这篇博客我们介绍基于StructuredStreaming进行实时流算子开发,并将结果输出到kafka中。
StructuredStreaming使用的数据类型是DataFrame和Dataset。
从Spark 2.0开始,DataFrame和Dataset可以表示静态(有界数据),以及流式(无界数据)。与静态Dataset/ DataFrame类似,用户可以使用公共入口点SparkSession 从流源创建流DataFrame /Dataset,并对它们应用与静态DataFrame / Dataset相同的操作。如果你不熟悉Dataset / DataFrame,请戳《Dataset常用方法》和《DataFrame常用方法》
接下来,我们以Append输出模式为例,讲解流式DataFrame的创建,基础操作和窗口操作,以及将结果输出到外部存储介质的方法。
1、流式DataFrame创建
以Kafka作为输入源为例。
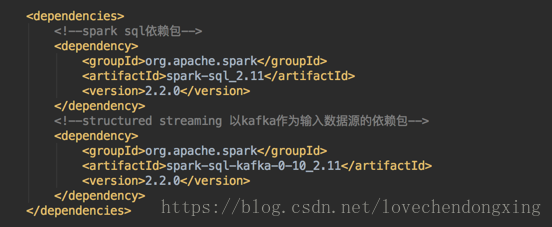
a、引入两个依赖包
b、创建SparkSession入口,用于与集群资源管理器交互

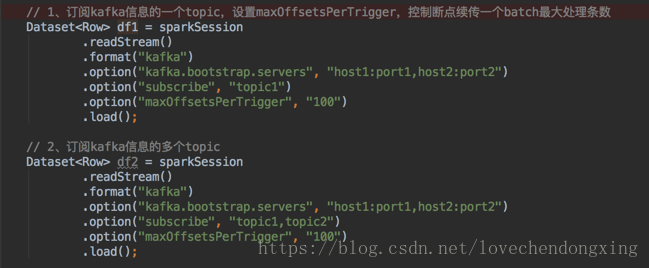
c、指定kafka的地址和端口号,从Kafka的一个或者多个topic订阅输入源,创建流失DataFrame
设置maxOffsetsPerTrigger,控制断点续传一个batch最大处理条数,避免一次处理太多任务导致内存溢出。
2、流式DataFrame基本操作
基本操作指不包含聚合的操作。
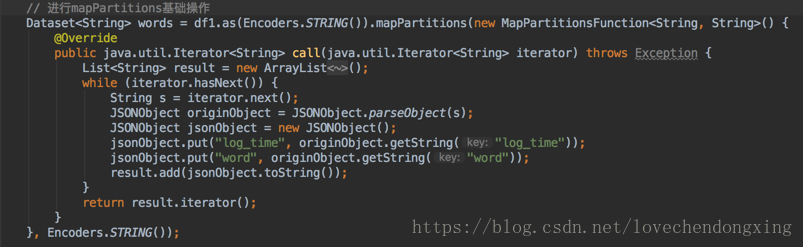
流式DataFrame基本操作支持大部分的静态的DataFrame操作,如 从无类型,类似SQL的操作(例如select,where,join)到类型化的RDD类操作(例如map,filter,flatMap)都支持。
详细参考《Dataset常用方法》和《DataFrame常用方法》
流式DataFrame部分不支持的操作如下:
#1)不支持take、distinct操作
#2)有条件地支持 streaming 和 static Datasets 之间的 Outer joins 。
-
- 不支持使用 streaming Dataset 的 Full outer join
- 不支持在右侧使用 streaming Dataset 的 Left outer join
- 不支持在左侧使用 streaming Dataset 的 Right outer join
- 不支持两种 streaming Datasets 之间的任何种类的 join
3、流式DataFrame窗口操作
Append模式的聚合操作因为需要使用Watermark删除旧的聚合结果,所以,只支持基于Watermark(用于控制延迟时间)的Event-Time(事件时间)聚合操作,不指定Watermark的聚合操作不支持。
基于Watermark(用于控制延迟时间)的Event-Time(事件时间)聚合操作 一般通过Window时间窗口实现。
涉及四个概念:
窗口长度:窗口的持续时间,如10分钟的数据为一个窗口
窗口滑动间隔:窗口操作的时间间隔,比如间隔5分钟,表示每5分钟生成一个Window
计算触发时间:依据指定的trigger batch时长作为触发时长,Spark去Kafka订阅这个时长产生的数据,获取数据的Event-Time,将数据分发到对应的Window中进行计算
Watermark:wm的值 = 当前batch数据中最大 Event-Time - late threshold 。Event-Time大于wm的延迟数据将被处理 ,但数据小于的数据将被丢弃。
当窗口的上界小于wm值,代表窗口中的所有数据的Event-Time都小于wm了,不需要在对这个窗口更新,所以这个窗口在Result Table中的聚合结果将被输出到外部存储介质Kafka
以每隔5分钟,统计前10分钟出现的单词的次数,并将结果写入Kafka为例,讲解代码编写和运行机制:
#1)代码如下:
每隔5分钟,对10分钟时间窗口和单词word进行分组,并统计每个分组的个数。 当数据延迟超过10分钟到达Spark,延迟数据会被忽略。

a、 withWatermark函数第一个参数是 数据表中的时间戳字段的字段名,如图中的timestamp,第二个参数是延迟的时间阈值,如图中的10 分钟
注意:withWatermark要紧跟dataFrame,写在groupBy之前,否则会报错
b、window函数第一个参数是时间戳字段名,需要与withWatermark函数的一个参数名一致,否则会报错,第二个参数是窗口长度,第三个参数是滑动间隔
#2)实现机制如下图:
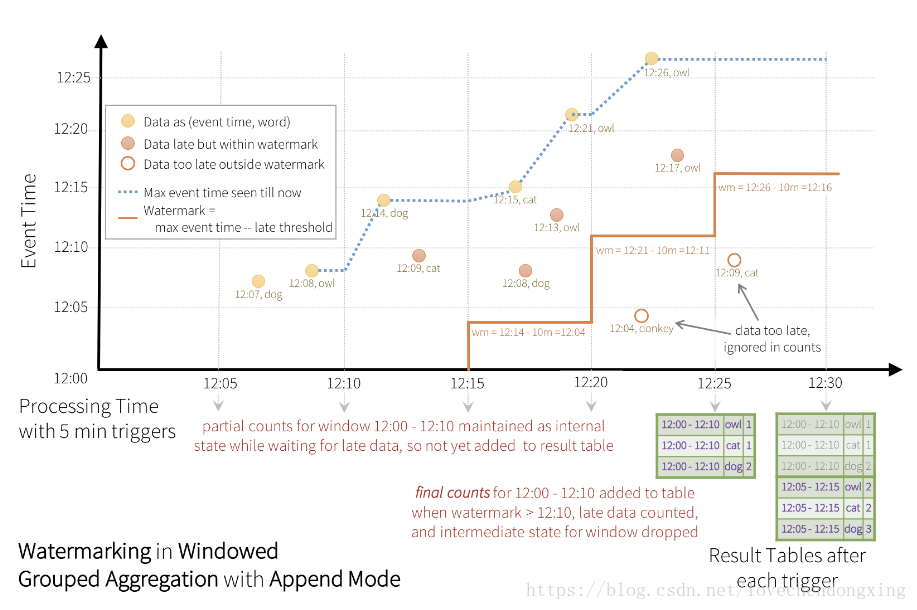
a、横坐标是触发时长,5分钟触发一次执行,Spark去Kafka订阅这个时长产生的数据,获取数据的Event-Time,将数据分发到对应的Window中进行计算。
如图中,12:15~12:20这个batch获取的数据共4条,其中12:15和12:21是正常到达Spark的,而12:08和12:13这两条是延迟到达Spark
b、纵坐标是数据的Event-Time
c、蓝色虚线上的点是每次batch的数据中,获取到的最大的Event-Time
d、红色实现代码当前计算得到的最大的waterMark
e、黄色实心的圆圈代表正常抵达的数据;红色实心的圆圈代表延迟的数据,但是在延迟阈值范围内,有被处理;红色空心的圆圈代码延迟的数据,但在延迟阈值范围外,数据被丢弃了。
如图中,12:25分触发时,上一个batch 计算得到的wm=batch最大的event-time 12:21 减去 设定的 延迟阈值 10分钟 = 12:11分,因为12:00~12:10这个窗口的最大值已经全部小于wm了,所以,该窗口的值从Result Table输出到Kafka
同理,12:30分触发时,上一个batch 计算得到的wm=batch最大的event-time 12:26 减去 设定的 延迟阈值 10分钟 = 12:16分,因为12:05~12:15这个窗口的最大值已经全部小于wm了,所以,该窗口的值从Result Table输出到Kafka
4、流式结果输出到Kafka,并启动流式计算
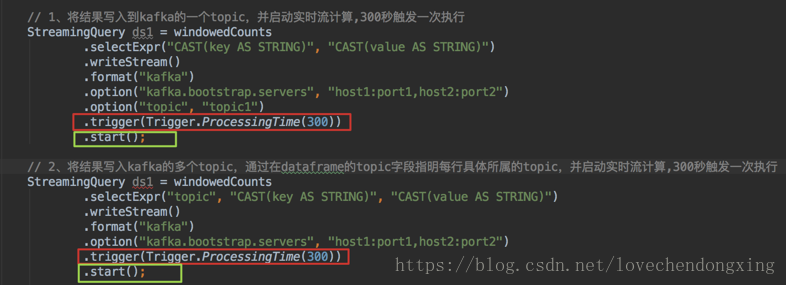
#1)将结果写入kafka的一个topic,并调用start函数启动实时流计算,300秒触发一次执行
#2)将结果写入kafka的多个topic,通过在dataframe的topic字段指明每行具体所属的topic,并调用start函数启动实时流计算,300秒触发一次执行
注意:一定要调用start()函数,实时流计算才会启动!!!
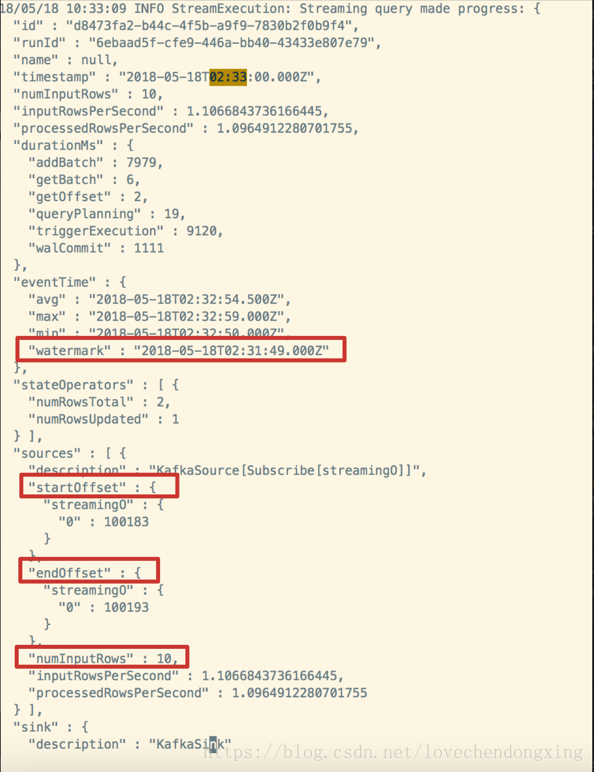
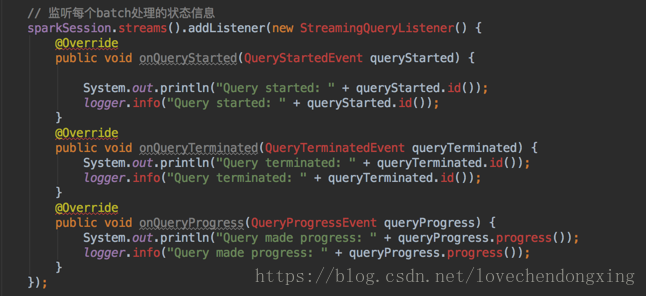
4、实时流作业监控
通过异步的方式对实时流进行监控,输出每次batch触发从Kafka获取的起始和终止的offset,总条数,以及通过最大Event-Time计算得到的Watermark等
代码如下:
每次batch触发得到的日志如下: