1、多目标优化的基本概念
多目标优化问题(MOP)可以被表示为:
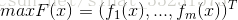
subject to

其中,
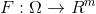
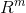

Pareto支配:

Pareto最优解:

Pareto最优解集:
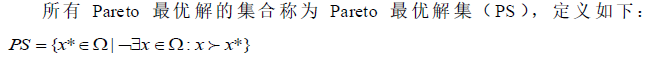
Pareto前沿面:

2、多目标进化算法的基本流程
多目标进化算法的种类很多,可以依据某一特征将它们分门别类。基于不同的选择机制,我们可以对其进行分类:
(1) 基于Pareto的方法(Pareto-based Approaches)
(2) 基于群体的方法(Population-based Approaches)
(3) 聚集函数(AggregatingFunctions)
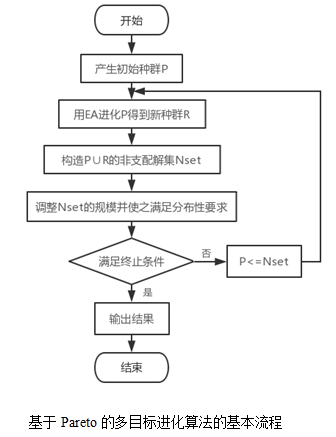
为了深入理解进化算法,我们给出了基于Pareto的MOEA的基本流程,如图2.1所示。首先初始化种群P,然后选择某一个进化算法(如基于分解的多目标进化算法,MOEA/D)对P执行进化操作(如选择、交叉、突变),得到新的种群R。然后构造P∪R的最优解集Nset,我们将最优解集的大小设置为N,如果当前最优解集Nset的大小与N的大小不一致,那么我们需要调整Nset的大小,同时必须注意调整过后的Nset需要满足分布性要求。之后判断算法终止条件是否已经被满足,如果不满足条件则将Nset中的个体复制到种群P中继续下一轮的进化,否则结束。我们一般用算法的迭代次数来控制它的执行。
在MOEA中,算法收敛的必要条件同时也是一个极其重要的方面是保留上一代的最优解集并将其加入新一代的进化过程。这样进化下去,进化种群的最优解集不断向真正的Pareto前沿面收敛,最终得到令人满意的进化结果。
3、多目标优化问题测试集
测试函数可以帮助我们更好地理解算法的优点和缺点,因此测试函数的选择对算法性能的理解与判断尤为重要。构造的简单性、对决策变量和目标数目的可扩展性以及对应于算法的收敛性与多样性均要设障等是选择测试函数时的重要参考依据。DTLZ测试集与WFG测试集是两个经常使用的多目标优化问题测试函数集。
Deb等人在2002年首次提出DTLZ测试函数集,并以共同研究者名字首字母命名(Deb,Thiele,Laumanns,Zitzler),根据不同难度的设置期望,2005年Deb等又在原有七个函数的基础上加入了两个测试函数,共同组成了DTLZ测试函数集。DTLZ测试函数集可以扩展至任意数量的目标(m>=2)并且可以有任意数目个变量(n>=m)。因为变量数与目标数易于控制,所以DTLZ函数集被广泛应用于多目标优化问题当中作为标准测试函数。
WFG测试函数集是Huband等人在2006年提出来的,一共包含9个测试问题,这些问题的目标数目都可以扩展到任意数量。和DTLZ测试函数集比起来,DTLZ问题的变量都是可分离的,因此复杂程度不高,而WFG测试问题的复杂程度更高、处理起来更具有挑战性。WFG测试问题的属性包括可分性或者不可分性、单峰或者多峰、PF形状为凸或者非凸、无偏差参数或有偏差参数。WFG测试函数集可以提供更有效的依据来评估优化算法在各种不同问题上的表现性能。
4、算法性能评价指标
通常在分析MOEA的性能时,我们希望算法在以下三个方面能够具有较好的性能。
(1) 真实的Pareto前沿面PFtrue与算法求解的得出的PFknown与之间的距离应该最小。
(2) 尽管搜索到的解点只是部分解,但最后求得的解点在Pareto最优解集中该均匀分布,在Pareto前沿面上的点也尽量呈现均匀分布。
(3) 在整个前沿上应该能够找出大量的解点,并且前沿上的各区域都应该有解点来代表,除非PFtrue上缺少这一区域。
我们一般认为上述指标当中的第一条是最重要的,因为MOEA的目标是找到一组近似解与真实前端的距离最近。
反向世代距离(Inverted GenerationalDistance):代表真实且均匀分布的Pareto最优解集P* 到算法得到的最优解集P 的平均距离,定义如下:

其中,种群P中个体到个体v之间的最小欧几里德距离用d(v,P)来表示;在真实PF上均匀选取一定数目的个体并将其用P*表示;该算法求得的最优解集用P表示。IGD为算法综合性能评价指标,反映了算法的分布性和收敛性,它是越小越好的。IGD值很小,说明算法求得的最优解集的分布性和收敛性都好。
超体积HV(Hypervolume):超体积指标度量的是通过多目标优化算法获得的非支配解集与参照点围成的目标空间中的维区域的体积。超体积的数学表示如下:
其中δ代表Lebesgue测度,用来测量体积。|S|表示非支配解集的数目,vi表示参照点z*与解集中第i个解构成的超立方体。HV是一个有效的一元质量度量指标,在Pareto支配方面是严格单调的,HV的值越大,表示对应算法的性能越好。此外,HV指标的计算不需要测试问题的理想PF,这一点在实践应用中大大方便了HV的使用。不过,HV指标存在两点限制:1)超体积的计算成本高;2)HV的值受选择的参照点影响大。