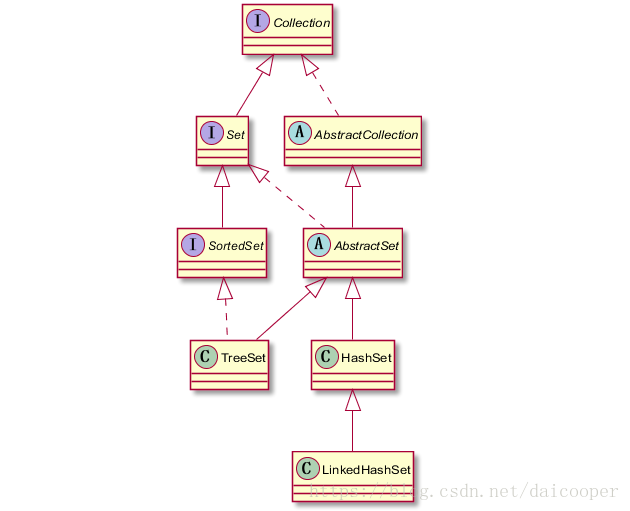
实现 Set 接口的类
| 类 | 描述 |
|---|---|
| AbstractSet | 继承 AbstractCollection 并实现大多数 Set 接口中的方法,为其他类集合的实现提供方便 |
| HashSet | 为了使用哈希表而继承 AbstractSet,内部使用了一个哈希表来实现 Set 集合,并允许存放 null 元素。对基本操作提供常数级的时间性能 |
| TreeSet | 实现 数结构 一个集合。继承了 AbstractSet,内部使用 TreeMap 实现,保证类集中的元素按照升序排列。可按照自然顺序对元素进行排序,也可以通过比较器对元素进行排序。 |
| LinkedHashSet | 继承了 HashSet 并通过维护双向列表实现集合 |
实现 Set 接口的 类如下图:
HashSet类
HashSet 继承 AbstractSet 并实现 Set 接口。它创建一个类集,该类集使用散列表进行存储。散列表通过使用散列算法的机制来存储信息。
在散列(Hashing)中,一个关键字被用来确定唯一的一个值,称为 散列值(Hashcode)。而散列值被用来当做与关键字相连的数据的存储下标。关键字到其散列值的转换是自动执行的——用户看不到散列值本身。程序代码也不能直接索引散列表。散列法的优点在于对大的集合,它允许一些基本操作,如 add(), contains(), remove() 和 size() 方法的允许时间保持不变。
注意:存储在 HashSet 中的元素必须正确覆盖 java.lang.Object 中定义的 hashCode() 方法。
HashSet的构造方法
HasSet();
HashSet(Collection c);
HashSet(int capacity);
HashSet(int capacity, float fillRatio);第一种形式构造一个默认的散列集合;第二种形式用 c 中的元素初始化散列集合;第三种形式用 capacity 初始化散列集合的容量;第四种形式用它的参数初始化散列集合的容量和填充比(也称为加载容量)。填充比必须介于 0.0 到 1.0 之间,它决定在散列集合向上调整大小之前,有多少能被充满。具体来说,就是当元素的个数大于散列集合容量乘以它的填充比时,散列集合被扩大。对于没有获得填充比的构造函数,默认使用 0.75 。
应该注意散列集合并没有确保其元素的顺序。如果需要排序存储,另一种类集——TreeSet将是一个更好的选择。
HashSet的使用:
import java.util.*;
public class HashSetDemo {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add("A");
hs.add("B");
hs.add("C");
hs.add("D");
hs.add("B");
hs.add("A");
System.out.println(hs);
}
}
// [A, B, C, D]
// 没有重复元素TreeSet类
TreeSet 是使用树结构存储元素的类集合,对象按升序存储。访问和检索速度是很快的。在存储了大量的需要进行快速检索的排序信息的情况下,TreeSet是一个很好的选择。
下面的构造函数定义为:
TreeSet()
TreeSet(Collection c)
TreeSet(Comparator comp)
TreeSet(SortedSet ss)第一种形式构造一个空的树集合,该树集合将根据其元素的自然顺序按升序排序。第二种形式构造一个包含了 c 的元素的树集合。 第三种形式构造一个空的树集合,它按照由 comp 指定的比较函数进行排序。第四种形式构造一个包含了 ss 的元素的树集合。
import java.util.*;
public class ArrayListDemo {
public static void main(String[] args) {
TreeSet ts = new TreeSet();
ts.add("D");
ts.add("E");
ts.add("F");
ts.add("C");
ts.add("A");
ts.add("B");
ts.add("F");
ts.add("E");
System.out.println(ts);
System.out.println(ts.first());
System.out.println(ts.last());
}
}
// [A, B, C, D, E, F]
// A
// FTreeSet 按树存储其元素,它们被按照自然顺序自动排,也不能有重复元素。