#include<stdio.h>
#include<stdlib.h>//exit()函数的头文件
int main()
{
FILE* fp;
fp = fopen("text.txt", "r");
if (feof(fp))
{
printf("NULL");
exit(0);//表示如果读取为空文件就正常退出
}
char s[20];
fgets(s,20, fp);
puts(s);
fclose(fp);
}文件内容如下:

运行结果出现了乱码
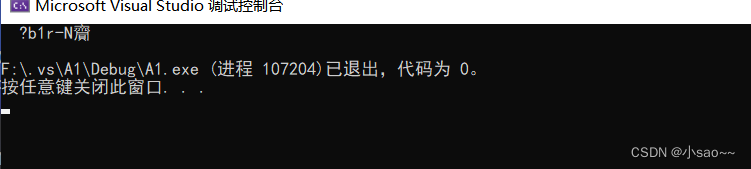
如果我们想读取文字,并且输出,我们可以打开文件然后另存为,再把文件编码改成ANSL,就不会出现乱码了。

如下所示,就不会出现乱码了。
补充内容:不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、Big5、Shift_JIS 等各自的编码标准。这些使用 1 至 4 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。 当然对于ANSI编码而言,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。这一点是ANSI编码与Unicode编码之间最大也最明显的区别。