有矢量源(训练数据)按照最近邻原则划分到N个包腔中,在对应的包腔中选择距离最远的两个训练数据矢量作为新的聚类中心,这样将N个包腔分裂成2N个包腔;
3)K-means:按照2N个包腔,执行K-means方法达到收敛得到2N个聚类中心;
4)结束:重复步骤2和3,直到达到要求的聚类中心个数或者误差达到要求。
7. 参考
[1] http://www.data-compression.com/vq.html
[2] LBG算法模拟动画:http://www.data-compression.com/vqanim.shtml
[3] LBG算法c语言实现:http://www.data-compression.com/lbgvq.c