最近突发奇想,想把以前用Matlab实现的对高频彩的开奖数据进行抓取并保存到本地的项目重新用python做一遍。加上前段时间学习的MySQL,想将读取回来的开奖数据存放到数据库里试试看。
废话不多说,实操看看。
网页下载器
这部分就比较简单了,不过值得一提的是,response需要encoding一下才能正常识别出内容,不然就是一大堆的乱码。
import requests
import re
class HtmlDownloader(object):
def download(self, url):
'''
实现对输入网址的数据请求以及处理响应内容并输出
:param url: 输入网址
:return: 响应的网页内容
'''
if url is None:
return None
user_agent = "Chrome/67.0.3396.99"
headers = {"User-Agent": user_agent}
signal = False
index = 0
# 这里我并没有设置timeout,因为采集数据过程不希望被超时打断,而是设置了while循环,以跳出信号或是连接次数判断跳出
while not signal:
try:
response = requests.get(url, headers=headers)
response.encoding = "utf-8"
signal = True
except:
print("连接失败,正在重新连接...")
index += 1
# 设置了5次重新连接的机会,5次都没有响应,就认倒霉吧,继续下一个页面好了
if index >= 5:
return None
return response.text
def dateChange(self, date):
'''
实现对日期格式的转换,输出格式为XXXXXXXX
:param date: 输入未处理格式的日期
:return: 输出所需格式的日期
'''
reg = re.compile(r"(\d{4})\D?(\d{2})\D?(\d{2})")
if reg.match(date) is not None:
result = reg.findall(date)[0]
return result[0] + result[1] + result[2]
else:
return None因为要爬取的网页http://caipiao.163.com/award/cqssc/XXXXXXXX.html,其中XXXXXXXX就是日期,例如20180501,所以网页下载器htmldownloader类的其中一个小方法就是日期转换datechange()。
网页解析器
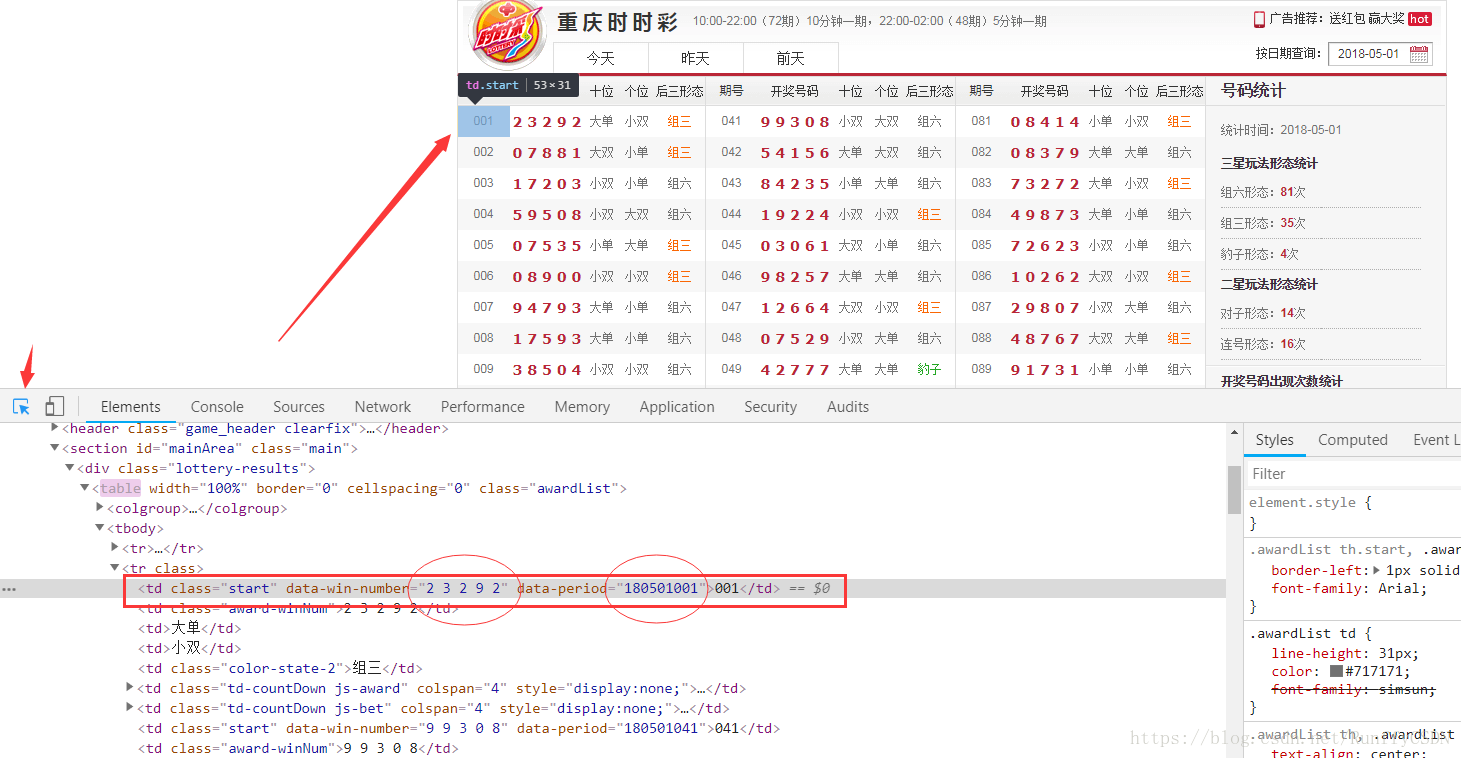
在网页点开F12,点击选取元素发现,在这样的class="start" 的td标签里面包含着两个我们想要的信息,开奖期号以及开奖号码。并且期数是以40为倍数3期3期第走的,得到的数据排列顺序是001,041,081,002,042,082....,所以网页解析器就可以这么写:
这里使用了bs4库中的BeautifulSoup模块,原本soup对象我是直接soup = BeautifulSoup(html_text)的,但是会有写法错误警告,虽然警告并不影响程序正常运行,但是处于强迫症,研究了一番,在后面加一个参数"lxml"就好了。
from bs4 import BeautifulSoup
import numpy as np
class HtmlParser(object):
def dataGet(self, html_text):
'''
解析并获取html_text中所需的内容
:param html_text: 网页内容
:return: data:numpy数组格式的数据,每个维度分别是开奖期号以及5个开奖号码
'''
if html_text is None:
return None
soup = BeautifulSoup(html_text, "lxml")
periods = soup.find_all('td', class_="start")
# per和data列表分别存储期号和开奖号
data = []
per = []
for period in periods:
per.append(period.get("data-period"))
data.append(period.get("data-win-number"))
# 如果data的长度为0,那就没有继续往下处理的必要了,直接return None
if len(data) == 0:
return None
# 把per和data交由专门对数据进行处理的私有方法去完成,将输出的内容return
return self._dataHandle(per, data)
def _dataHandle(self, periods, datas):
'''
对数据进行处理,该方法绑定dataget方法使用
:param periods: 期数
:param datas: 开奖号
:return: 处理后的numpy数组
'''
# 网页中的数据共120条,分3列,每列40个,读取到的开奖期号排列为001,041,081,002,042,082...以此类推
# 还没开,跳开,漏开的那一期对应的数据,会是一个空字符串或者是None,这些我们要跳过它们
jump = 3
tmp = []
for index in range(3):
for i in range(40):
if datas[i * jump + index] is None or datas[i * jump + index] == "":
continue
# 数据是一个以空格分隔的5个数字,所以要用split方法把5个数字切出来放到列表中
data = datas[i * jump + index].split(" ")
tmp.append([int(periods[i * jump + index]), int(data[0]), int(data[1]), int(data[2]), int(data[3]),
int(data[4])])
return np.array(tmp)数据存储器
这里使用了pymysql库
import pymysql
class DataMemorizer(object):
def __init__(self):
self.database = pymysql.connect("localhost", "root", "root", "cqssc")
self.cur = self.database.cursor()
def createTable(self, year):
'''
在数据库中创建新表
:param year: 年份,表的命名格式为“year+年份”,如year2018
:return:
'''
table_name = "year%s" % year
table = self._toChar(table_name)
if self._hasThisTable(table_name):
# 如果这个表已存在,直接返回
return table_name
# 主键字段dates,为日期,存放格式为XXXX的月日4位字符串
# reward存放当天一整天的开奖数据,是一个120*6的数组,数据类型设置为longblob,其实我觉得blob也可以
sql = "create table " + table + "(dates char(4) not null primary key, reward longblob not null) ENGINE=myisam DEFAULT CHARSET=utf8;"
self.cur.execute(sql)
self.database.commit()
print("创建新表:%s..." % table_name)
return table_name
def insertData(self, table_name, dateID, data):
'''
向数据库插入数据
:param table_name:表名
:param dateID: 主键值
:param data: 数据
:return:
'''
table = self._toChar(table_name)
date = self._toStr(dateID)
if self._hasThisId(table_name, dateID):
# 如果这个ID已经存在,跳转到修改数据方法
self.updateData(table_name, dateID, data)
else:
# 先要将numpy数组转换成二进制流,才能存到数据库中
b_data = data.tostring()
sql = "insert into " + table + " values(" + date + ", %s);"
self.cur.execute(sql, (b_data,))
self.database.commit()
print("已插入数据:%s." % dateID)
def updateData(self, table_name, dateID, data):
'''
更新数据库数据
:param table_name:表名
:param dateID: 主键值
:param data: 需要修改成的数据
:return:
'''
table = self._toChar(table_name)
date = self._toStr(dateID)
if not self._hasThisId(table_name, dateID):
# 如果没有这个主键值,那还改个屁,直接返回
return
# 同样也是将data这个numpy数组转换一下成二进制流数据
b_data = data.tostring()
sql = "update " + table + " set reward = %s where dates = %s;"
self.cur.execute(sql, (b_data, date))
self.database.commit()
print("已更新数据:%s..." % dateID)
def _hasThisTable(self, table_name):
'''
判断是否存在此表
:param table_name:表名
:return: True or False
'''
sql = "show tables;"
self.cur.execute(sql)
results = self.cur.fetchall()
for r in results:
if r[0] == table_name:
return True
else:
return False
def _hasThisId(self, table_name, dateID):
'''
判断在此表中是否已经有此主键
:param table_name: 表名
:param dateID: 主键值
:return: True or False
'''
sql = "select dates from " + table_name + ";"
self.cur.execute(sql)
ids = self.cur.fetchall()
for i in ids:
if i[0] == dateID:
return True
else:
return False
def _toChar(self, string):
'''
为输入的字符串添加一对反引号,用于表名、字段名等对关键字的规避
:param string:
:return:
'''
return "`%s`" % string
def _toStr(self, string):
'''
为输入的字符串添加一对单引号,用于数值处理,规避字符串拼接后原字符串暴露问题
:param string:
:return:
'''
return "'%s'" % string
def __del__(self):
'''
临走之前记得关灯关电关空调,还有关闭数据库资源
:return:
'''
self.database.close()
这里就有个地方磨了我很久,关于python对MySQL数据库写入二进制数据,存在以下这么些问题。在这里我创建了一个year2019的表用于演示。
首先,我要写入的是numpy数组,自然要先将numpy转换为二进制数据,那简单,用 .tostring()方法就行
# 1.导入模块
import pymysql
import numpy as np
# 2.连接数据库
db = pymysql.connect('localhost', 'root', 'root', 'cqssc')
# 3.创建游标
csr = db.cursor()
# 4.执行操作
arr = np.array([1, 2, 3, 4, 5])
b_arr = arr.tostring()
csr.execute("insert into year2019 values('1234', %s);", (b_arr))
db.commit()
# 5.打印结果
print(b_arr, type(b_arr))
# 6.关闭连接
db.close()测试运行结果


没有报错,到数据库里看看

这难道是西行取经的加上白龙马之后的师徒五人吗?没道理,那就再读出来看看吧
csr.execute("select reward from year2019 where dates='1234';")
c_arr = csr.fetchone()[0]
print(c_arr, type(c_arr))
既然可以读出来,那就这样吧哈哈哈,我一开始做的时候mysql可没有这么听话,各种报语法错误,算了,做出来就行。
数据获取器
这个数据获取器在这里就只贴上来其中一个功能,就是获取数据库中已有数据的最后一天的日期。其他的方法当然包含将数据库的数据取出来的还有其他的,但这里重点讲获取最后日期的方法。
import pymysql
import numpy as np
class DataGetter(object):
def __init__(self):
# 连接数据库,创建游标
self.database = pymysql.connect("localhost", "root", "root", "cqssc")
self.cur = self.database.cursor()
def getEndDate(self):
'''
获取目前已有数据的最后一天的日期
防止一段时间不爬取存在数据缺失
:return: 存在数据的最后一天
'''
# 先看一下所有表
sql = "show tables;"
self.cur.execute(sql)
tables = self.cur.fetchall()
length = len(tables)
if length == 0:
return None
# 通过表名后四位的数字,得到最大年份
for i in range(length):
if i == 0:
maxyear = int(tables[i][0][4:])
continue
if int(tables[i][0][4:]) > maxyear:
maxyear = int(tables[i][0][4:])
while True:
# 这里try是为了防止下面maxyear -= 1减到表名不存在而报错,表名不存在当然就是返回None
try:
table_name = "year" + str(maxyear)
sql = "select dates from " + table_name + ";"
self.cur.execute(sql)
except:
return None
values = self.cur.fetchall()
length = len(values)
if length > 0:
# 设置while True是为了防止第一次读取,有表但是数据为空,所以当有数据,就break
break
else:
maxyear -= 1
for i in range(length):
if i == 0:
maxday = int(values[i][0])
continue
if int(values[i][0]) > maxday:
maxday = int(values[i][0])
return str(maxyear) + self._dayToStr(maxday)
def _dayToStr(self,day):
day = str(day)
if len(day) == 4:
return day
return "0" + day处理过程比较冗杂,具体思路是先show tables,查看数据库中现有表名,去掉命名格式前面的year后int一下比较大小,取出最大的年份,然后读取那一年的表中的数据,如果没有数据,年数减一,如果在年数递减的过程中,出现不存在该表的情况,直接返回None,读取到数据的话就在读取到的数据中继续找出最大的一天,从而获得拥有数据的最后一天的日期并return返回。目的是为了在一段时间之后再次爬取,不会重复爬取过多的内容。
爬虫调度器
就是调度各单位工作的副总经理啦,责任巨大
from dataMemorizer.dataMemorizer import DataMemorizer
from htmlDownloader.htmlDownloader import HtmlDownloader
from htmlParser.htmlParser import HtmlParser
from dataGetter.dataGetter import DataGetter
import datetime
class SpiderMan(object):
def __init__(self):
self.memorizer = DataMemorizer()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.getter = DataGetter()
def crawlS(self):
endday = self.getter.getEndDate()
self._longCatch(endday)
def _longCatch(self, enddate=None):
'''
120期全数据抓取
:param enddate: 存在数据的最后一天的日期
:return:
'''
if enddate is not None:
enddate = self.downloader.dateChange(enddate)
date = datetime.datetime.now()
datenow = ""
# 因为这里datenow还不是正确的格式,所以就算日期相同,也可以往while循环里面进去一次,多更新一天的数据总是好的
index = 0
while not datenow == enddate:
datenow = date - datetime.timedelta(days=index)
datenow = datenow.strftime('%Y%m%d')
print("正在处理日期:%s......" % datenow)
url = r"http://caipiao.163.com/award/cqssc/%s.html" % datenow
html = self.downloader.download(url)
arr = self.parser.dataGet(html)
index += 1
# 每年中都会存在一段时间都不开的情况,如新年,貌似每年有那么8天是不开奖的
# 所以,为了防止误判,专门判断在无数据的情况下,年份如果小于2000年,那也没必要再往下爬数据了。
if len(arr) == 0:
if int(datenow[0:4]) <= 2000:
print("当日无数据且年份小于2000,停止执行")
break
else:
print("当日无数据,日期为%s,请查证,正在跳过此日数据..." % datenow)
continue
table_name = self.memorizer.createTable(datenow[0:4])
self.memorizer.insertData(table_name, datenow[4:], arr)
def __del__(self):
'''
总是要关灯关电关空调的,通过这个来间接性关闭数据库资源
:return:
'''
del self.memorizerif __name__ == "__main__":
spider = SpiderMan()
signal = spider.crawl()
del spider大概就是这样了,中间就数据库存储二进制数据的时候,因为各种语法上的错误卡了我好长时间。写个博客也写了一晚上,真失败。希望以后写的程序会越写越有干货。
【如有语法错误,欢迎在评论区纠正】