版权声明:欢迎转载,若有不当之处请在评论中指出,共同交流。 https://blog.csdn.net/qq_33290787/article/details/51956532
我们在设计数据库的过程中,往往要用到范式或反范式的设计模式。熟悉地掌握范式与反范式的要领,学会在实际开发中恰当地混合使用范式与反范式,才能设计出结构合理,执行高效的数据库。
下面就以一个经典的例子进行讲述范式与反范式:
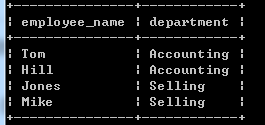
职工-部门表:
部门-部门领导表:
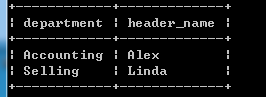
结合这两张表,我们知道,职工Tom与Hill都在部门Accounting工作,他们的领导是Alex。这种设计模式,称为范式。范式要求数据表中不存在任何的传递函数依赖。我们都知道职工,部门,领导之间有传递函数的依赖关系:职工–>部门–>领导。但是范式的设计模式将这种关系分开,使这种传递的关系在数据表中不再存在。
下面来看看反范式的设计模式:
反范式允许表中存在传递函数依赖。
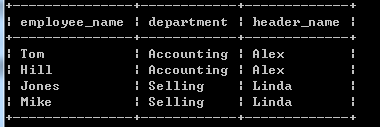
在这一张表中,我们直接看到职工Tom工作的部门为Accounting,这个部门的领导是Alex。表中就有职工–>部门–>领导的传递函数依赖关系。
范式与反范式的比较:
- 查询记录时,范式模式往往要进行多表连接,而反范式只需在同一张表中查询,当数据量很大的时候,显然反范式的效率会更好。
- 反范式有很多重复的数据,会占用更多的内存,查询时可能会较多地使用DROUP BY或DISTINCT等耗时耗性能的关键字。
- 当要修改更新数据时(例如修改Accounting部门的领导为Russell),范式更灵活,而反范式要修改全部的数据,且易出错。
…
总结:关于范式与反范式的比较还有很多很多,二者各有各的好处,在实际开发中应该根据需要合理地混用不同的模式,最大程度地结合发挥各自的优点。