map原理图:
流程:
block数据: dear car bear car
map处理数据:按照空格进行分割,输出key-value格式,key为分割得到的字符,value为1
map处理后的数据: (dear,1),(car,1),(bear,1),(car,1)
shuffle:将相同的key放入到相同的reduce中
4个(Dear, 1)键值对,转换成[Dear, Iterable(1, 1, 1, )],作为两个参数传入reduce()
在reduce()内部,计算Dear的总数为4,并将(Dear, 4)作为键值对输出

转 https://blog.csdn.net/ych0112xzz/article/details/81186204
hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)
hive common join
hivesql会翻译成mr任务运行在yarn上
mapJoin
Map阶段
- 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
- Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
- 按照key进行排序
- 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
- Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
- 按照key进行排序
Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
以下面的HQL为例,图解其过程:SELECT a.id,a.dept,b.age FROM a join b ON (a.id = b.id);
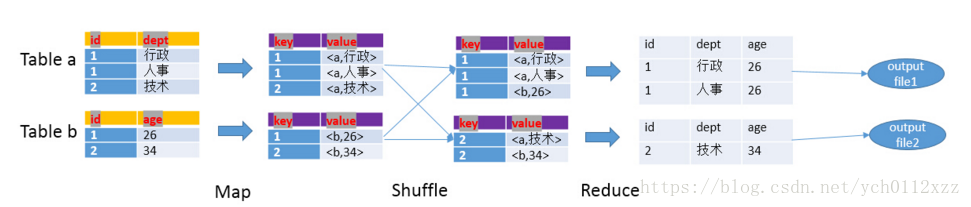
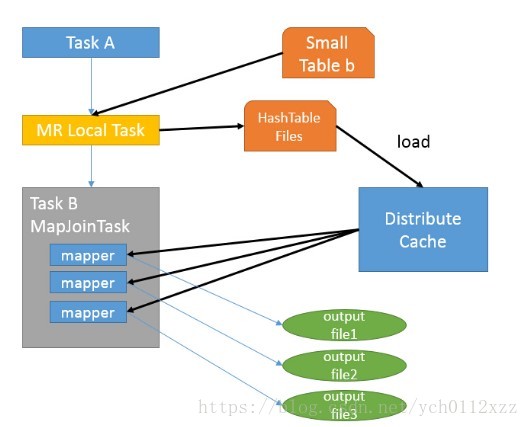
hive-map-join 假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
原因:节省了在Shuffle阶段时要进行的大量数据传输,省去了reduce运行
- 如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中,该HashTable的数据结构可以抽象为:
|key| value|
| 1 | 26 |
| 2 | 34 |- - 接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
- 由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件
hive group by原理
https://blog.csdn.net/u013668852/article/details/79866931
group by多字段 把groupby的字段组合作为map的key值
select rank, isonline, count(*) from city group by rank, isonline;将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下(当然这里只是说明Reduce端的非Hash聚合过程)
