版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Knight_Key/article/details/83378185
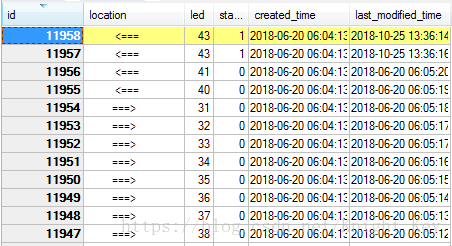
今天同事写了个删除重复数据保留一条记录的数据库语句,问我错在哪儿,正好给大家讲讲【注:以下语句只单对MYSQL数据库】
语句 -- 问题:
delete from `show`
where id not in
(
select MAX(id) from `show` where led = 43 and location = "<===" and status = 1
)
and status = 1SQL语句(查询)-- 正确:
select id from `show`
where id not in
(
select * from (
select id from `show` group by led,location,status
) b
)
and status = 1SQL语句(删除)-- 正确:
delete from `show`
where id not in
(
select * from (
select id from `show` group by led,location,status
) b
)
and status = 1有2个疑问点:
1、为什么要套这样一个select?因为 更新数据时使用了查询,而查询的数据又做更新的条件,mysql不支持这种方式
2、这句话中一定要取别名