版权声明:本文为博主原创文章,未经允许,不得转载,如需转载请注明出处 https://blog.csdn.net/ssjdoudou/article/details/83240486
写在最前面:
当数据的特征大于样本点,线性回归就不能用了,因为在计算[(X^T)*X]的逆时候,n>m,n是特征,m是样本点,此时的输入矩阵不是满秩矩阵,行列式为0。
此时,我们可以使用岭回归(ridge regression)
阅读本文前,需要各位简单回忆一下线性代数知识,关于矩阵的秩
简单来说,岭回归就是在矩阵(X^T)*X的基础上加上λI,这样使得矩阵非奇异,从而能对(XTX)-1+λI整体求逆(矩阵X的转置乘矩阵X再求逆矩阵,实在是不会打数学公式,相信大家都能看的懂哈),其中,I是一个m✖️m的单位矩阵,这样我们的回归系数变成了
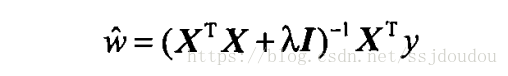
下面上代码
。
。
。
截图
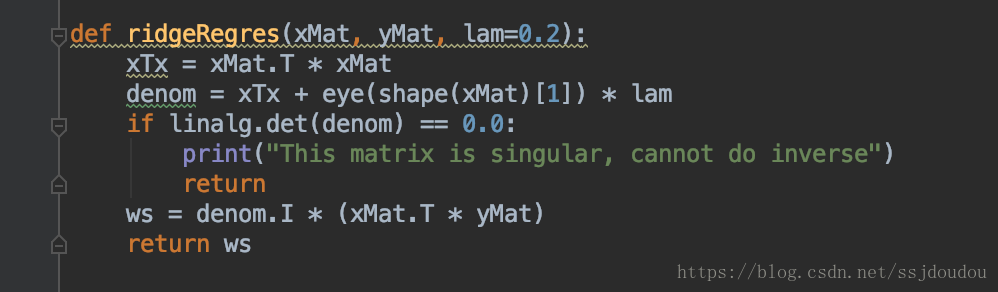
这个函数首先构建矩阵X^T ✖️ X,然后用lam乘以单位矩阵,默认lam为0.2,此时不排除lam为0的情况,所以还是需要对行列式进行一下非0判断。
上面是数据标准化
具体做法是所有特征减去各自的均值并除以方差
也可以计算标准差,std函数,标准差是方差开根号

加载数据

这样就得到了30个不同lambda对应的回归系数
简单介绍几个numpy常用的函数
mat:创建矩阵
mean:求均值
var:求方差
exp:指数
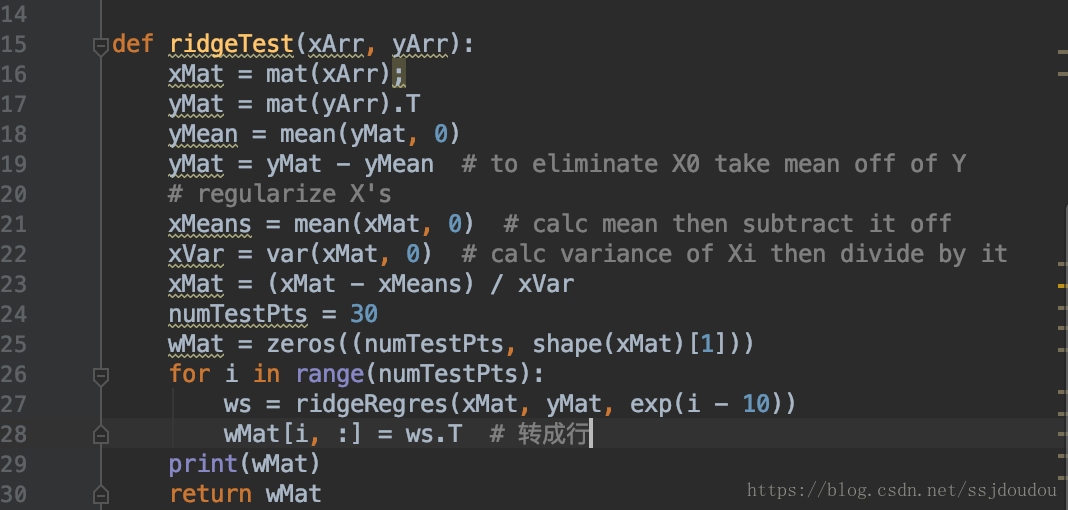
这里的lambda采用指数级变化,可以较快、和更明显的看出lambda在取值很小和很大的情况下,对结果造成的影响,将所有回归系数输出到一个矩阵并返回:
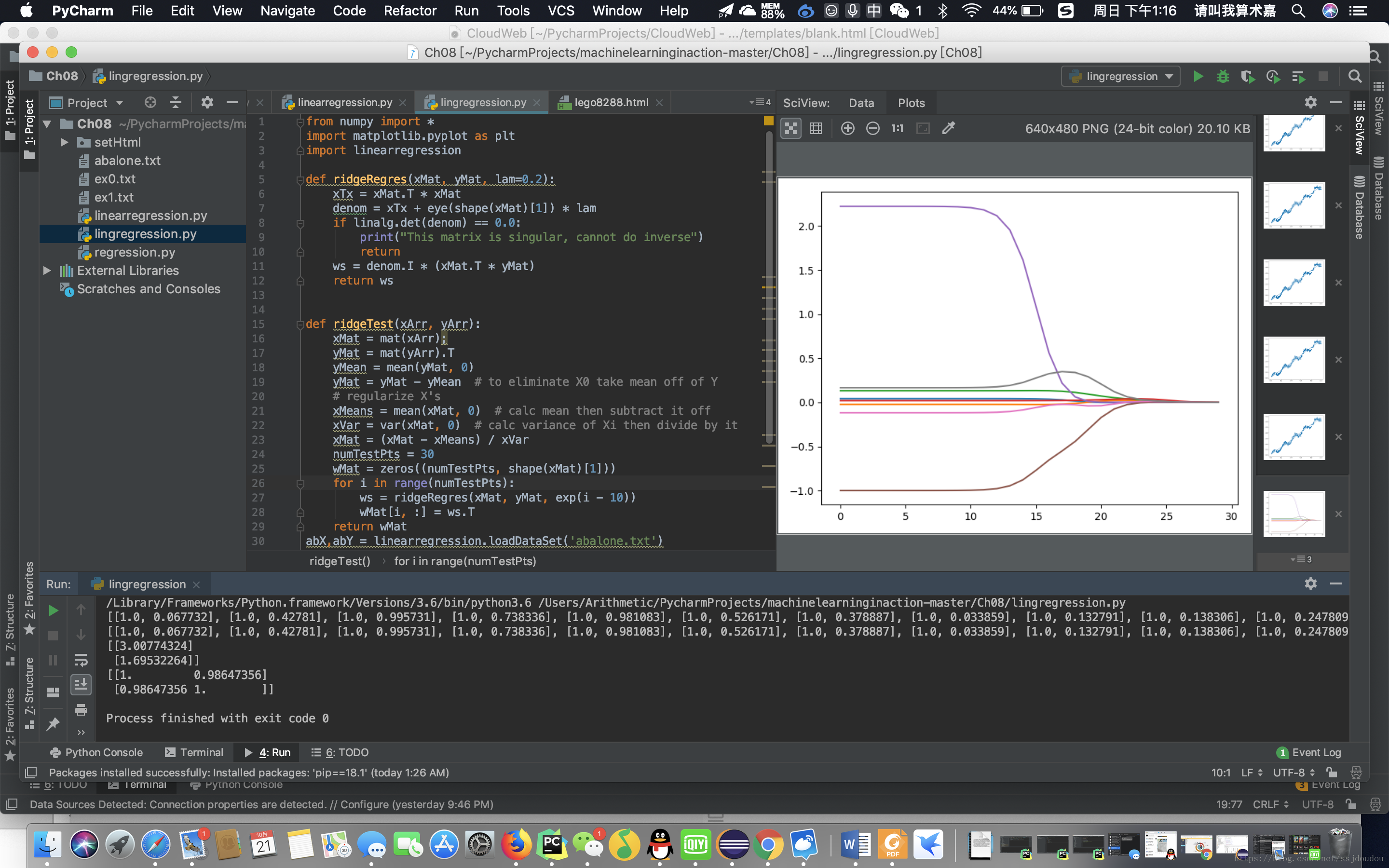
横坐标为log(λ),纵坐标为回归系数
当λ无限趋于0时,此时就是线性回归
当λ变大时,回归系数为0,此时也没有任何意义
在中间部分的某值可以取到比较好的预测效果
今天就到这里,好困啊,大家有啥想看的可以私我微信:18351922995