最近涉及到设计和建立数仓表,数据总体划分为ods/fact/aggr/dws/rpt/dim层,具体结构如下图所示:
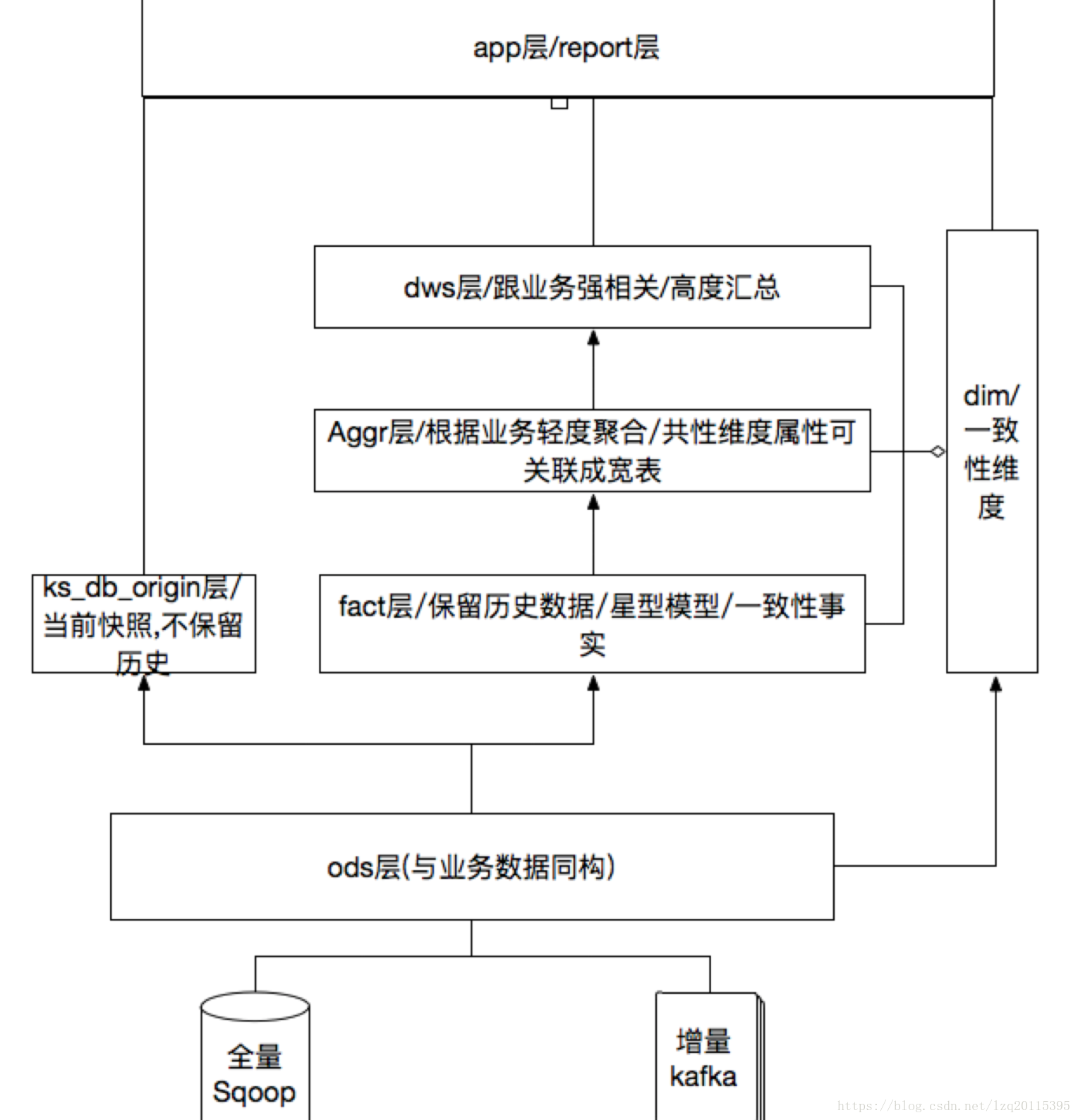
遵从设计规则:以星型模型为设计模式, 维度采用反范式化, 且维度数据要整个仓库可共用, 数据准确性要保证, 事实表允许冗余部分维度数据。针对其中几个地方,解释并mark一下。
设计模式
多维数据模型是最流行的数据仓库的数据模型,多维数据模型最典型的数据模式包括星型模式、雪花模式和事实星座模式。
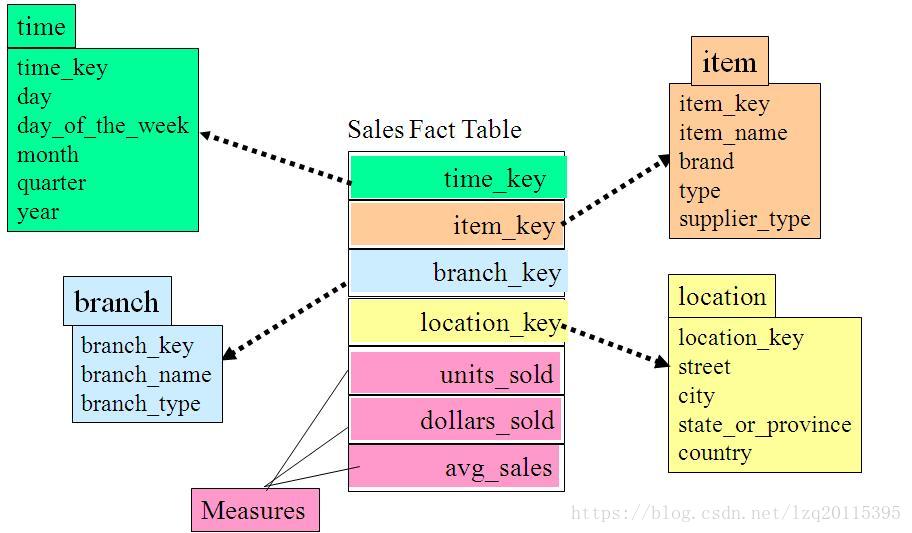
星型模型
星型模式的核心是一个大的中心表(事实表),一组小的附属表(维表)。星型模式示例如下所示:
雪花模型
雪花模式是星型模式的扩展,其中某些维表被规范化,进一步分解到附加表(维表)中。
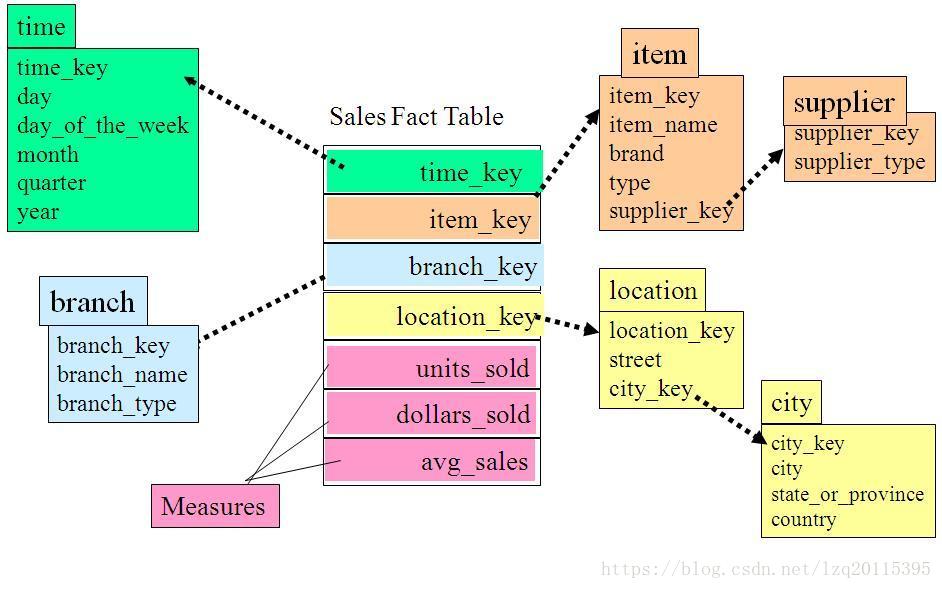
从图中我们可以看到地址表被进一步细分出了城市(city)维。supplier_type表被进一步细分出来supplier维。
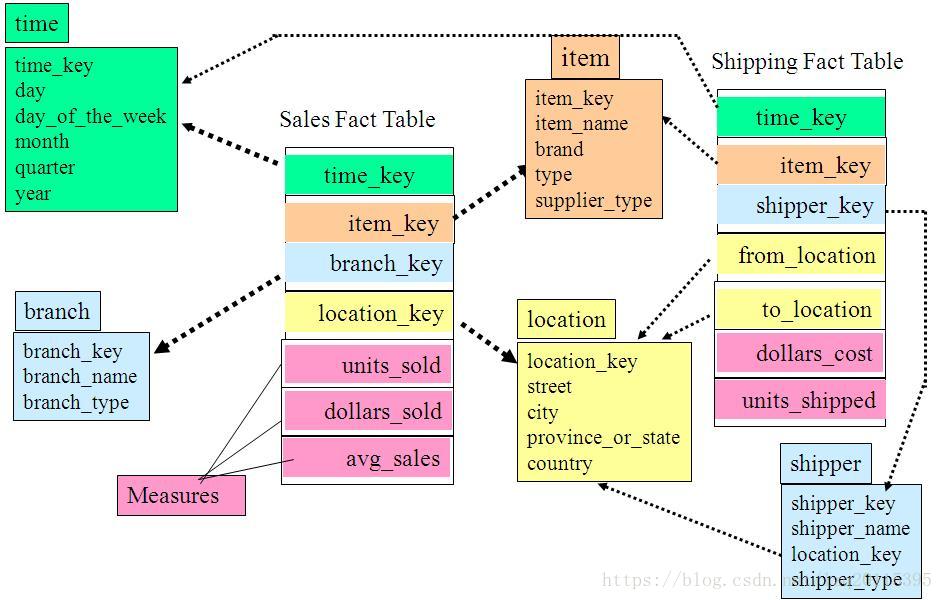
星座模式
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
范式与反范式
范式化
- 第一范式:每一列都是不可再分的最小数据单元,确保每一列的原子性。
- 第二范式:如果一个关系满足1NF,并且除了主键以外的其它列,都依赖与该主键;即非键字段必须依赖于键字段
- 第三范式:在1NF基础上,除了主键以外的其它列都不传递依赖于主键列,或者说: 任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
反范式化
不满足范式的模型,就是反范式模型,反范式跟范式所要求的正好相反,在反范式的设计模式,并不是完全不遵守范式模型,而是允许适当的数据的冗余,用这个冗余去取操作数据时间的缩短。本质上就是用空间来换取时间,把数据冗余在多个表中,当查询时可以减少或者是避免表之间的关联
两者对比
- 范式数据没有冗余,更新容易,但是查询时需要join很多表,导致效率较低;反范式数据存在冗余,更新时需要进行更多的操作,但是因为很多数据沉淀在同一表,查询效率较高
- 传统数据表,更新频繁,不适合反范式设计;而在hive这种存储系统中,数据不允许更新,且查询需求更为频繁,因此天然适合反范式模型设计。
实际应用中,一般对需要综合使用范式和反范式,保证空间和时间的平衡,但是随着磁盘空间的越来越廉价,反范式应用越来越普遍