今天是周日,进博会的第一天。然而这与我没有很大关系,早上起来看了一会儿最优化方法,然后是去开组会。这是我开这么多次会议以来最开心的一次了,因为发挥了一下自己的作用,并且与老师同学们进行了交流。原来科研也可以不那么无趣,甚至给大家传授知识的时候也是超开心的。这周是gap周,主要是放松以及做好自己的定位,还有一个就是准备期中的考试。所以,下周计划就是周一到周四以准备考试为主,看同济那边的论文为辅,周五开始自己用tensorflow试着实现一个简单的gan网络,并且继续看论文找方向,多与老师和同学进行沟通交流。
今天和祺祺聊了一下,他现在做的事3D语义这块,很棒啊。还问了他要怎么学习“深度学习”。他说:“其实深度学习或者别的网络也好,就像搭积木一样,你看别人怎么搭,然后模仿着做。”其实学习也一样,输入的时候就是先看别人怎么做,然后自己在模仿别人怎么做,模仿是学习过程中非常重要的能力。其次,在学习的过程中还有一个非常重要的输出能力就是向小朋友说解释清楚一件事,什么意思呢?就是用最简单的语言把你想要表达的将给小朋友听,听懂了,你便也是真正理解透彻了。其实,这就是传说中的“费曼学习法”。
今天安排什么的都讲完了,谈谈我对gan的一些理解吧。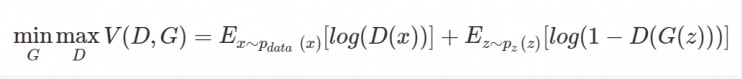
相信只要是了解一点点GAN的同学对这个目标函数都不陌生吧。D是判别器,G是生成器,我们的目标是最大化判别器,最小化生成器。这就好比造假,判别器用来判断这个东西是生成器造出来的还是它本来就是真的。在这样不断判别与造假中我们判别的能力在提升,同时造假的能力也在提升,在这个相互博弈的过程中不断优化生成器,使之与真实值不断接近,达到以假乱真的效果。训练GAN网络时,我们采取分而治之的发放,先训练k步判别器,然后在训练1步生成器,并且在训练时另一个保持不变。

引用原文的一张图来辅助大家理解,如上图所示,黑色的曲线时真实数据的分布,绿色的曲线是生成器生成的数据的分布,蓝色的曲线代表判别器判别的结果。图b表示训练判别器,生成器不动;图c表示训练生成器,判别器不动,最后到达图d生成器以假乱真的结果。
接下来我们思考一个问题:如果一开始判别器就已经非常好了,你给啥它都可以判别出来,那么你给它一堆垃圾,它也分分钟别你判别出来,然后如此反复就会到达一个两难的局面,判别器已经很好了,没有办法优化生成器,就起不到我们要优化生成器的效果了。那么这样我们该怎么办呢?答案可以在WGAN中寻找。
好啦,今天就到这里啦,只是小试牛刀的和大家讲讲GAN,没有那么深入,也不是那么易懂,但是,那又有什么关系呢,下一篇一定会更精彩,我是在一点点进步呀。