一、自动编码器
目前为止,我们介绍了神经网络在有标签的训练样本的有监督学习中的应用.现在假设我们只有一个未标记的训练集{x(1),x(2),x(3),…},其中x是n维的.自动编码器神经网络是一种采用反向传播的无监督学习算法,让目标值和输入相等,即让y(i)=x(i).
这是一个自动编码器:

自动编码器试图学习函数hW,b(x)≈x.换句话说,它试图学习恒等函数的逼近,使得输出x^与x类似.这个将要学习的恒等函数看起来是个特别无关紧要的函数;但通过在网络中做些限制,例如限制隐藏单元的个数,我们可以发现数据中的有趣结构.具体地说,假设输入x是10*10图像的像素强度值,n=100,然后L2层有s2=50个隐藏单元.注意到y也是100维的.既然只有50个隐藏单元,网络不得不学习输入的一个“压缩”表示,即给定隐藏单元的激活值a(2)只有50维,它必须“重构”100个像素的输入.如果输入是完全随机的,即每个xi与其它特征值是高斯独立同分布的,那么这次压缩任务会非常困难.但是如果数据中包含结构,例如如果一些输入特征是相关的,那么这个算法可以发现这些相关性.事实上,这个简单的编码器经常用于学习低维度表示,很像PCA(主成份分析).
以上的论点是根据隐藏层单元小数目s2.不过即使当隐藏层单元数目大时(也许甚至比输入像素数目还大),通过对网络施加其它限制,我们依旧能发现有趣的结构.特别的,如果我们对隐藏层单元施加“稀疏”的限制,那么我们依旧在数据中能发现有趣的结构,即使隐藏层单元数目多.
非正式地说,我们会认为神经元是“激活的”(或者“点着了”),如果它的输出接近1;或者“未激活”如果它的输出接近0.我们希望限制神经元在大部分时间是未激活的状态.这个讨论假设用的是sigmoid激活函数.如果你使用tanh激活函数,我们会认为神经元是未激活的,如果它的输出接近-1.
回忆一下aj(2)表示自动编码器隐藏单元j的激活值.然而,这样的表示不能搞清楚引起激活值的输入x是什么.这样,我们会用aj(2)(x)表示当网络给定输入是x时该隐藏单元的激活值.
进一步,令
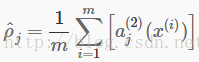
是隐藏单元j的平均激活值(在训练集上取平均).我们可以(近似)实施限制ρ^j=ρ,其中ρ是一个“稀疏参数”,典型值接近0的小值(例如ρ=0.05).换句话说,我们希望每个隐藏单元j的平均激活值接近0.05(假设).为了满足这个限制,隐藏单元的大多数激活值都必须接近0.
为了实现,我们往我们的优化目标添加一个额外的惩罚项,惩罚ρ^j对ρ的偏离程度.惩罚项的许多选择都能得到合理的结果.我们选择以下形式:
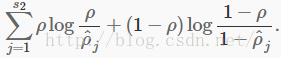
这里,s2是隐藏层的神经元数目,下标j对网络中的隐藏单元求和.如果你熟悉KL分解的概念,这个惩罚项就是基于此,也可以写为
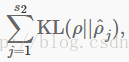
其中KL(ρ||ρ^j)=ρlogρ/ρ^j+(1−ρ)log1−ρ/1−ρ^j是伯努力随机变量——平均值ρ和ρ^j间的Kullback-Leibler(KL)分解。KL分解是衡量两个不同的分布有多不同。(如果你之前还没有见过KL分解,别担心;你需要了解的所有东西都在这节中。)
惩罚函数有这样的性质,如果ρ^j=ρ,则KL(ρ||ρ^j)=0,否则会随着ρ^j和ρ的偏离程度单调递增。例如,在下面的图中,我们令ρ=0.2,我们画出关于取一定范围ρ^j,KL(ρ||ρ^j)的值。
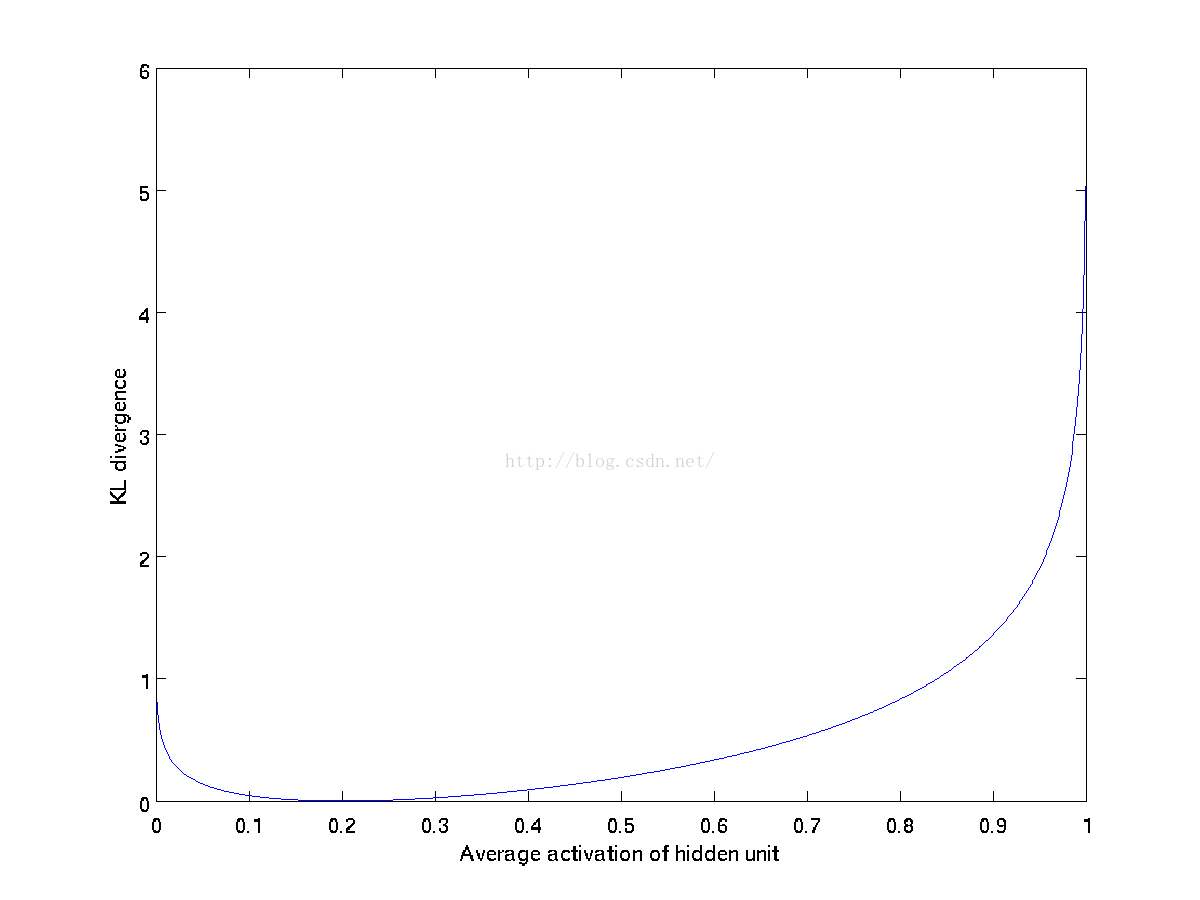
我们看到KL分解在ρ^j=ρ处取得最小值0.并随着ρ^j接近0或1而迅速增大(实际上趋于无穷大).因此,最小化这一惩罚项使得ρ^j接近ρ.
我们目前的全局代价函数是
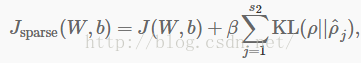
其中J(W,b)之前定义过了,β控制稀疏惩罚项的权重。ρ^j项也(隐性地)依赖W,b,因为它是隐藏单元j的平均激活值,而隐藏单元的激活值依赖参数W和b。
为了让KL分解项包含到你的导数计算中,有一种易于实现的技巧,只需要对你的代码做小的改变。具体而言,之前在第二层(l=2)中,在反向传播过程中你将会计算:
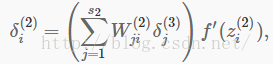
取而代之的是计算
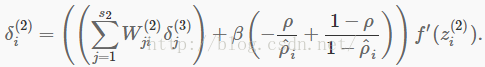
一个微妙的地方是你需要知道ρ^i来计算这项。那么,你就首先需要在所有训练样本计算前向传播,从而计算训练集上的平均激活值,然后再从任一样本中计算反向传播。如果你的训练集足够小,能够很好地满足计算机内存(这对编程任务而言也是一样的),你可以在所有样本上计算前向传播,并将激活值结果保存在内存中然后计算ρ^i。然后你可以用之前计算的激活值在所有样本上计算反向传播。如果你的数据太多内存装不下,你只能浏览所有的样本,在每个样本上计算前向传播然后将激活值累积(求和)然后计算ρ^i(一旦你用激活值ai(2)计算完ρ^i,便丢弃每次计算前向传播的结果)。然后计算完ρ^i后,你再对每个样本做一次前向传播计算以便你能够在那个样本上做反向传播。在后面这种情况,你会在训练集的每个样本计算两次前向传播结束,使得计算效率较差。
以上的算法得到梯度下降的完整推导已经超出了这节的篇幅。不过如果你使用修改后的反向传播实现自动编码器,你将在目标函数Jsparse(W,b)上计算梯度下降。使用导数检验的方法,你也可以自己验证。
二、可视化训练好的自动编码器
训练好(稀疏)自动编码器后,我们想要可视化这个算法学习的函数,并理解它学习了什么。考虑在10×10图像上训练的自动编码器,因此n=100。每个隐藏单元i计算输入的函数:
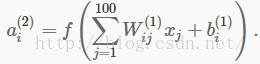
我们会使用2D图像将通过隐藏单元i计算的函数可视化——依赖参数Wij(1)(这里忽略偏置项)。特别地,我们认为ai(2)是输入x的一些非线性的特征。我们会问:是什么样的输入图像x能让ai(2)最大程度激活?(不是很正式地说,隐藏单元i在寻找什么样的特征?)为了得到这个不是无关紧要的问题的回答,我们需要在x上施加一些限制。如果我们假设输入被||x||2=∑xi2≤1标准化限制,那么我们可以看到(尝试自己完成)最大化地激活隐藏单元i的输入是由按如下方式设置像素xj给定的(对全部100像素而言,j为1到100):
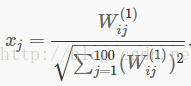
通过将由这些像素强度值填充的图像显示出来,我们可以开始理解隐藏单元i在寻找什么样的特征。
如果我们有一个包含100个(举例)隐藏单元的自动编码器,那么我们的可视化图像将得到100幅这样的图像——一个代表一个隐藏单元。通过检查这100幅图像,我们能尝试理解隐藏单元在学习一个什么集合。
当我们对一个稀疏自编码器这么做(用建立在10×10像素输入上的100个隐藏单元训练),我们会得到如下结果(每个图像10*10代表一个隐藏单元,共100个隐藏单元):

上图中的每个方块展示了(用标准化界定的)输入图像x,它最大化地激活了100个隐藏单元的其中一个。我们发现不同的隐藏单元在学习检测图像中不同位置和方向的边缘。
这些特征,不惊奇地,对于像目标识别和其它视觉任务等是非常有用的。当应用到其它输入领域(例如音频),这个算法同样学习对这些领域有用的表示/特征。
这些学习到的特征是通过训练“白化的”自然图像得到的。白化是去除输入冗余度的预处理步骤,使相邻的像素点变得更不相关。