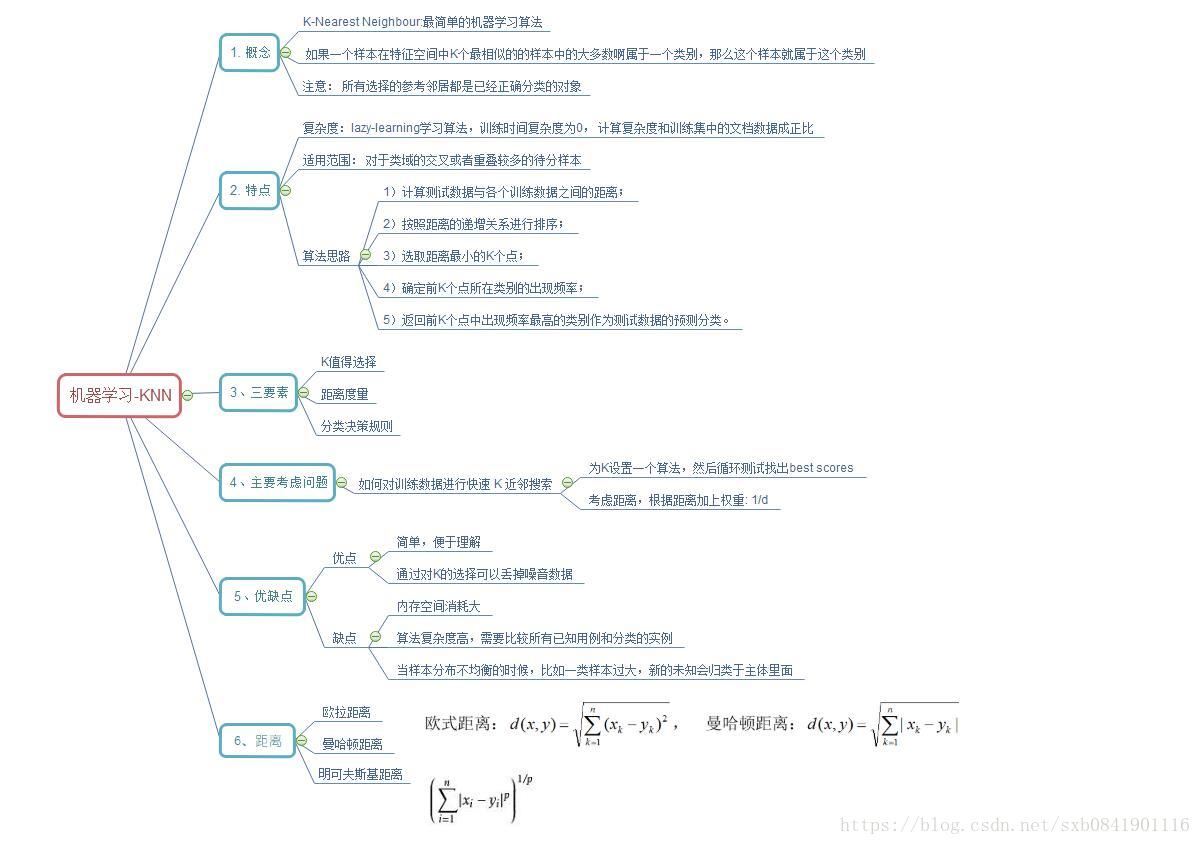
自己参考Bobo老师写得代码:
主要分为四个文件: knn.py中实现KNN算法、model_selection.py封装了样本数据的一些工具方法,比如切分为训练集和测试集;
metrics用来对模型进行评估、client用来调用算法进行运行
# -*- encoding: utf-8 -*-
"""
实现KNN的分类算法
"""
import numpy as np
from math import sqrt
from collections import Counter
from metrics import accuracy_score
class KnnClassifier(object):
"""
K-近邻算法,(K Nearest Neighbour),简称KNN
"""
def __init__(self, k):
"""
K表示
:param k: 表示参考的个数
"""
self.k = k
def fit(self, X_train, y_train):
"""
利用输入的样本集进行训练KNN算法
:param X_train: X 训练样本集
:param y_train: y
:return:
"""
self.X_train = X_train
self.y_train = y_train
return self
def predict(self, x_test):
"""
对于输入的测试样本x进行预测
:param x_test: 这个一个行向量
:return:
"""
assert x_test.shape[1] == self.X_train.shape[1], u'预测样本和训练样本的特征值不相等'
# step1 用欧几里得算法计算x与周边的距离
pridect_list = []
for one_x in x_test:
distances = [sqrt(np.sum((x - one_x) ** 2)) for x in self.X_train]
sorted_index = np.argsort(distances)
fit_y = self.y_train[sorted_index[:self.k]]
target_label = Counter(fit_y).most_common()[0][0]
pridect_list.append(target_label)
return np.asarray(pridect_list, dtype='int32')
def scores(self, y_pridect, y_test):
return accuracy_score(y_pridect, y_test)
def __repr__(self):
return 'knn(k=%s)' % self.kMetrics文件:
# -*- encoding: utf-8 -*-
"""
这个文件主要是计算一些指标比如准确度,用来评估算法的好还
"""
import numpy as np
def accuracy_score(y_test, y_pridect):
"""
用来计算准确度
:param y_test: 样本的标记测试集和
:param y_pridect: 预测集
:return:
"""
assert y_pridect.shape[0] == y_test.shape[0], u'测试集和预测集的数据个数不相等'
cnt = np.sum(y_test==y_pridect)
return cnt / len(y_pridect)
model_selection.py文件:
# -*- encoding: utf-8 -*-
"""
这个文件主要是计算一些指标比如准确度,用来评估算法的好还
"""
import numpy as np
def accuracy_score(y_test, y_pridect):
"""
用来计算准确度
:param y_test: 样本的标记测试集和
:param y_pridect: 预测集
:return:
"""
assert y_pridect.shape[0] == y_test.shape[0], u'测试集和预测集的数据个数不相等'
cnt = np.sum(y_test==y_pridect)
return cnt / len(y_pridect)
client文件进行测试:
from knn import KnnClassifier
from sklearn import datasets
from model_selection import train_test_split
from metrics import accuracy_score
import numpy as np
if __name__ == '__main__':
knn = KnnClassifier(3)
iris = datasets.load_iris()
x_train, y_train, x_test, y_test = train_test_split(iris.data, iris.target, 0.7)
classifier = knn.fit(x_train, y_train)
y_pridect = classifier.predict(x_test)
print(classifier.scores(y_pridect, y_test))