在编写IO代码时,发现在读取含有中文字段的文本时,出现了乱码,所以就查找了一下解决办法,这里借用一下其他博主的总结:
转载地址:https://blog.csdn.net/qq_28950007/article/details/50760899
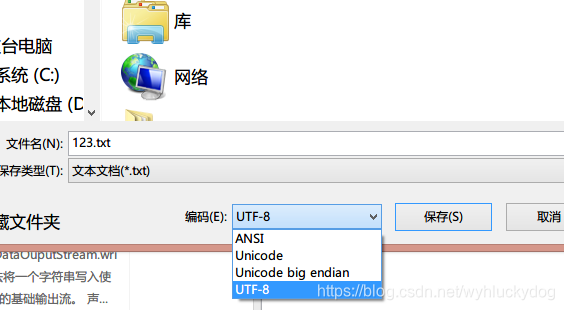
第一种方法:(不知道文件的编码),那通过"另存为"把你不知道的txt编码改为UFT-8,弄一个新的文件。
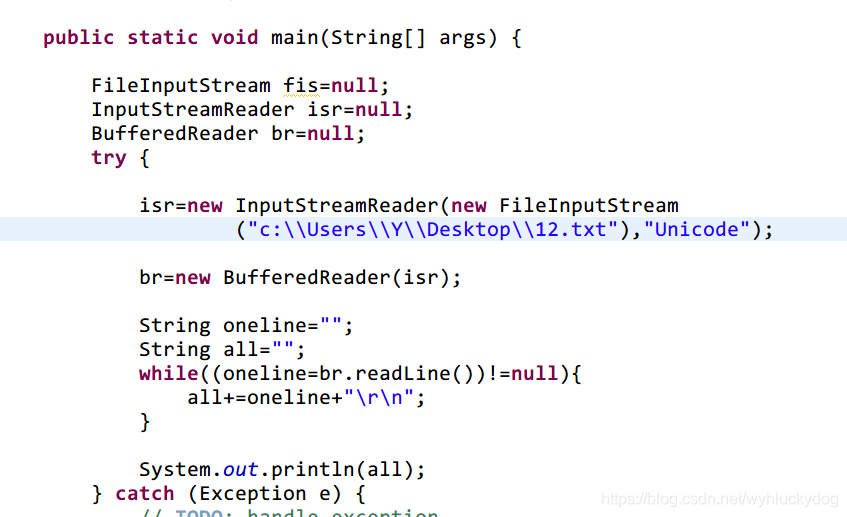
第二种方法,(知道文件的编码)用inputstreamreader读取,并用改编码形式读取。比如,原文件编码是Unicode:
具体解释,摘抄别的高手的如下:
Reader 类是 Java 的 I/O 中读字符的父类,而 InputStream 类是读字节的父类,InputStreamReader 类就是关联字节到字符的桥梁,它负责在 I/O 过程中处理读取字节到字符的转换,而具体字节到字符的解码实现它由 StreamDecoder 去实现,在 StreamDecoder 解码过程中必须由用户指定 Charset 编码格式。值得注意的是如果你没有指定 Charset,将使用本地环境中的默认字符集,例如在中文环境中将使用 GBK 编码。
Txt有四种编码:ANSI,Unicode, Unicode big endian,UTF-8
其中,ANSI又分很多种,有一种叫GBK;Unicode big endian又有很多种,有一种叫UTF-16BE。反正很乱,挑重要的了解就行了。
引用网友大神的获取txt编码的代码:

如果不知道编码是什么,或许可以把这段弄进去,自动获取。