初识 Lucene
什么是全文检索?
我们实际中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据,Excle,cvs等。
- 非结构化数据:指不定长或无固定格式的数据,如文章,word文档等。
非结构化数据又叫做全文数据,我更倾向于全文数据,全文数据更加明显的说明了非结构化数据的特征。
同理:
按照数据的划分,数据的检索也分为两种:
- 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量非结构化内容数据。
非结构化数据搜索方法
- 顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
例如Linux下的grep命令是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢. - 全文检索(Full-text Search)
全文检索的基本思路:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
Lucene 简介
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。
目前已经有很多应用程序的搜索功能是基于 Lucene 的,比如 Eclipse 的帮助系统的搜索功能。Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。不指定要索引的文档的格式也使 Lucene 能够几乎适用于所有的搜索应用程序。
如下图 表示了搜索应用程序和 Lucene 之间的关系,也反映了利用 Lucene 构建搜索应用程序的流程:
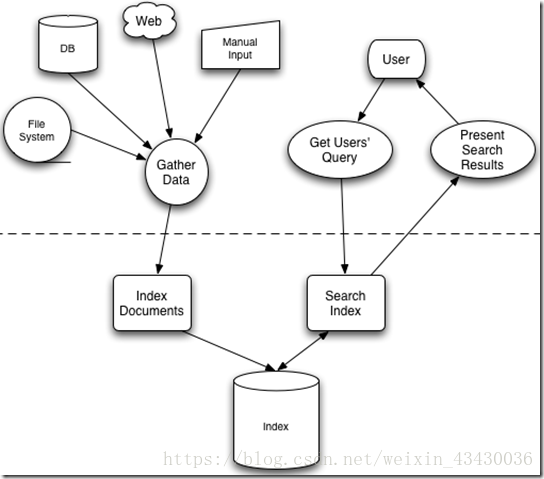
索引和搜索
索引是现代搜索引擎的核心,建立索引的过程就是把源数据处理成非常方便查询的索引文件的过程。为什么索引这么重要呢,试想你现在要在大量的文档中搜索含有某个关键词的文档,那么如果不建立索引的话你就需要把这些文档顺序的读入内存,然后检查这个文章中是不是含有要查找的关键词,这样的话就会耗费非常多的时间,想想搜索引擎可是在毫秒级的时间内查找出要搜索的结果的。这就是由于建立了索引的原因,你可以把索引想象成这样一种数据结构,他能够使你快速的随机访问存储在索引中的关键词,进而找到该关键词所关联的文档。Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词 / 短语表,对于这个表中的每个词 / 短语,都有一个链表描述了有哪些文档包含了这个词 / 短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。
对文档建立好索引后,就可以在这些索引上面进行搜索了。搜索引擎首先会对搜索的关键词进行解析,然后再在建立好的索引上面进行查找,最终返回和用户输入的关键词相关联的文档。
Lucene倒排索引
前面我们说到了索引其实是一种数据结构(Mysql的索引其实也是B+树数据结构),实际使用过程中,我们全文检索文档都是通过检索我们关心的词/短语来确定哪些文档是我们所需要的,Lucene倒排索引可以理解为我们维护了一个链表来描述我们需要检索的词/短语出现在哪些文档里面。
这种索引表中的每一项都包括一个词/短语和具有该词/短语的各记录的地址。由于不是先定位文档再具体确定我们关心的词/短语,而是先检索我们关心的词/短语来确定文档,因而称为倒排索引(inverted index)。 带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排文件(倒排索引),索引对象是文档或者文档集合中的单词等,用来存储这些单词在一个文档或者一组文档中的存储位置,是对文档或者文档集合的一种最常用的索引机制。
搜索引擎的关键步骤就是建立倒排索引,倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签一般。读者想看哪一个主题相关(关键词相关)的章节,直接根据目录(相当于索引)即可定位相关的页面。不必再从书的第一页到最后一页,一页一页的查找。
Lucene倒排索引的实现
Lucerne使用的是倒排文件索引结构。该结构及相应的生成算法如下:
设有两篇文章1和文章2:
- 文章1的内容为:Tom lives in Guangzhou,I live in Guangzhou too.
- 文章2的内容为:He once lived in Shanghai.
分析提取关键词
- 我们现在有的是文章内容,即一个字符串,我们先要找出字符串中的所有单词,即分词。英文单词由于用空格分隔,比较好处理。中文单词间是连在一起的需要特殊的分词处理。
- 文章中的”in”, “once” “too”等词没有什么实际意义,中文中的“的”“是”等字通常也无具体含义,这些 不代表概念 的词可以过滤掉。
- 用户通常希望查“He”时能把含“he”,“HE”的文章也找出来,所以所有单词需要统一大小写 。
- 用户通常希望查“live”时能把含“lives”,“lived”的文章也找出来,所以需要把“lives”,“lived”还原成“live” 。
- 文章中的标点符号通常不表示某种概念,也可以过滤掉 。
在lucene中以上措施由Analyzer类完成。 经过上面处理后:
- 文章1的所有关键词为:[tom] [live] [guangzhou] [i] [live] [guangzhou]
- 文章2的所有关键词为:[he] [live] [shanghai]
建立倒排索引
有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章1,2经过倒排后变成 :
| 关键词 | 文章号 |
|---|---|
| guangzhou | 1 |
| he | 2 |
| i | 1 |
| live | 1,2 |
| shanghai | 2 |
| tom | 1 |
通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置 ,通常有两种位置:
- 字符位置 ,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
- 关键词位置 ,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
| 关键词 | 文章号\出现频率 | 出现位置 |
|---|---|---|
| guangzhou | 1\2 | 3,6 |
| he | 2\1 | 1 |
| i | 1\1 | 4 |
| live | 1\2 ; 2\1 | 2,5 ; 2 |
| shanghai | 2\1 | 3 |
| tom | 1\1 | 1 |
以live 这行为例我们说明一下该结构:live在文章1中出现了2次,文章2中出现了一次,它的出现位置为“2,5,2”这表示什么呢?我们需要结合文章号和出现频率来分析,文章1中出现了2次,那么“2,5”就表示live在文章1中出现的两个位置,文章2中出现了一次,剩下的“2”就表示live是文章2中第 2个关键字。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列 的(lucene没有使用B树结构),因此lucene可以用二元搜索算法快速定位关键词 。
具体实现
实现时,lucene将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
Lucene中使用了field的概念,用于表达信息所在位置(如标题中,文章中,url中),在建索引中,该field信息也记录在词典文件中,每个关键词都有一个field信息(因为每个关键字一定属于一个或多个field)。
压缩算法
为了减小索引文件的大小,Lucene对索引还使用了压缩技术。
首先,对词典文件中的关键词进行了压缩,关键词压缩为<前缀长度,后缀>,例如:当前词为“阿拉伯语”,上一个词为“阿拉伯”,那么“阿拉伯语”压缩为<3,语>。
其次大量用到的是对数字的压缩,数字只保存与上一个值的差值(这样可以减小数字的长度,进而减少保存该数字需要的字节数)。例如当前文章号是16389(不压缩要用3个字节保存),上一文章号是16382,压缩后保存7(只用一个字节)。
应用原因
下面我们可以通过对该索引的查询来解释一下为什么要建立索引。
假设要查询单词 “live”,lucene先对词典二元查找、找到该词,通过指向频率文件的指针读出所有文章号,然后返回结果。词典通常非常小,因而,整个过程的时间是毫秒级的。
而用普通的顺序匹配算法,不建索引,而是对所有文章的内容进行字符串匹配,这个过程将会相当缓慢,当文章数目很大时,时间往往是无法忍受的。