1. kafka的定义
kafka是一个分布式消息系统,由linkedin使用scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。具有高水平扩展和高吞吐量。
2,基本的概念
(1)消费者(consumer):从消息队列中请求消息的客户端应用程序
(2)生产者(producer):向broker发布消息的应用程序
(3)AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
kafka支持的客户端语言:Kafka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ruby、Go、Javascript
可以使用以上任何一种语言和kafka服务器进行通信(即辨析自己的consumer从kafka集群订阅消息也可以自己写producer程序)
1. 主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
2. 分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
3 台服务器
192.168.120.207 master
192.168.120.208 salve
192.168.120.206 salve2
3,zookeeper 集群搭建
1)首先需要安装 jdk
三个节点都需要安装 jdk 支持:
(注意)三个节点都要安装 tar zxvf jdk1.8.0_91.tar.gz -C /usr/local/ vim /etc/profile ##在最后添加java环境 JAVA_HOME=/usr/local/jjdk1.8.0_91 JAVA_BIN=$JAVA_HOME/bin PATH=$PATH:$JAVA_BIN CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH #把添加链接到bin目录下 ln -vs /usr/local/jdk1.8.0_91/bin/java /usr/bin/ #测试java环境,打印java版本 java -version
2)首先需要安装 zookeeper集群
##解压zookeeper tar xf zookeeper.tar.gz -C /usr/local/ cd /usr/local/zookeeper/conf/
##创建zookeeper所需要的目录和myid文件 mkdir -pv /opt/{zkdata,kafka_data}
##zkdata是zookeeper数据目录
##kafka_data是kafka数据目录
##找到zoo.cfg,没有就zoo_sample.cfg复制成zoo.cfg vim zoo.cfg #配置文件如下:
tickTime=2000 initLimit=10 syncLimit=5 clientPort=30000 server.3=192.168.120.206:30010:30020 server.2=192.168.120.208:30010:30020 server.1=192.168.120.207:30010:30020
配置说明:
tickTime:客户端与服务器或者服务器与服务器之间每个tickTime时间就会发送一次心跳。通过心跳不仅能够用来监听机器的工作状态,还可以通过心跳来控制Flower跟Leader的通信时间,默认2秒 initLimit:集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。 syncLimit:集群中flower服务器(F)跟leader(L)服务器之间的请求和答应最多能容忍的心跳数。 dataDir:该属性对应的目录是用来存放myid信息跟一些版本,日志,跟服务器唯一的ID信息等。
clientPort:客户端连接的接口,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问!这个端口默认是2181,我自定义为30000。
30000是zookeeper端口
30010是zookeeper管理端口(leader)
30020是zookeeper节点端口(follower)
service.N=YYY:A:B N:代表服务器编号(也就是myid里面的值) YYY:服务器地址 A:表示 Flower 跟 Leader的通信端口,简称服务端内部通信的端口(默认2888) B:表示 是选举端口(默认是3888)
其他节点配置相同,除以下配置:
echo 1 > /opt/zkdata/myid #myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper无法启动
我的主机:192.168.120.207是1所以,echo 1 > /opt/zkdata/myid,其他主机变更echo写入的数字即可
启动zookeeper:
/usr/local/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... taSTARTED
zkServer.sh start 启动
zkServer.sh status 查看启动状态,看那个是leader节点,因为是集群自动选举的。



启动成功,到这里zookeeper集群搭建好了

30010端口是leader,因为是自定义的,再说一遍。
3)首先需要安装 kafka集群
三个节点一样的操作 解压kafka安装包 tar xf kafka_2.12-0.10.2.1.tgz -C /usr/local/
vim /usr/local/kafka_2.12-0.10.2.1/config/server.properties
##kafka配置文件如下:
主要修改标记的4项,没特殊需求可以暂时不动其他配置项。
############################# Server Basics #############################
broker.id=1 #id唯一,可以与之前的myid设置成一致的。
############################# Socket Server Settings #############################
listeners=PLAINTEXT://192.168.120.206:9092 ##设置本机ip及端口
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
log.dirs=/opt/kafka_data ##kafka数据目录
num.partitions=1
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
############################# Log Retention Policy #############################
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
zookeeper.connect=192.168.120.207:30000,192.168.120.208:30000,192.168.120.206:30000 ##是zookeeper集群地址和端口,以,分隔
zookeeper.connection.timeout.ms=6000
3)启动kafka集群
##后台启动kafka,每台都要启动
/usr/local/kafka_2.12-0.10.2.1/bin/kafka-server-start.sh -daemon ../config/server.properties
##查看端口确保:30000和30010或者30020,因为这是zookeeper的端口,这些端口没有kafka是起不起来的。
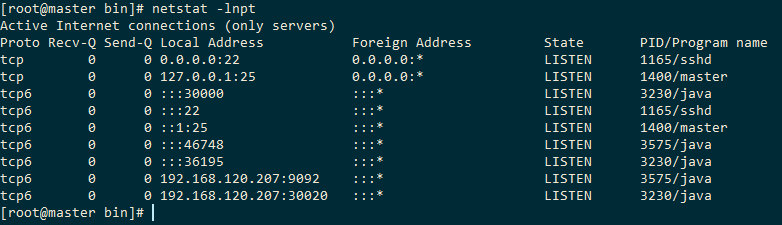
4)创建主题验证生产者与消费者
创建主题为pytest1:
创建命令:/usr/local/kafka_2.12-0.10.2.1/bin/kafka-topics.sh --create --zookeeper 192.168.120.208:30000,192.168.120.207:30000,192.168.120.206:30000 --replication-factor 1 --partitions 1 --topic pytest1 Created topic "pytest1".

参数解释:
--create ##创建
--zookeeper ##在zookeeper集群,以英文逗号分隔
--replication-factor ##复制多少份
--partitions ##复制多少份
--topic ##主题名称
启动一个生产者,多个消费者:
生产者:
./kafka-console-producer.sh --broker-list 192.168.120.207:9092,192.168.120.208:9092,192.168.120.206:9092 --topic pytest1

消费者:
/usr/local/kafka_2.12-0.10.2.1/bin/kafka-console-consumer.sh --bootstrap-server 192.168.120.207:9092,192.168.120.208:9092,192.168.120.206:9092 --topic pytest1 --from-beginning

