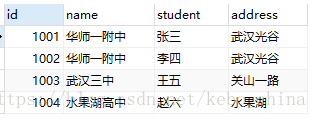
我们可以看出,name字段有重复数据,(华师一附中出现了两次),如何删除重复数据保留其中的一条呢?具体实现方案如下:
1.删除重复字段,保留id最小的一条
delete FROM `t_school_name` WHERE `name` in (select name from (SELECT `name` FROM `t_school_name` GROUP BY `name` HAVING COUNT( * ) >1) ) and id not in (select id from (select min(id) from t_school_name group by name having count(* )>1) )
先使用 group by having count(1)>1找出重复字段,然后删除数据,保留id最小的数据.
2.删除重复字段,保留id最大的以调
delete FROM `t_school_name` WHERE `name` in (select name from (SELECT `name` FROM `t_school_name` GROUP BY `name` HAVING COUNT( * ) >1) ) and id not in (select id from (select max(id) from t_school_name group by name having count(* )>1) )先使用 group by having count(1)>1找出重复字段,然后删除数据,保留id最大的数据.