本篇博客所有示例使用Jupyter NoteBook演示。
Python数据处理系列笔记基于:Python数据科学手册电子版 下载密码:ovnh
示例代码 下载密码:02f4
目录
1.NumPy中的快速排序:np.sort和np.argsort
一、NumP简介
本篇博客将详细的介绍NumPy。NumPy(Numerical Python)提供了 高效存储和操作密集数据缓存的接口。在某些方面,NumPy数组与Python内置的列表类型非常相似。但是随着数组在维度上变大,NumPy数组提供了更加高效的存储和数据操作。NumPy数组几乎是整个Python数据科学工具生态系统的核心。因此,不管你对数据科学哪个方面感兴趣,花点时间学习NumPy是值得的。

获取更详细的文档以及教程资源,可访问http://www.numpy.org
二、理解python中的数据类型
Python的易用性在于动态输入。静态类型的语言如C、Java,每一个变量都要明确的声明他的类型,而动态语言Python不需要。例如用c和python分别实现100内的累加:
C:
int result = 0;
for(int i=0;i<100;i++)
{
result += i;
}Python:
result = 0
for i in range(100):
result += i最大的不同在于,c语言中,每个变量的数据类型要被明确的声明;而python中类型是动态推断的,可以将任何类型的数据赋给任何变量:
x = 4
x = 'four'但是这样在C中,就会报错:
int x = 4;
x = "four"; //编译失败Python的这种灵活性指出了一个事实:Python变量不仅是它的值,还包含了关于值的类型的一些额外的信息。
1.Python整型不仅仅是一个整型
标准的Python实现使用c语言编写的。这就意味了每一个Python对象都是一个伪C语言结构体,该结构体不仅包含其值,还有其他信息。
例如,我们在Python中定义一个整型:x=1000,x并不是一个“原生”整型,而是一个指针,指向一个C语言的复合结构体,里面包含了一些值。
查看Python3源代码,可以发现整型的定义包含四部分,如下所示:

- ob_refcnt是一个引用计数,帮助Python处理内存的分配和回收
- ob_type将变量的类型编码
- ob_size指定接下来数据成员的大小
- ob_digit包含我们希望Python变量表示的实际整型值
这意味着与C语言这样的编译语言中的整型相比,python中存储一个整型会有一些开销,如下图所示:
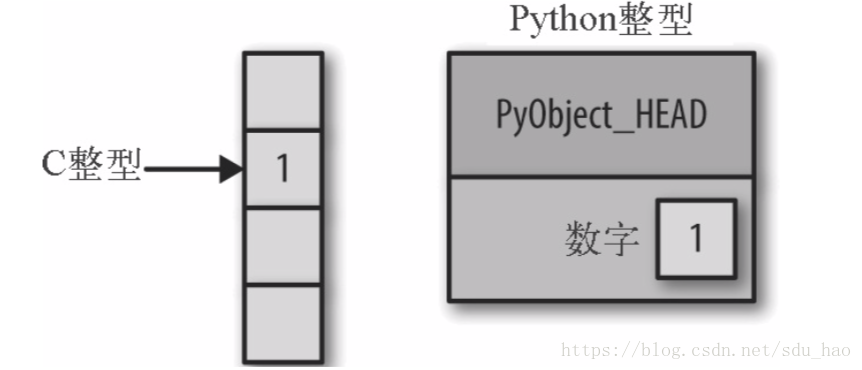
Python中存储整数1不仅要存储其值,还要存储类型等其他信息(这里的PyObject_HEAD是结构体中包含引用计数、类型编码和其他之前提到的内容)。
C整型和Python整型的区别:
C语言整型本质上对应某个内存位置的标签,里面存储的字节会编码成整型。而Python整型其实是一个指针,指向包含这个Python对象所有信息的某个内存位置,其中包括可以转换成整型的字节。由于Python的整型结构体里面包含了大量额外信息,所以Python可以自由、动态的编码。但是,Python类型中的额外信息也会成为负担,在多个对象组合的结构体中尤其明显。
2.Python列表不仅仅是一个列表
在之前的博客中我们曾经学习过Python列表类型,忘记的可以复习一下:列表简介和操作列表。
- 整型列表:

- 字符串列表:

- 因为Python的动态类型特性,可以创建一个异构的列表

但是Python的这种灵活性是要付出代价的,为了获取灵活的类型,列表中的每一项必须包含各自的类型信息,引用计数和其他信息,每一项都是一个完整的Python对象。那么如果列表中的所有变量都是同一类型,这时很多信息都是多余的。因此,将数据存储在固定类型的数组中会更高效。
动态类型的列表和固定类型的数组(NumPy)的区别:
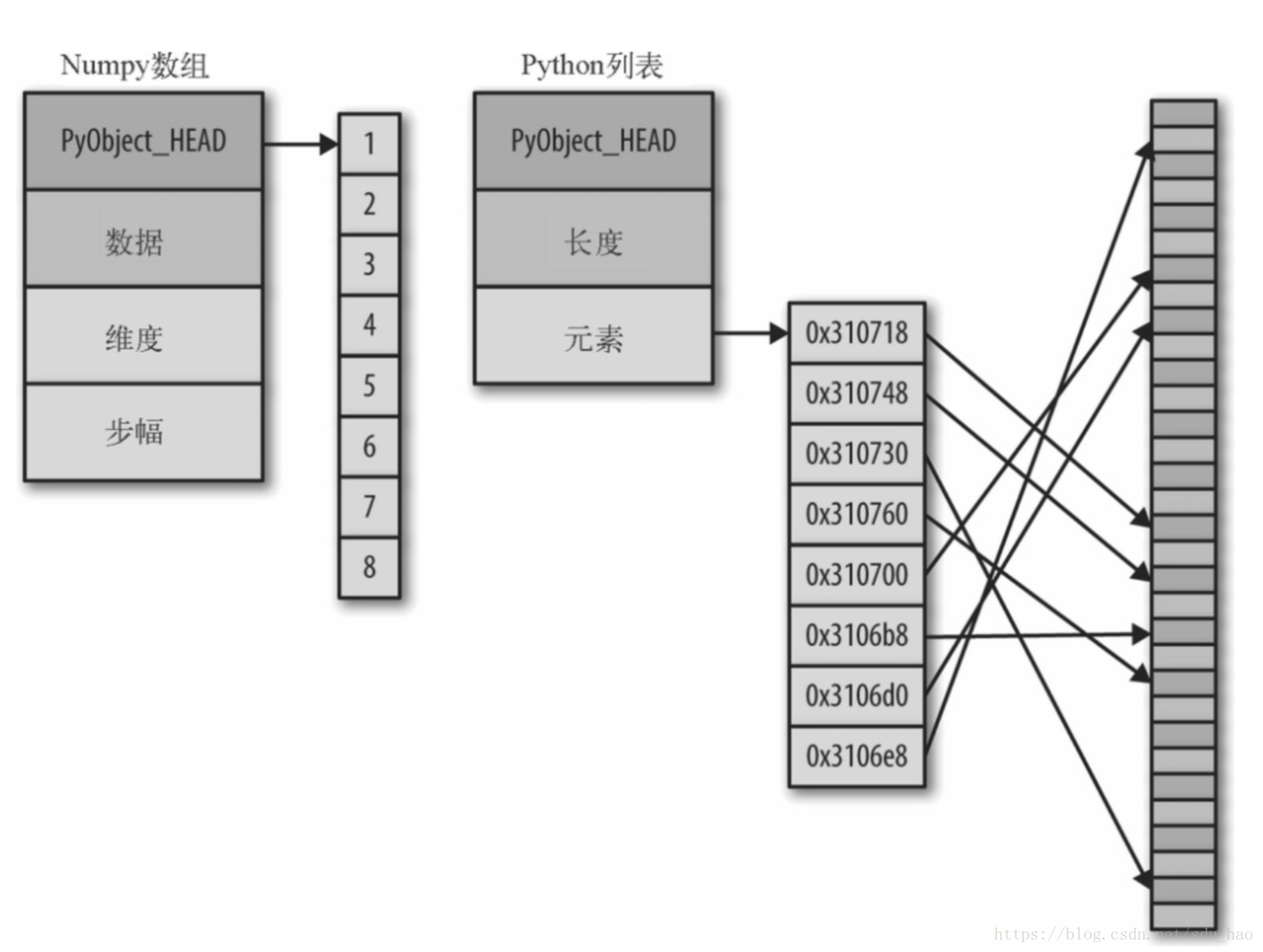
实现层面,数组基本上包含一个指向连续数据块的指针。Python列表包含一个指向指针块的指针,其中的每一个指针对应一个完整的Python对象(前面看到的Python整型结构)。另外,列表优势是灵活,每个列表元素是一个包含数据和类型信息的完整结构体,因此列表可以用任意类型的数据填充。固定类型的NumPy数组缺乏这种灵活性,但能更有效的存储和操作数据。
NumPy数组相当于C语言中的列表。
3.Python中的固定类型数组
内置的数组(array)模块可以用于创建统一类型的密集数组:

这里的‘i’是一个数据类型码,表示数据为整型。
更实用的是NumPy包中的ndarray对象。Python的数组对象提供了数组型数据的有效存储,而Numpy为该数据加上了高效的操作,之后会介绍。
4.从Python列表创建数组
使用np.array().

注意,不同于Python列表,NumPy要求数组必须包含同一类型的数据。如果类型不同,会自动向上转换(可行的话).
比如:整型转浮点型

如果希望明确设置数组的数据类型,可用dtype:

不同于Python列表,NumPy数组可以是多维的,用嵌套列表初始化多维数组:

内层列表当作二维数组的行。
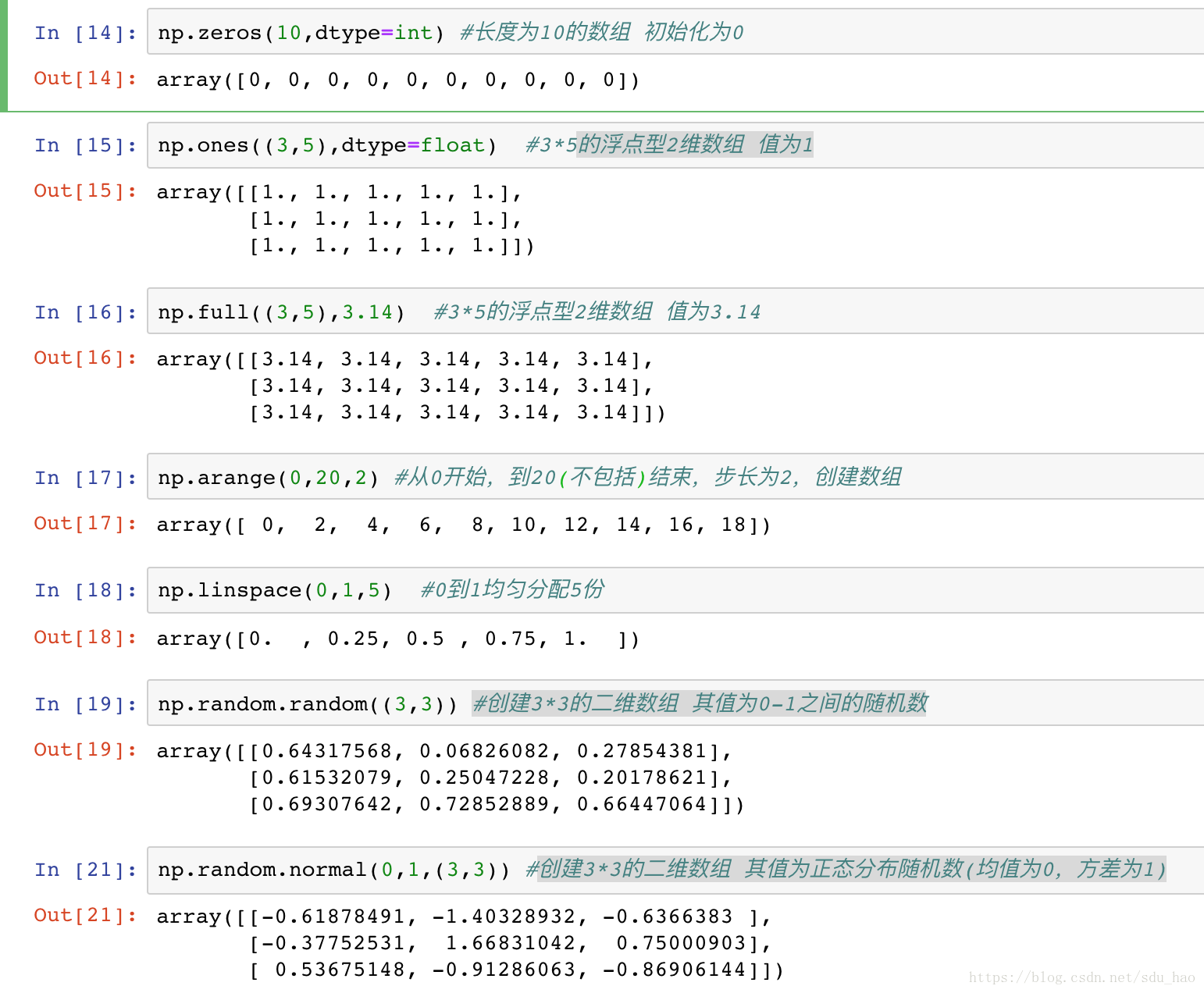
5.从头创建数组
面对大型数组时,用Numpy内置的方法创建数组更高效。

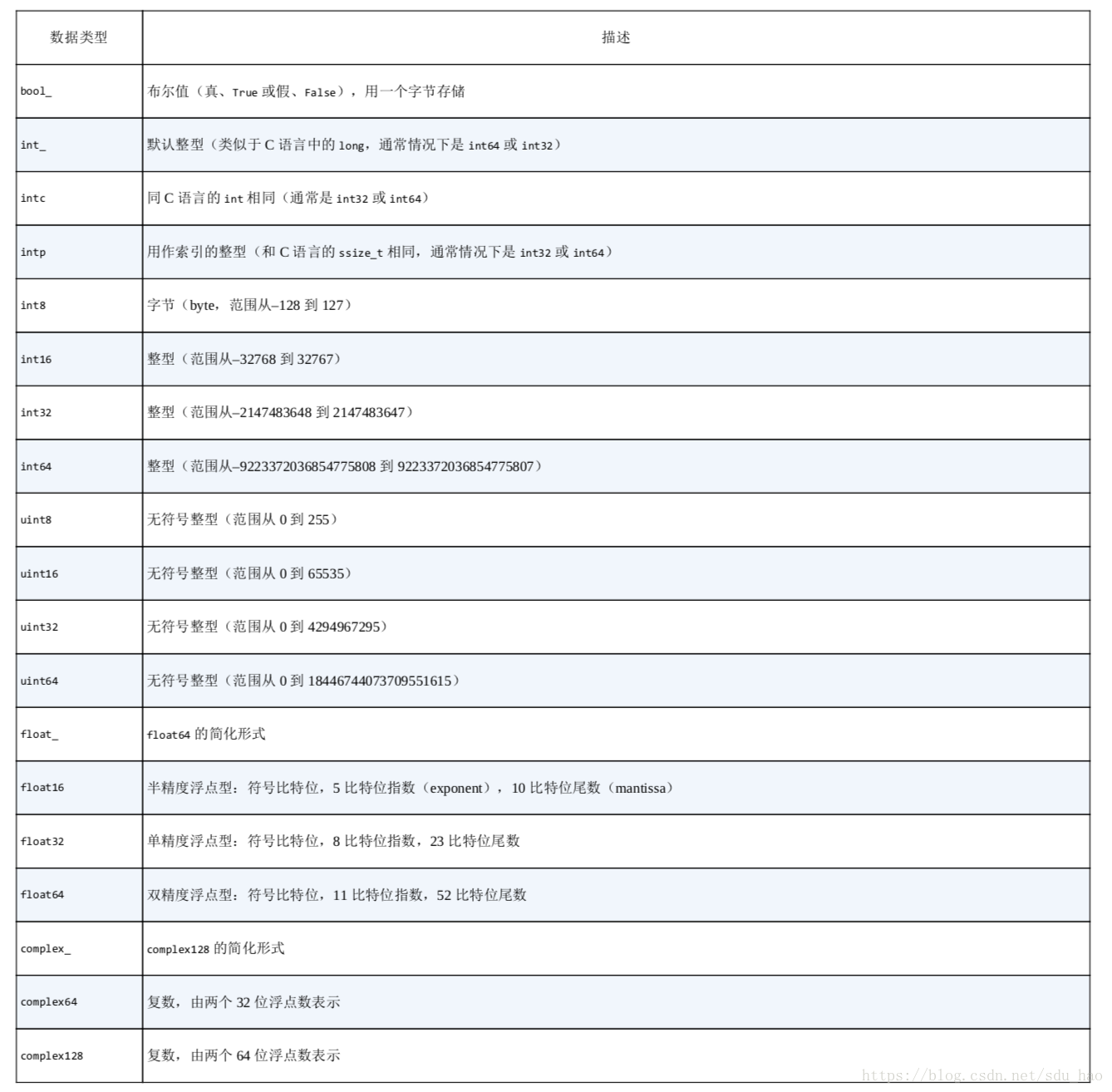
6.NumPy标准数据类型
Numpy数组包含同一类型的值,Numpy是基于c语言开发的。
创建数组时可以用一个字符串指定数据类型,或者用相关Numpy对象指定:
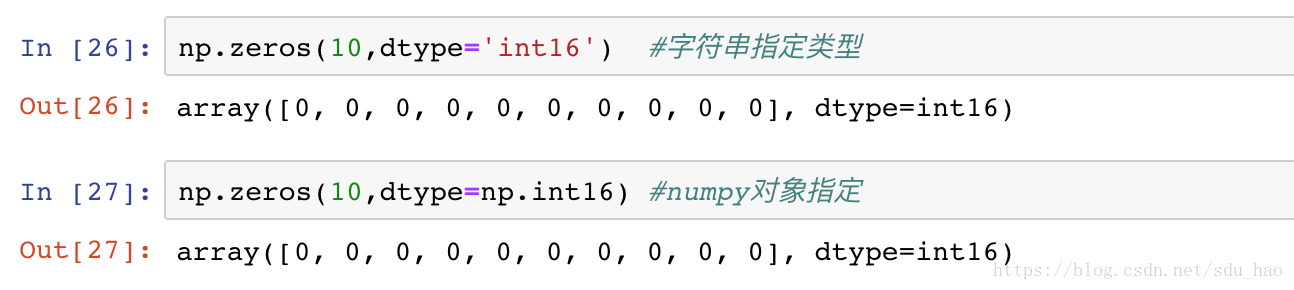
NumPy标准数据类型:
三、NumPy数组基础
1.NumPy数组属性
定义三个随机数组,分别是1维,2维和3维:

2.数组索引:获取单个元素
数组的索引和Python列表一样,都是用[]指定索引来获取(从0开始):

多维数组中用,分隔的元组作为索引(从0开始):

也可以通过索引来修改数组的值:

注意:Numpy中元素类型是一样的,如果你把一个浮点数插入整型数组,浮点数会自动截断,且不报错

3.数组切片:获取子数组
数组切片的语法与Python列表切片一样,切片用:表示。
语法:
x[start:stop:step]开始索引:结束索引(不包括):步长,start默认为0,stop默认为数组大小,step默认为1
- 一维子数组
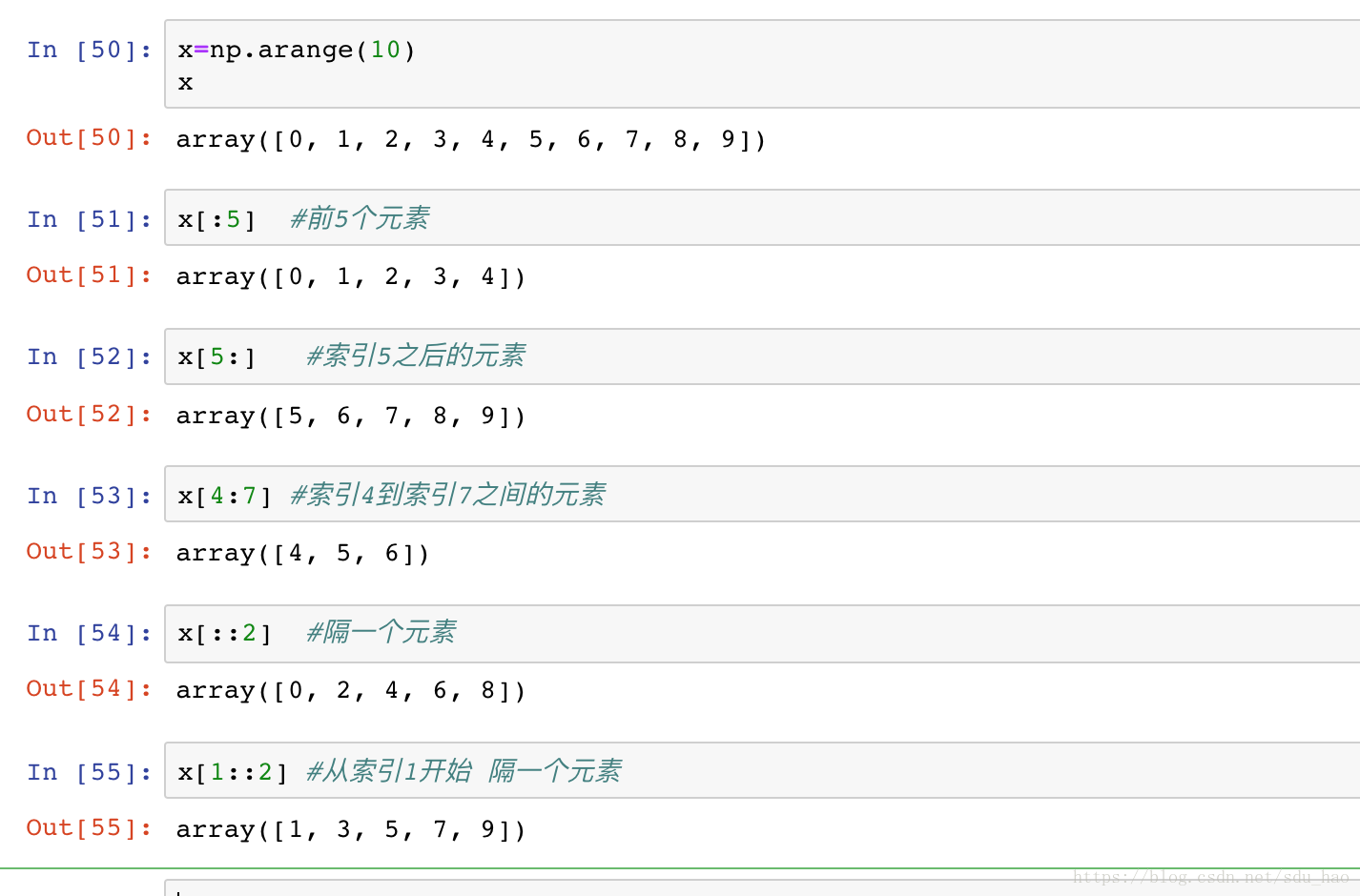
步长可以为负数,start和stop参数此时默认为交换的,是一种逆序数组的方法:

- 多维子数组

- 获取数组的行和列
获取数组的单行或单列,可以将索引和切片结合来实现,:表示空切片

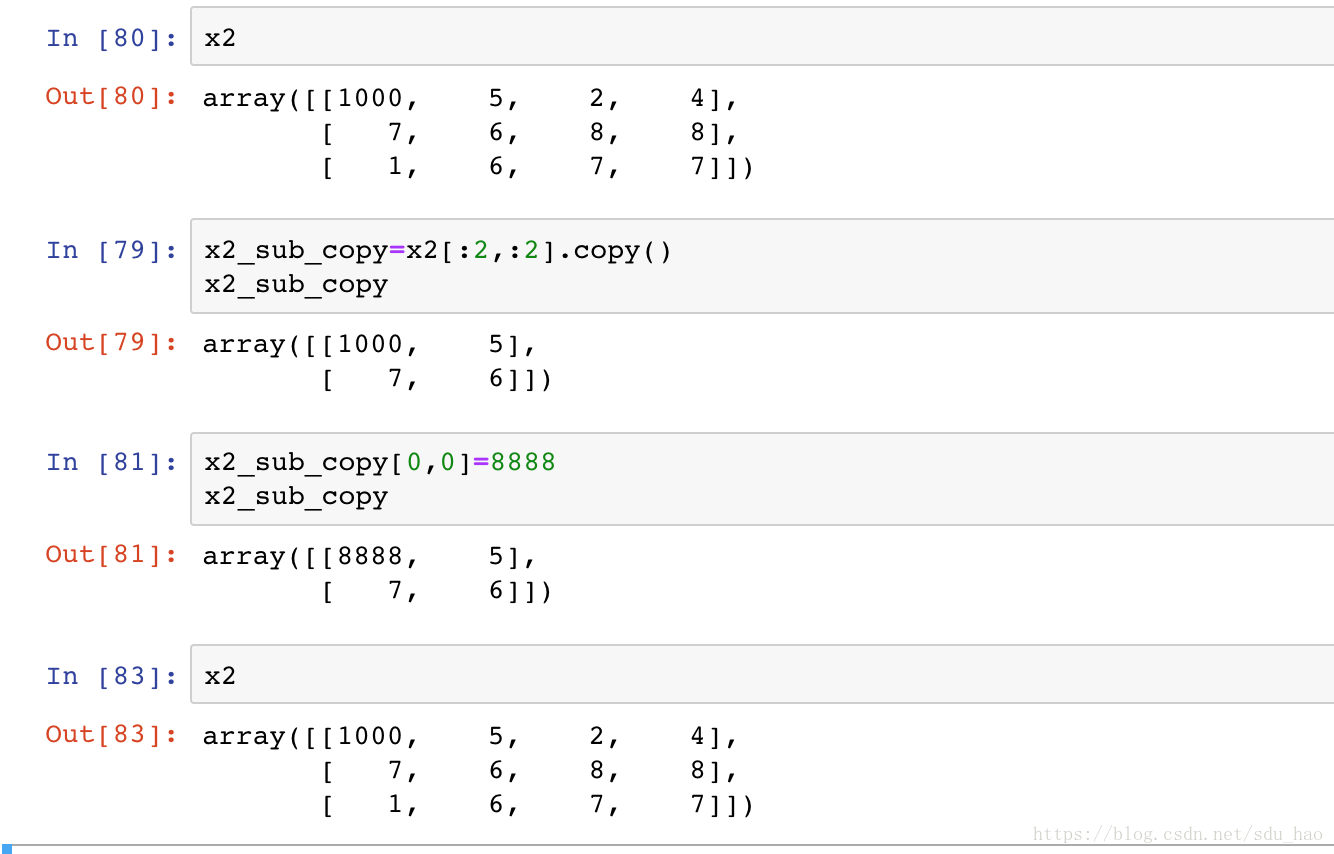
- 非副本视图的子数组
数组切片时原数组的视图,也就是说切片改变了,原始数组对应位置也改变;和Python列表不一样,列表切片是列表的一个副本,二者没关系。

这种默认处理方式很有用:在处理大数据集时,可以获取或处理数据集的切片,来完成对大数据集的处理,不用复制底层的数据缓存。
- 创建数组副本
4.数组的变型

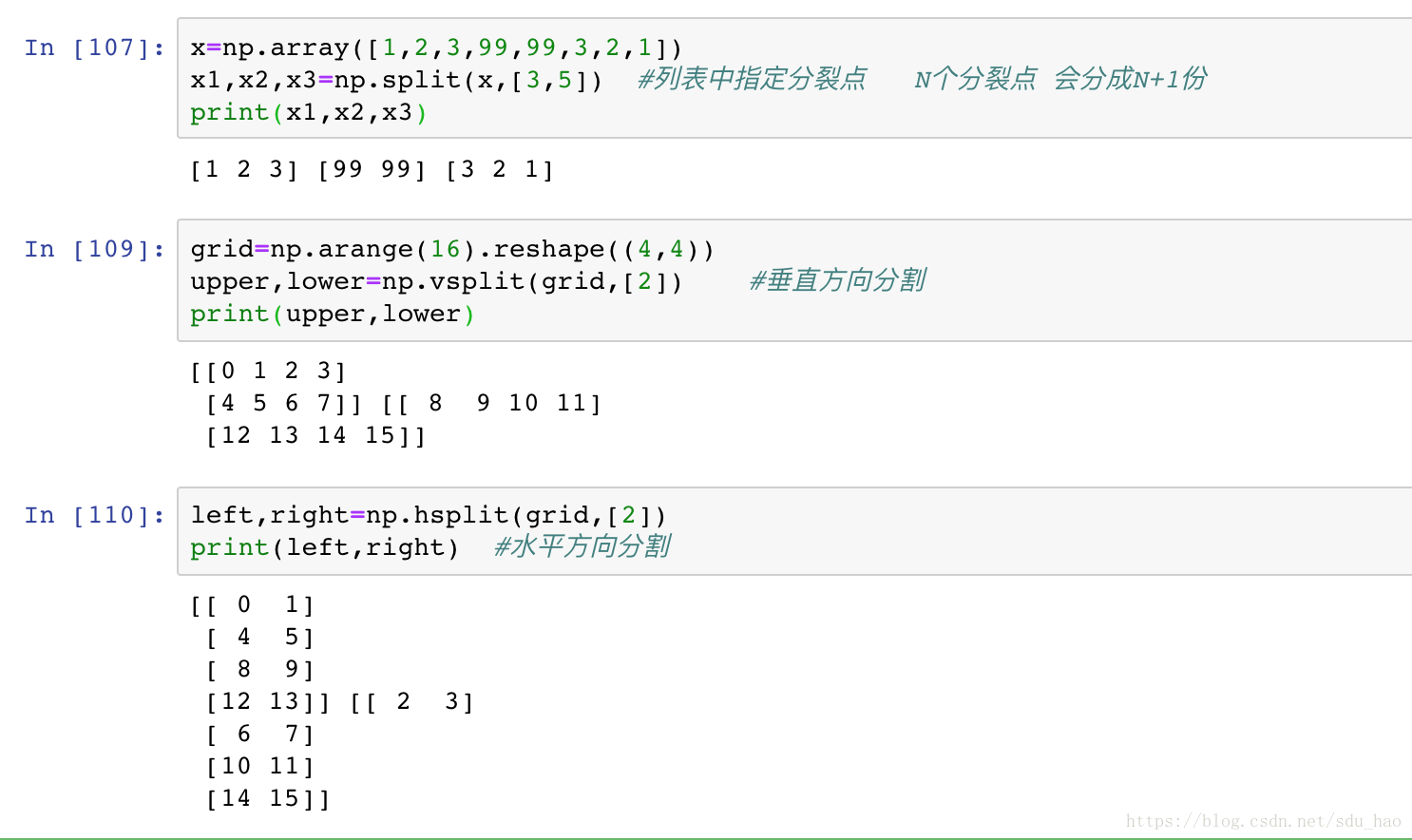
5.数组的拼接和分裂
- 数组的拼接
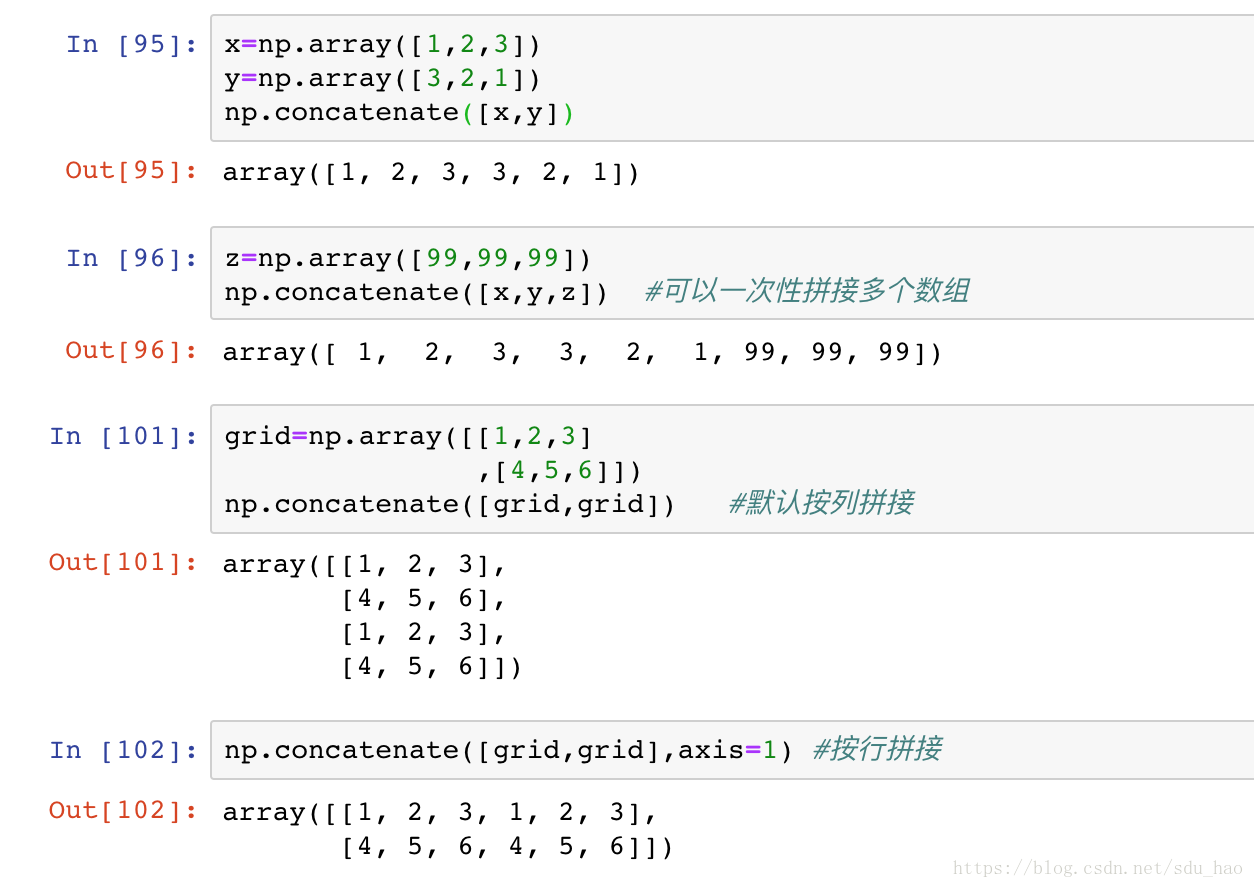

- 数组的分裂
四、Numpy数组的计算:通用函数
1.缓慢的循环
Python的相对缓慢通常出现在很多小操作需要不断重复的时候,比如对数组中的每个元素做循环操作。假设有一个数组,计算其中每个元素的倒数:

这种实现方式对有C或Java背景的人来说很自然,但当数据量很大时,计算会非常慢。我们用Ipython的%timeit魔法函数来测量:

完成百万次上述操作需要几秒,是非常慢的。事实上,处理瓶颈不是运算本身,而是在每次循环时必须做数据类型的检查和函数的调度。每次进行倒数运算,Python首先检查对象的类型,并且动态查找可以使用该数据类型的正确函数。如果我们能在编译代码时进行这样的操作,那么就能在代码执行之前知晓类型声明,结果计算会更有效率。
2.通用函数介绍
NumPy为很多类型的操作提供了静态类型的、可编译程序的接口,也称为向量操作。可以简单的对数组执行操作来实现,对数组的操作将会被用于数组中的每一个元素。
这种向量方法被用于将循环推送到NumPy之下的编译层,这样执行效率非常高。
比较循环和向量化方法:

向量化方法与Python循环速度比较:只需要几毫秒,比循环快很多

NumPy向量操作通过通用函数实现。通用函数主要对NumPy数组中的值执行更快的重复操作。适用于标量与数组的运算,也适用于数组与数组的运算,数组可以是一维也可以是多维。

3.探索NumPy通用函数
主要有两种形式:一元通用函数对单个输入进行操作,二元通用函数对两个输入操作。
- 数组的运算

所有算术运算符都是NumPy内置函数的简单封装,+运算符就是add函数的封装:

NumPy实现的算术运算符:

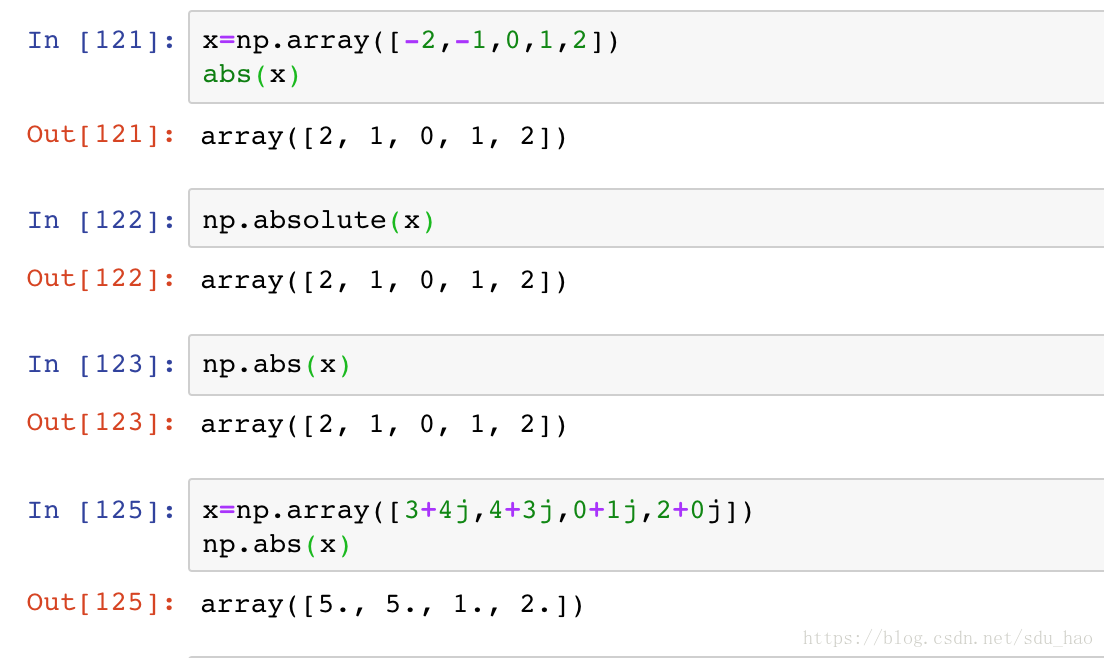
- 绝对值
Python中内置的绝对值函数为abs(),在NumPy中也能用;NumPy绝对值通用函数为np.absolute(),别名np.abs(),并且可以处理复数,绝对值返回其幅度:
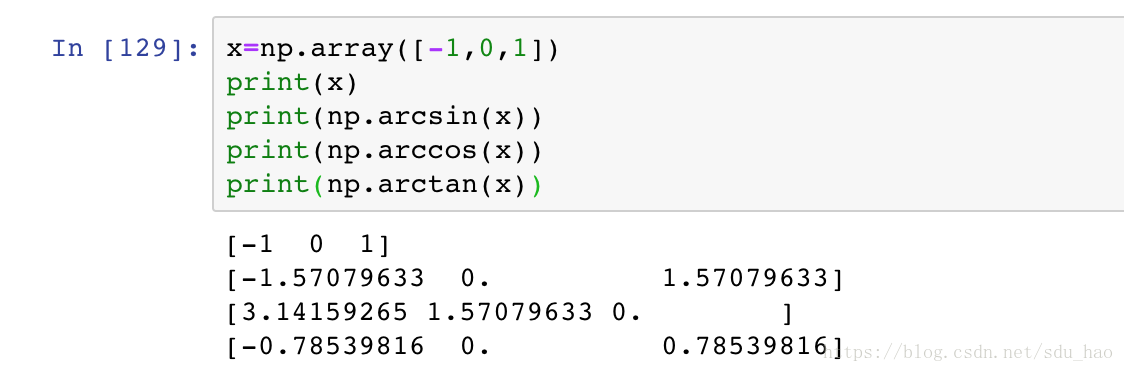
- 三角函数

反三角函数同样可以使用:
- 指数和对数


x的值非常小时,下列函数给出的值更精确:

- 专用的通用函数
除了上述函数,NumPy还提供了很多通用函数,包括双曲三角函数、比特位运算、比较运算符、弧度化角度,取整,求余等。可以浏览NumPy文档。
子模块scipy.special包含一些晦涩的通用函数,下面举几个例子:


4.高级的通用函数特性
- 指定输出
大量运算时,指定一个用于存放运算结果的数组很有用。不同于创建临时数组,可以用这个特性将结果直接写入你期望的存储位置。
所有通用函数都可以通过out参数指定结果的存放位置。

也可被用做数组视图,例如将结果写入指定数组每隔一个元素的位置:
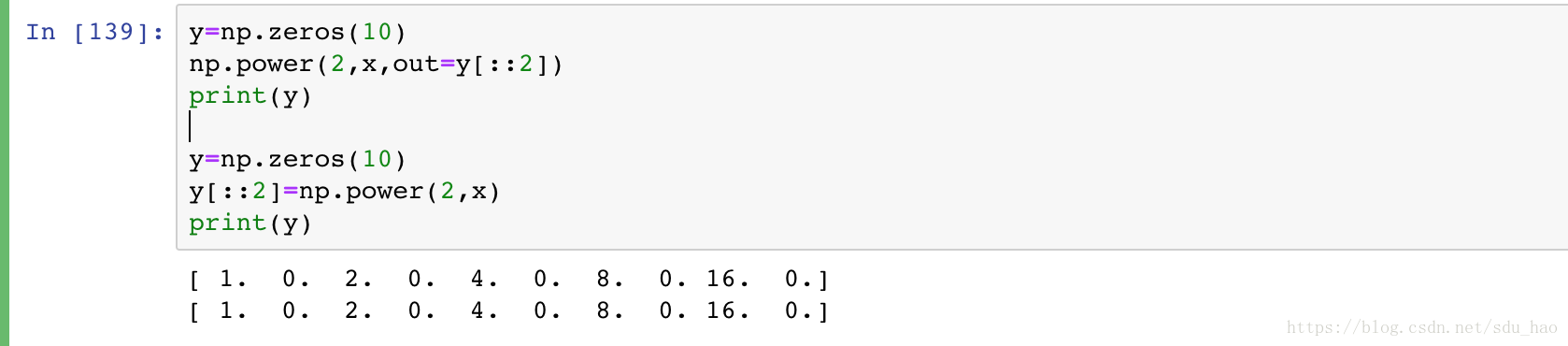
虽然上述两种方式的结果相同,但是第二种方式,将会创建一个临时数组,存放指数运算的结果,再将结果复制到y数组中。计算量小,二者相差不大;但是计算量大时,使用out参数可以节约内存。
- 聚合
二元通用函数有聚合功能,可直接在对象上计算。例如:用一个特定的运算reduce一个数组,可以用任何通用函数的reduce方法。
reduce方法对特定元素和操作重复执行,直到得到单个结果:

存储每次计算的中间结果,可以用accumulate:

- 外积
任何通用函数都可以用outer获取两个不同输入数组所有元素对的函数运算结果:

5.通用函数:更多信息
五、聚合:最小值、最大值和其他值
1.数组值求和
可以使用Python内置的sum(),或者Numpy中np.sum(),二者 的参数是不同的,NumPy更快:
2.最小值和最大值
Python内置的min()和max()函数:

Numpy也有min()和max(),速度更快:

更简洁的写法,NumPy中的聚合函数都可以这样写:

- 多维度聚合
在2为数组中沿一行/列聚合:

- 其他聚合函数
3.示例:美国总统身高
美国总统身高数据集 下载密码:95f8

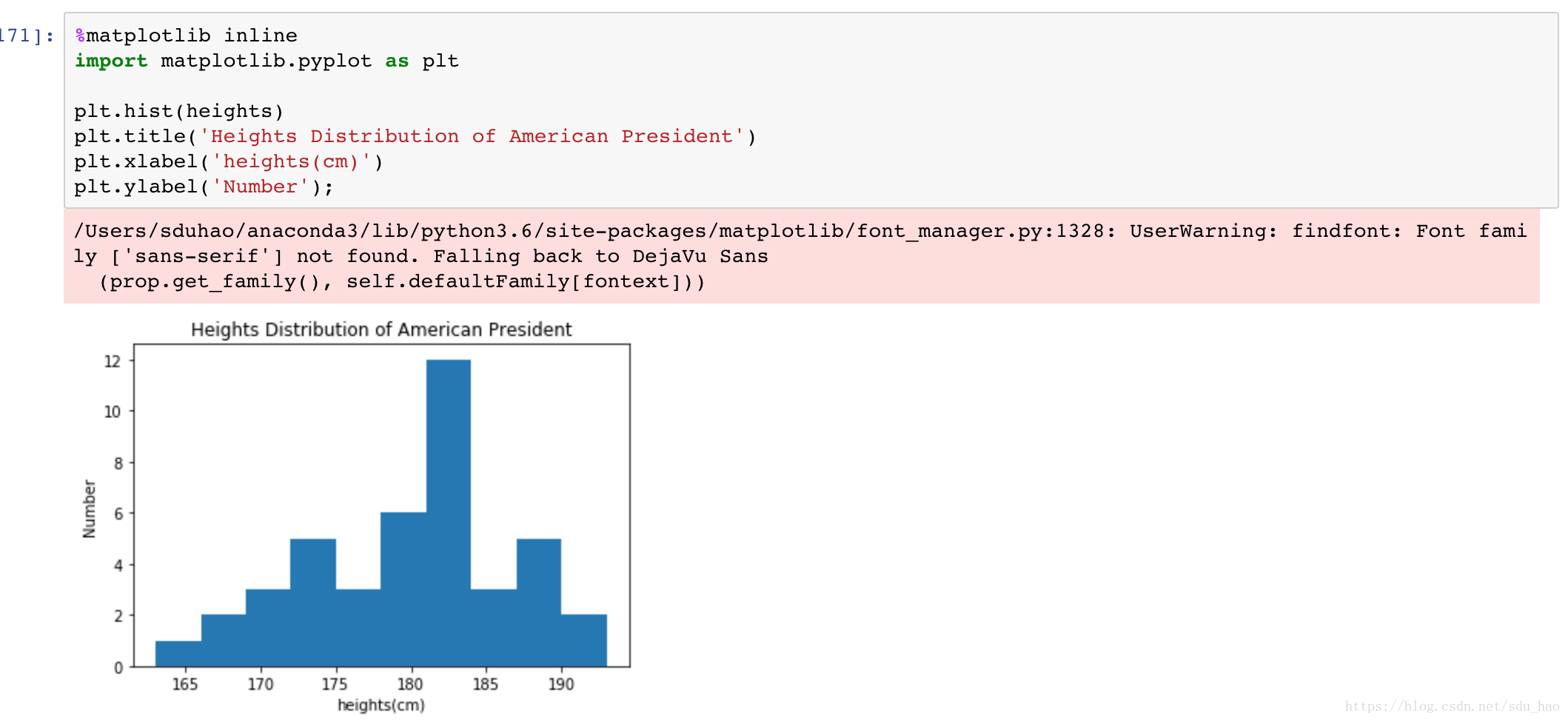
注意绘图时,坐标轴和标题的名称最好用英文,否则会出现乱码。如果想用中文,需要一些配置详情请看我的另一篇博客:Matplotlib绘图时的中文乱码问题。
六、数组的计算:广播
广播可以允许两个不同维度的数组进行运算。
1.广播的介绍
同样大小的数组运算,对应元素进行运算:

数组和标量运算:

可以理解为将数值5扩充为数组[5,5,5],再执行加法:

一维数组和二维数组运算:

可以看成一维数组先扩展成同维度的二维数组再运算:

两个不同维度的数组,也可以同时广播:
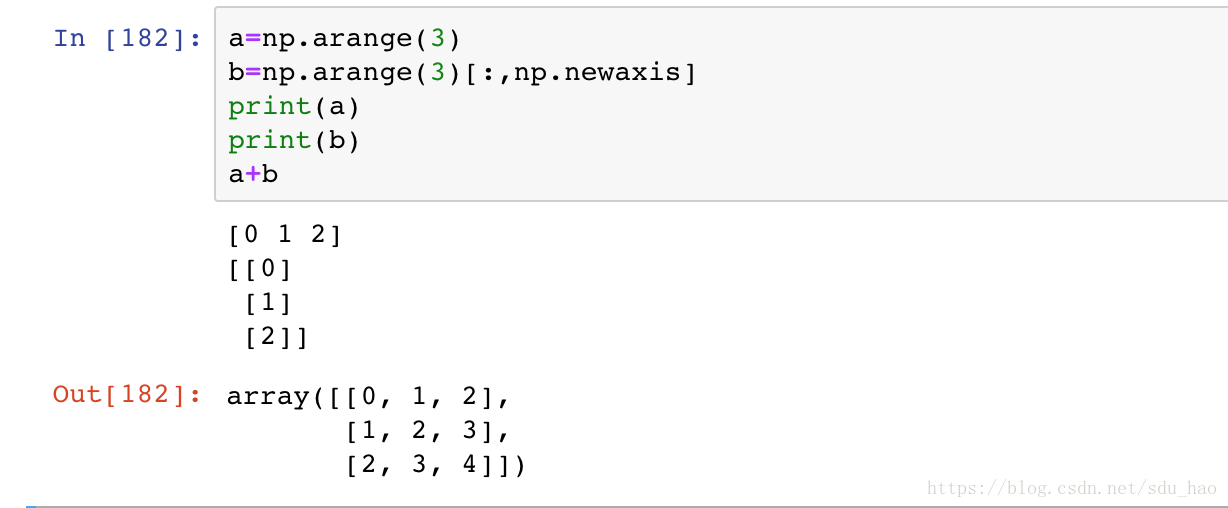
可以看成数组a,b都扩展成一个公共的形状,再进行运算:

2.广播的规则
规则1:如果两个数组的 维度数不同,那么小维度数组的形状会在最左边补1。
规则2:如果两个数组的形状在任何一个维度上都不匹配,那么数组形状会沿着维度为1的维度扩展以匹配另一个数组的形状。
规则3:如果两个数组的形状在任何一个维度上都不匹配并且没有任何一个维度等于1,异常。
- 示例1:

根据规则1,a的维度更小,所以在其形状的左边补1:

根据规则2,第一个维度不匹配,扩展这个维度以匹配:

两个维度现在都匹配了,最终的形状都是(2,3):

- 示例2
两个数组都需要广播:

先用规则1将b补全:

利用规则2,两个数组互相匹配:

最后得到形状为3*3:

- 示例3
看一个不相容的例子。

根据规则1,将a数组的形状补全:

根据规则2,a数组第一个维度匹配M:

根据规则3,最终形状不匹配:
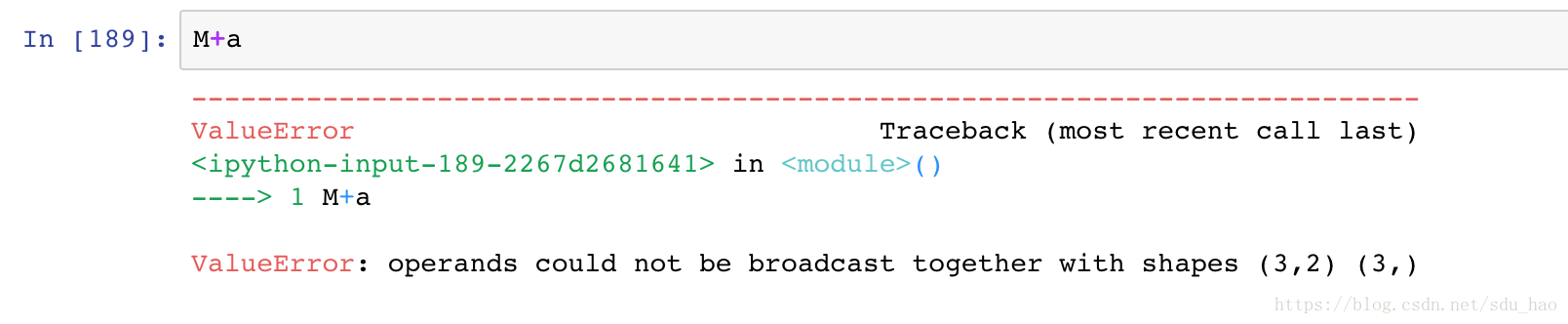
你可能想在a数组的右边补1,不是在左边补1,从而让M,a兼容,但这不是广播的规则。如果希望实现右边补全,可以用变型数组来实现:

另外注意这里仅用到了+运算符,广播对于任意通用函数都是适用的,比如:

3.广播的实际应用
- 数组的归一化

- 画一个二维函数
广播可以基于二维函数显示图像。我们定义一个函数z=f(x,y),可以用广播沿着数值区间计算该函数。

七、比较、掩码和布尔逻辑
1.示例:统计下雨天数
西雅图2014年降水量数据集 下载密码: z2yh

直方图:
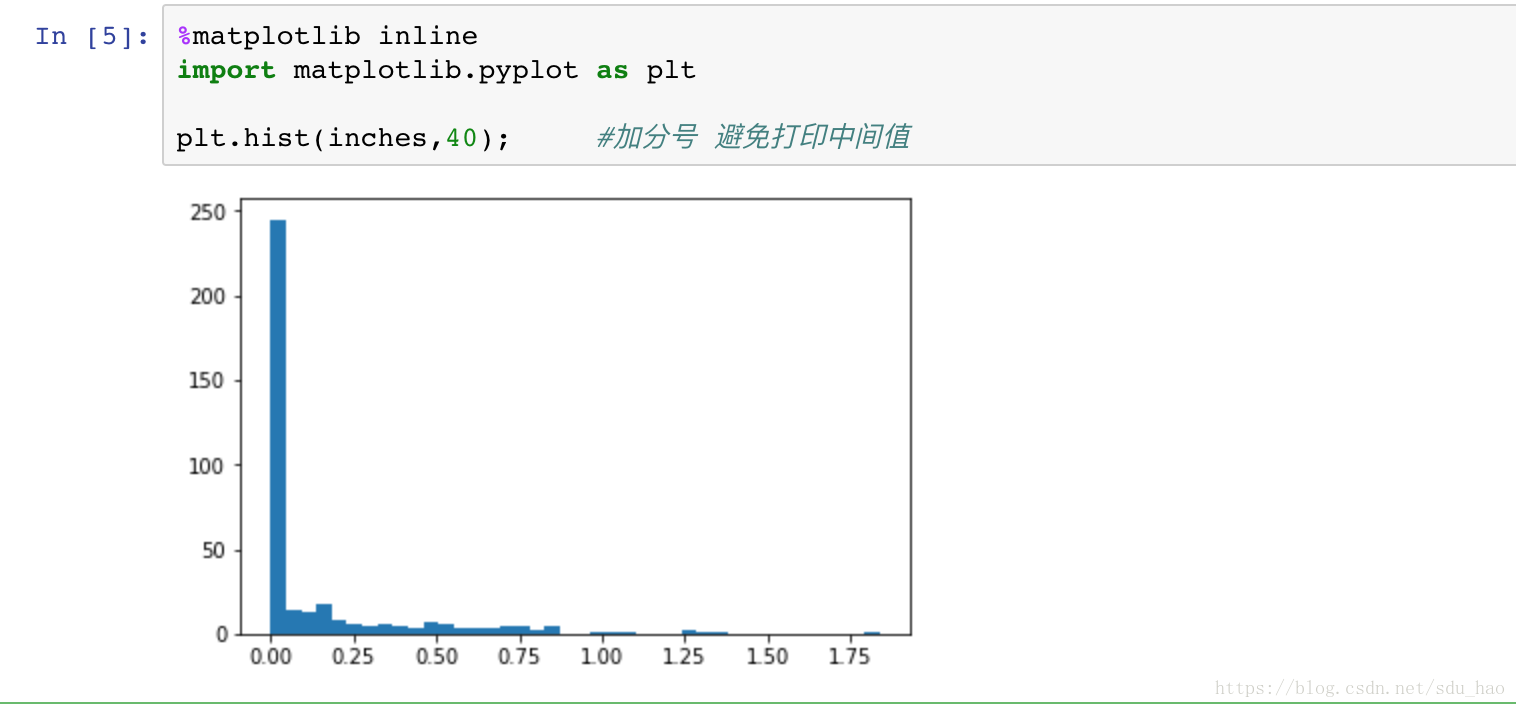
可以看到,2014年西雅图大多数时间的降水量都接近于0.我们还想了解一下其他的信息,比如一年中有多少天在下雨,这雨天的平均降水量是多少,有多少天的降水量超过了半英寸?
传统统计方法是对所有数据进行循环,非常低效。NumPy的通用函数可以用来替代循环,快速实现数组逐元素运算。
2.和通用函数类似的比较操作
之前介绍的通用函数主要是算术运算符对数组逐元素的操作,此外,NumPy还实现了如小于、大于的逐元素比较通用函数。运算结果为布尔类型的数组。有六种标准的比较操作:

利用复合表达式实现两个数组逐元素比较也是可行的:

和算术运算符一样,比较操作在NumPy中是用通用函数实现的。写x<3,NumPy内部会使用np.less(x,3),其他比较运算符对照表如下:

比较运算通用函数也可以用于任意形状、大小的数组:

3.操作布尔数组
- 统计记录的个数

np.sum()好处是,和其他NumPy聚合函数一样,可以沿行或列进行:

快速检查任意或者所有这些值是否为True:

np.any(),np.all()也可以沿特定坐标轴:

注意,区别np.all()和Python中内置的all(),二者是不同的,建议使用np.all().
- 布尔运算符

注意:括号非常重要,注意优先级

布尔运算符和对应的通用函数:

结合掩码和聚合实现相关统计:

4.将布尔数组作为掩码
之前介绍了如何对布尔数组进行聚合运算。更强大的模式是使用布尔数组作为掩码,选择数据的子数据集:

现在对西雅图的降水数据进行一些相关统计:

关键字and or 和逻辑运算符& | 的区别:
(1)and和or判断整个对象是真或假,而&和|是指每个对象中的比特位
(2)使用and或or时,等于让Python将这个对象当作整个布尔实体。python中非0整数都是True
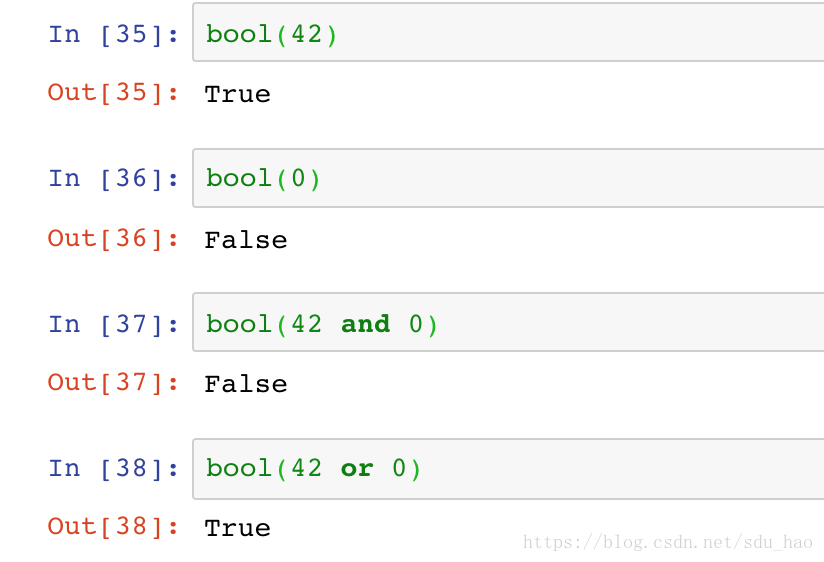
(3)当你对整数使用&和|时,表达式操作的是元素比特位,将and或or应用于组成该数字的每个比特:

(4)&和|运算时,对应的二进制比特位进行比较以得到最终的结果
(5)NumPy中有一个布尔数组时,数组被当作是由比特字符组成,1=True,0=False。数组可以使用& | 操作:

用or会计算整个数组对象的真假,报错:

(6)给定数组进行逻辑运算用|&,不是or and

计算整个数组的真假会报错:

总结:
and和or是对整个对象执行单个布尔运算,而&和|是对一个对象的内容(单个比特或字节)执行多个布尔运算。对于NumPy布尔数组,后者常用。
八、花哨的索引
之前介绍过几种索引方式,如简单索引值(arr[0]),切片(arr[:5])和布尔掩码(arr[arr>0]).
花哨的索引传递的是索引数组而不是单个标量。
1.探索花哨的索引
传递一个索引数组,一次性获取多个数组元素:

结果的形状与索引数组一致:

索引数组对多维数组也适用,第一个索引数组指行,第二个指列:

索引值的配对遵循广播规则。因此我们将一个列向量和一个行向量组合在一个索引中,会得到一个2维的结果:

2.组合索引
花哨的索引和简单索引组合使用:

花哨的索引和切片组合使用:

花哨的索引和掩码组合使用:

3.示例:选择随机点
花哨的索引可以用来从一个矩阵中选择行的子集。以下是一个二维正态分布的点组成的数组:

将这100个散点可视化:

利用花哨的索引随机选20个点:

这种方法常用于快速分割数据,即需要分割训练/测试集验证统计模型,以及在解答统计问题时的抽样方法中使用。
4.用花哨的索引修改值

注意操作重复的索引会导致一些出乎意料的结果:


如果希望发生累加,可以使用at():

5.示例:数据区间划分
利用这些方法可以有效的对数据区间进行划分并创建直方图。假如有100个值,快速统计分布在每个区间中的数据频次:

上述是手动计算直方图的方法,效率很低。matplotlib中提供了hist(),一行代码即可实现上述功能:

计算每个区间的数据量,NumPy提供了np.histogram(),我们可以比较一下二者的速度,数据量比较少时,我们用的方法更快;数据量比较大时,NumPy内置的方法更快:


九、数组的排序
1.NumPy中的快速排序:np.sort和np.argsort
Python中有内置的sort()和sorted()方法可以对列表进行排序,这里不再介绍,因为NumPy的np.sort()效率更高。默认情况下是快速排序,当然也可以选择归并排序和堆排序。
不修改原数组情况下排序,可以用np.sort():

修改原数组的情况下,可以用数组的sort():

np.argsort(),返回原始数组排好序的索引值:

对多维数组,可以按行/列排序:

2.部分排序
找到数组中前K小的值。

注意,结果中前三个值是原数组中前三小的值,余下的是原数组剩余的值。两部分的元素是任意排列的。
与排序一样,多维数组可以沿任意的轴进行分隔:

3.示例:K个近邻
利用argsort函数沿多个轴快速找到集合中每个点的最近邻。
首先,在2维平面上创建一个有10个随机点的集合,放在一个10*2的数组中:

可视化:

计算这些数据点,两两之间的平方距离,利用广播和聚合,计算矩阵的平方距离:

上述这行代码有很多部分组成,可以把它分解来看:

所得矩阵对角线元素为每个点到自身的距离,应该为0:

矩阵的每一行都是某个点到其他各个点的平方距离,可以使用np.argsort函数沿每行进行排序,最左边列给出的索引就是最近邻:

第一列按0-9排列,因为每个点的最近邻是自身。
如果我们只关心每个点的K个近邻,可以对平方距离矩阵的每一行进行分隔,最小的K+1个平方距离就排在前面。使用np.argpartition().

尽管广播和按行排序以及聚合不如循环直观,但更高效。建议使用这样的向量化编程,更高效简洁。
十、结构化数据:NumPy的结构化数组
NumPy的结构化数组和记录数组为复合的,异构的数据提供了非常有效的存储。
1.简介
假设现在有一些人的数据(姓名,年龄,体重),可以把他们分别存储在单独的数组或列表中:

这种方法有点笨,没有体现出数据之间的关联。可以用结构化数组来统一存储这些数据:

U10长度不超过10的Unicode字符串,i4表示4字节整型,f8表示8字节浮点型。
将列表数据放入数组中:

结构化数组可以通过索引和名称查看相应的值:

利用布尔掩码,可以做一些更复杂的操作

2.生成结构化数组
可以采用字典来制定结构化数组的数据类型:

数据类型可以用python类型或NumPy的dtype类型指定:

复合类型可以是元组列表:

如果类型名称不重要,可只用一个字符串来指定它,字符串中数据类型用,分隔:

NumPy数据类型:

3.更高级的复合类型
例如你可以创建一种类型,其中每个元素都包含一个数组或矩阵。我们会创建一个数据类型,该数据类型用mat组件包含一个3*3的浮点矩阵:

X数组的每个元素都包含一个id和一个3*3的矩阵。
4.记录数组:结构化数组的扭转
使用记录数组,域可以像属性一样获取,而不用像字典那样通过键来获取数据,按键更少:

记录数组缺点;即使使用同样的语法,获取域时也需要额外的开销:

使用更简单的标记还是更少的花销,取决于实际应用。