
''' 时间:2018/11/03 功能:bs4解析html 目录: 一: 学习使用 1 官网介绍 2 安装Beautiful Soup 3 四种对象 (1) 全部 (2) 标签 (3) 字符 (4) 注释 二: 实战使用 '''
一: 学习使用
1 官网介绍
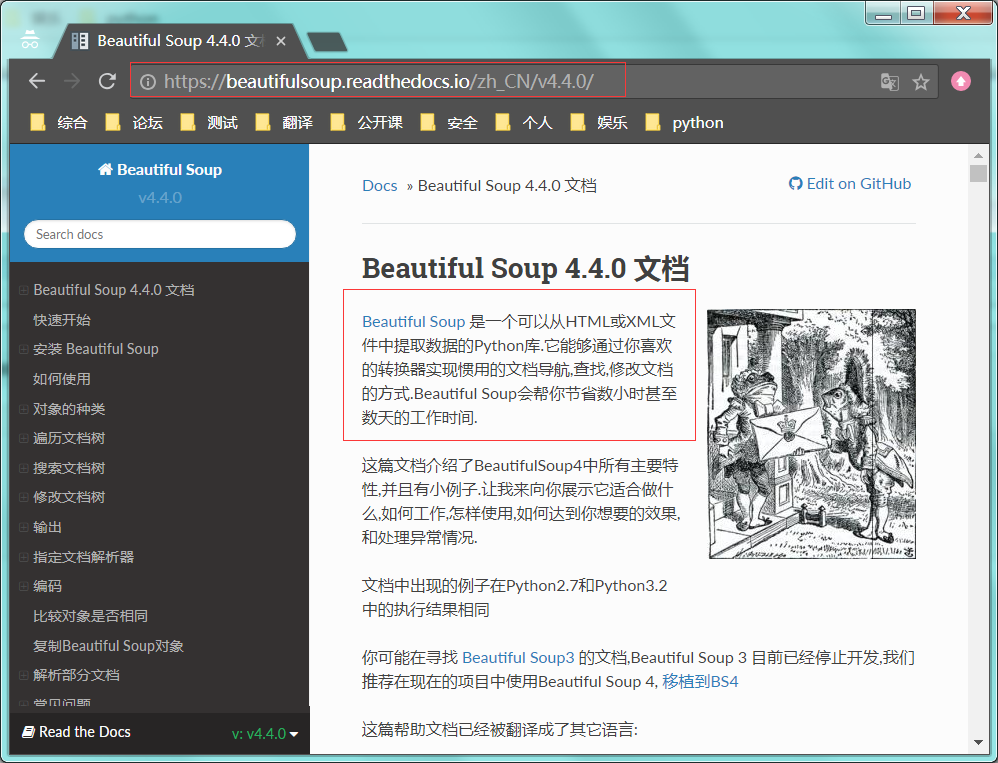
1 : 访问官网地址: https://beautifulsoup.readthedocs.io
2 : 可以查看介绍和使用。
2 安装Beautiful Soup
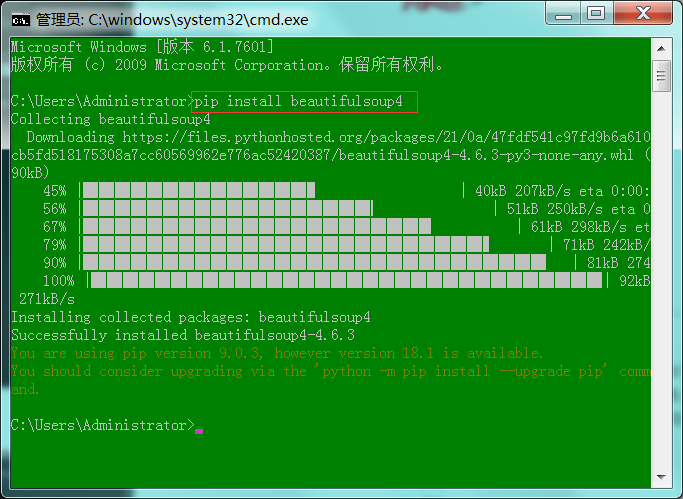
1 : 运行输入"cmd",进入Dos窗口。
2 : 输入"pip install beautifulsoup4"(安装beautifulsoup4模块)。
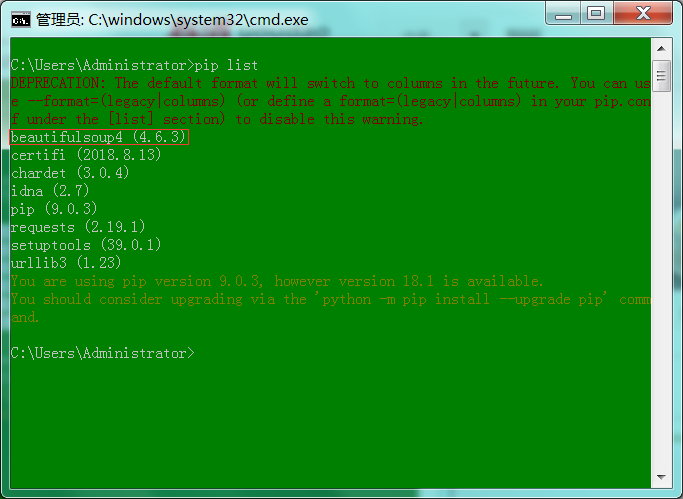
1 : 输入"pip list"(查看安装的库)。
2 : 可以看见已经安装了beautifulsoup4 (4.6.3)。
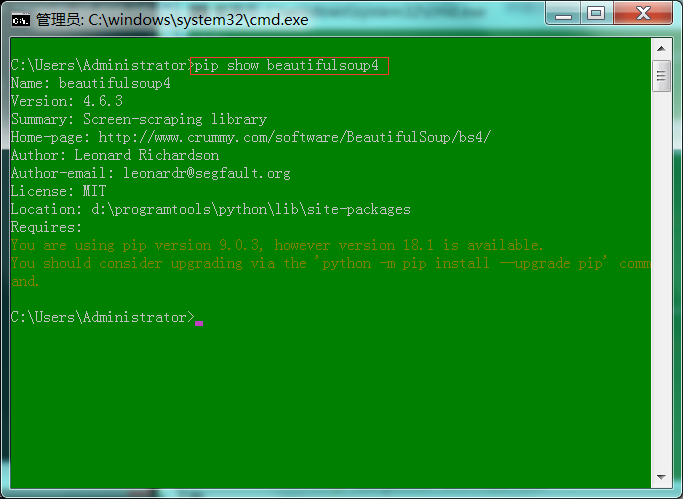
1 : 输入"pip show beautifulsoup4"(查看beautifulsoup4的信息)。
3 四种对象
(1) 全部
<meta charset="UTF -8"> <! -- for HTML5 -- > <meta http-equiv="Content-Type" content="text/html; charset=utf -8"/> <html> <head><title>汁虫</title></head> <body> <b><! -- Hey, this in comment!--></b > <p class="title"><b>汁虫</b></p> <a href="https://www.cnblogs.com/huafan/category/1264131.html class="sister" id="link1">fiddler</a>, <a href="https://www.cnblogs.com/huafan/category/1282855.html" class="sister" id="link2" >python</a>, <a href="https://www.cnblogs.com/huafan/category/1264133.html" class="sister" id="link3" >python</a>, 快来关注吧!</p> <p class="story">...</p>
1 : 使用这份html做测试文档,命名为"汁虫.html"。
# coding:utf-8 from bs4 import BeautifulSoup yo = open("汁虫.html", # 文件路径 - 同一级目录不需要写路径 "rb") # 打开方式 - 读取 # 全部显示 - html soup = BeautifulSoup(yo, # 文件的对象 "html.parser") # 解析器名称 print(soup, end="\n\n") # 打印内容 print(type(soup)) # 打印类型
<meta charset="utf-8"/> <!-- -- for HTML5 -- --> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"> <html> <head><title>汁虫</title></head> <body> <b><!-- -- Hey, this in comment!----></b> <p class="title"><b>汁虫</b></p> <a href="https://www.cnblogs.com/huafan/category/1264131.html class=" id="link1" sister"="">fiddler</a>, <a class="sister" href="https://www.cnblogs.com/huafan/category/1282855.html" id="link2">python</a>, <a class="sister" href="https://www.cnblogs.com/huafan/category/1264133.html" id="link3">python</a>, 快来关注吧!</body></html></meta> <p class="story">...</p> <class 'bs4.BeautifulSoup'>
(2) 标签
(3) 字符
(4) 注释
二: 实战使用