本文主要参考于:Multilayer Perceptron
python源代码(github下载 CSDN免费下载)
本文主要介绍含有单隐层的MLP的建模及实现。建议在阅读本博文之前,先看一下LR的实现。因为LR是简化版的MLP。LR不含有单隐层,则其输入层直接连接到输出层。从何处可以看出LR是输入层直接连接输出层?借用上一博文的公式:
那么MLP的模型公式和LR又有什么不同呢?下面来看一下MLP的模型建立。
一、模型
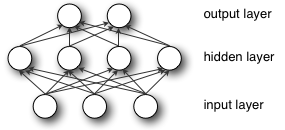
从MLP的结构图中可以看出输入层与隐藏层全连接,然后,隐藏层与输出层全连接。那么整体的函数映射就是
其中,
对于连接单隐层的的表达式
对于连接输出层的表达式
接下来就是训练模型获取最佳参数,我们这里仍然采用MSGD(批量随机梯度下降法)方法。这里我们需要学习的参数为
讲到这里小伙伴们或许有疑问了:没有代价函数怎么求梯度啊?也就是
二、MLP代码实现
我们主要关注实现含单隐层的MLP(只要单隐层的实现了,多隐层的就是多实例化几个隐层而已)。MLP的实现包括3部分:输入层、隐层、输出层。
第一层:输入层就是我们直接的输入数据
第二层:隐层的功能是用
第三层:输出层的功能是将第二层的输入数据经过
先提前讲一下隐层权值的初始化问题。在LR类中,权值矩阵初始化为0。然而在隐层中就不能再初始化为0了,而是依据激活函数从symmetric interval(对称间隔)中均匀采样。这样初始化是为了确保在训练早期,每一个神经元都可以向后传播(upward)激活信息,向前传播(backward )梯度数据。也就是说在这一层用到了梯度反向传播,那么权值矩阵就不能初始化为0,不知道解释的如何?原文:(This initialization ensures that, early in training, each neuron operates in a regime of its activation function where information can easily be propagated both upward (activations flowing from inputs to outputs) and backward (gradients flowing from outputs to inputs))。
那么具体的均匀采样范围是什么呢?
对于函数
对于函数
可以从文献Xavier10中获取以上范围的来因。是一个大牛写的论文,如果能看懂也很牛。
部分代码:
class HiddenLayer(object):
def __init__(self, rng, input, n_in, n_out, W=None, b=None, activation=T.tanh):
'''
初始化函数!HiddenLayer实例化时调用该函数。该层与输入层是全连接,激活函数为tanh。
参数介绍:
rng 类型为:numpy.random.RandomState。
rng 功能为:rng是用来产生随机数的实例化对象。本类中用于对W进行随机数初始化。而非0值初始化。
input 类型为:符号变量T.dmatrix
input 功能为:代表输入数据(在这里其实就是传入的图片数据x,其shape为[n_examples, n_in],n_examples是样本的数量)
n_in 类型为:int
n_in 功能为:每一个输入样本数据的长度。和LR中一样,比如一张图片是28*28=784,
那么这里n_in=784,意思就是把图片数据转化为1维。
n_out 类型为:int
n_out 功能为:隐层单元的个数(隐层单元的个数决定了最终结果向量的长度)
activation 类型为:theano.Op 或者 function
activation 功能为:隐层的非线性激活函数
'''
self.input = input
# 根据博文中的介绍,W应该按照均匀分布来随机初始化,其样本数据范围为:
# [sqrt(-6./(fin+fout)),sqrt(6./(fin+fout))]
# 根据博文中的说明,fin很显然就是n_in了,因为n_in就是样本数据的长度,即输入层的单元个数。
# 同样,fout就是n_out,因为n_out是隐层单元的个数。
# rng.uniform()的意思就是产生一个大小为size的矩阵,
# 矩阵的每个元素值最小是low,最大是high,且所有元素值是随机均匀采样。
if W is None:
W_values = numpy.asarray(
rng.uniform(
low=-numpy.sqrt(6. / (n_in + n_out)),
high=numpy.sqrt(6. / (n_in + n_out)),
size=(n_in, n_out)
),
dtype=theano.config.floatX
)
# 如果激活函数是sigmoid的话,每个元素的值是tanh的4倍。
if activation == theano.tensor.nnet.sigmoid:
W_values *= 4
W = theano.shared(value=W_values, name='W', borrow=True)
# 偏置b初始化为0,因为梯度反向传播对b无效
if b is None:
b_values = numpy.zeros((n_out,), dtype=theano.config.floatX)
b = theano.shared(value=b_values, name='b', borrow=True)
self.W = W
self.b = b
# 计算线性输出,即无激活函数的结果,就等于最基本的公式 f(x)=Wx+b
# 如果我们传入了自己的激活函数,那么就把该线性输出送入我们自己的激活函数,
# 此处激活函数为非线性函数tanh,因此产生的结果是非线性的。
lin_output = T.dot(input, self.W) + self.b
self.output = (
# 这个表达式其实很简单,就是其他高级语言里边的三目运算
# condition?"True":"false" 如果条件(activation is None)成立,
# 则self.output=lin_ouput
# 否则,self.output=activation(lin_output)
lin_output if activation is None
else activation(lin_output)
)
self.params = [self.W, self.b] 根据HiddenLayer类计算完结果后,我们相当于计算了公式
class MLP(object):
'''
多层感知机是一个前馈人工神经网络模型。它包含一个或多个隐层单元以及非线性激活函数。
中间层通常使用tanh或sigmoid作为激活函数,顶层(输出层)通常使用softmax作为分类器。
'''
def __init__(self, rng, input, n_in, n_hidden, n_out):
'''
rng, input在前边已经介绍过。
n_in : int类型,输入数据的数目,此处对应的是输入的样本数据。
n_hidden : int类型,隐层单元数目
n_out : int类型,输出层单元数目,此处对应的是输入样本的标签数据的数目。
'''
# 首先定义一个隐层,用来连接输入层和隐层。
self.hiddenLayer = HiddenLayer(
rng=rng,
input=input,
n_in=n_in,
n_out=n_hidden,
activation=T.tanh
)
# 然后定义一个LR层,用来连接隐层和输出层
self.logRegressionLayer = LR(
input=self.hiddenLayer.output,
n_in=n_hidden,
n_out=n_out
)
# 规则化,常用的是L1和L2。是为了防止过拟合。
# 其计算方式很简单。具体规则化的内容在文章下方详细说一下
# L1项的计算公式是:将W的每个元素的绝对值累加求和。此处有2个W,因此两者相加。
self.L1 = (
abs(self.hiddenLayer.W).sum()
+ abs(self.logRegressionLayer.W).sum()
)
# L2项的计算公式是:将W的每个元素的平方累加求和。此处有2个W,因此两者相加。
self.L2_sqr = (
(self.hiddenLayer.W ** 2).sum()
+ (self.logRegressionLayer.W ** 2).sum()
)
# 和LR一样,计算负对数似然函数,计算误差。
self.negative_log_likelihood = (
self.logRegressionLayer.negative_log_likelihood
)
self.errors = self.logRegressionLayer.errors
self.params = self.hiddenLayer.params + self.logRegressionLayer.params
self.input = input 现在就来解释一下篇头中提到的代价函数是基本一样的原因。
首先来说一下规则化。当我们训练模型试图让它在面对新的输入样本时产生更好的结果(就是有更好的泛化能力),我们往往会采用梯度下降方法。而本实验中用到的MSGD方法却没有考虑到一个问题,那就是过拟合现象。一旦出现过拟合,那么在面对新的样本时很难有好的结果。为了控制过拟合,一个比较有效的方法就是规格化。就是给每个参数
那么规则化后的代价函数就是:
就是加入了一个
其中:
不难发现,当把公式
原则上,当代价函数中增添了规则化项之后会使得网络拟合函数时更加平滑。所以,理论上,最小化
实际上一个模型有一个简单的超平面解并不意味着它的泛化能力很好。实验证明,含有这种规格化项的神经网络的泛化能力更好,尤其是在比较小的数据集上。
下面来看一下带有规则化项的代价函数代码如何写:
# 代价函数,这是一个符号变量,cost并不是一个具体的数值。当传入具体的数据后,
# 其才会有具体的数据产生。在原代价函数的基础上加入规则参数*规则项。
cost = (
classifier.negative_log_likelihood(y)
+ L1_reg * classifier.L1
+ L2_reg * classifier.L2_sqr
)最后就是参数求梯度以及参数更新,基本和LR的区别不大。训练模型函数、测试模型函数、验证模型函数和LR相同。至此,代码实现基本告一段落,可以下载全部代码运行测试。其他的代码注释不多,因为应该比较简单。只有一个mlp.py文件。下载来,直接python mlp.py即可运行。如果有不懂的地方可以留言,也可以翻看上一篇LR的实现。本文所介绍的mlp去对mnist分类官方给出的一个结果是:
Optimization complete. Best validation score of 1.690000 % obtained at iteration 2070000, with test performance 1.650000 %
The code for file mlp.py ran for 97.34m我也正在跑代码,因为还是比较耗时的。这个网址里边记录了目前为止所做过的实验以及结果。有兴趣的可以看一下。最好的误差能达到0.23%了,天呢,接近100%的识别率了。
参考目录:
1. 官方教程
2. Stanford机器学习—第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
3. 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet5之LR