-- 建表,插入测试数据
DROP TABLE IF EXISTS `table1`;
CREATE TABLE `table1` (
`id` int(11) NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of table1
-- ----------------------------
INSERT INTO `table1` VALUES (1, 'A');
INSERT INTO `table1` VALUES (2, 'B');
INSERT INTO `table1` VALUES (3, 'C');
INSERT INTO `table1` VALUES (4, 'D');
INSERT INTO `table1` VALUES (5, 'E');
INSERT INTO `table1` VALUES (6, 'A');
SET FOREIGN_KEY_CHECKS = 1;
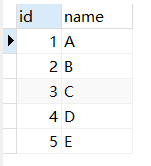
-- 所有数据
SELECT * FROM table1

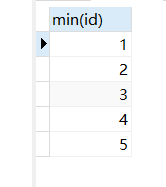
-- 分组查询数据,查询不重复数据得id
SELECT min(id) FROM table1 GROUP BY name
-- 执行删除,若提示> 1093 -- You can't specify target table 'table1' for update in FROM clause
DELETE from table1 where id not in
(SELECT min(id) FROM table1 GROUP BY name)

-- 则使用以下sql ,套层查询,及查询结果
DELETE from table1 where id not in
(select * from (
SELECT min(id) as id FROM table1 GROUP BY name)a
)