Lucene简介:
Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
这是Lucene的官方介绍,来自http://lucene.apache.org/core/index.html,简单来说即:Lucene是Apache下高性能,功能齐全的开源全文检索引擎工具包。
结识Lucene:
作为一名后台开发人员,必定会涉及到搜索这一领域。最开始接触搜索是在一年前的数据库学习中,当时知道通过 LIKE ‘%待搜索字符串a%’这样的SQL语句可以查找到记录中包含字符串a的数据。例如在数据库中存在一条商品记录为‘SAMSUNG白色三星A7手机’。当用户输入‘三星A7’时,使用数据库中的LIKE %%匹配这种方式确实能返回该数据,但是当用户输入‘三星手机’,或是‘白色A7’时,就无法匹配并返回数据,那应该怎么实现这种查找呢?直到一年后的java开发课中,在老师展示一个J2ee的作品时,就在一瞬间我发现了老师的作品中有一个很棒的搜索机制,老师在搜索输入框中输入了一小段文字,回车后出现的搜索结果中字符的匹配非常到位,就好比你百度或是google一个问题,出现的结果是根据你的问题进行字符或词汇的拆分与匹配查找,最后呈现结果并高亮显示查询的关键字。好比这样:
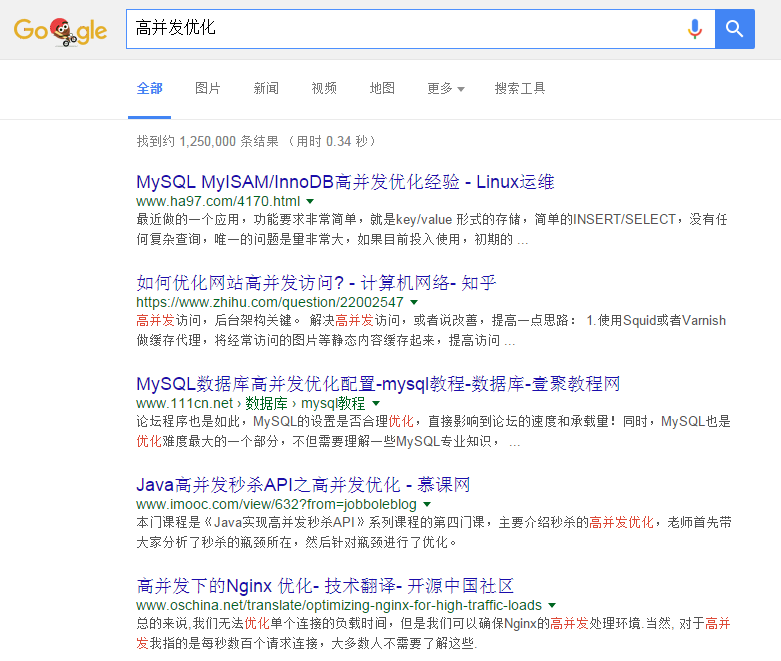
显然这样的效果无法在数据库中使用LIKE匹配来实现,老师说这基于开源的搜索API Lucene。通过学习,总结了一些,也实现了Lucene的检索,下面就开始讲Lucene的原理与给出代码实现。
Lucene原理:
Lucene索引结构:
Lucene是一种全文检索的工具包,但不是字符串全篇匹配,那样当文章很长很长的时候,全篇匹配字符串的效率低地无法估计。Lucene采用倒排索引的策略:
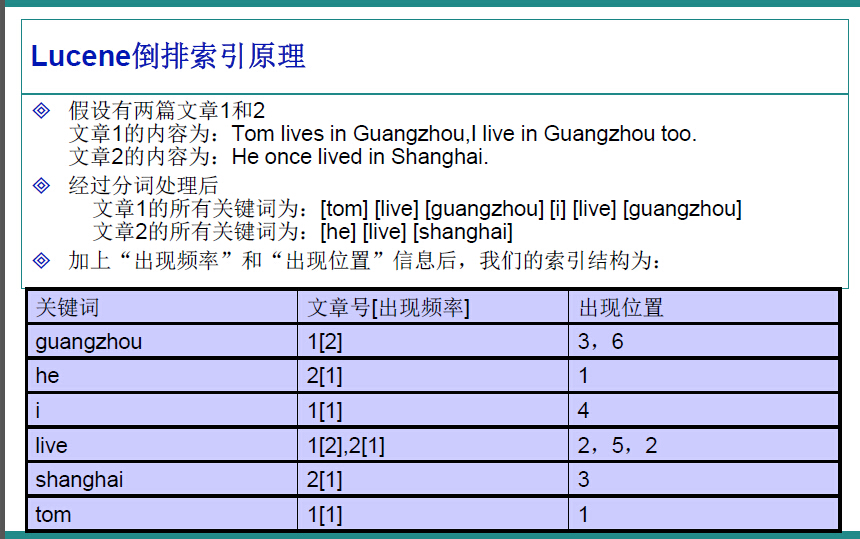
- 现在在硬盘中有两篇文档,分别为文章1与文章2,内容如图所示。那么Lucene先会对文章进行分词处理,得到可能会以关键字被搜索的重点词。因此在这个操作后,就会得到一种类似于关联的关系,即某文章关键词:词1,词2,词3 ….
- 但是Lucene的索引结构却是关键词:某文章,因此叫做倒排索引结构。确实,搜索的时候的确是要根据用户的输入关键字查找文章,而不是用户输入文章号或文章名进行查找。
- 值得一提的是索引结构中还记录了关键字出现的位置与出现频率,这方便于结果呈现时的关键词高亮。
Lucene搜索过程:
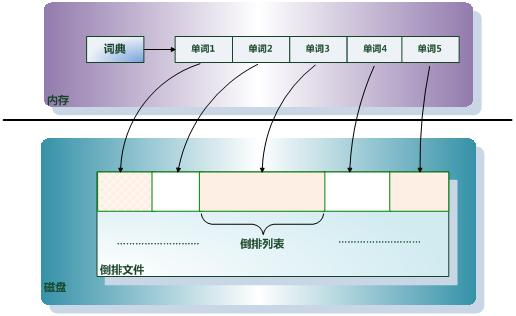
- 在对文章进行分词处理后,建立了一个单词词典文件:单词词典文件内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。之后还会生成其他文件,例如频率文件等,这些文件统统被写入Lucene的索引文件中。
- 用户输入关键字后,Lucene先在索引文件中的词典快速定位找到匹配的单词,再根据匹配得到的单词指针指向相应的倒排文件得到搜索结果。因此,快速定位词典是整个搜索的关键,直接决定搜索的相应速度。
一幅图概括Lucene:

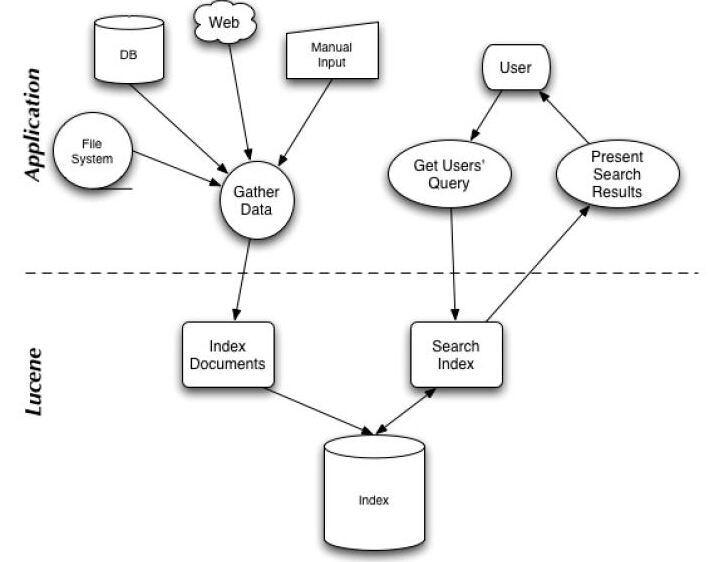
总结:从这幅图可以看出,Lucene的核心,就是索引文件。
Lucene代码实现与讲解:初始Lucene(下)