和Lsit接口一样,Set接口也是Collection接口的子接口,这两个接口的最大不同是List接口中的子类集合内容允许重复,但
是Set接口子类的集合允许重复,除此之外,Set接口没有对Collection接口进行扩充,所以Set接口中没有List接口中的get()方
法。你可以轻松的询问某个对象是否在某个Set中,所以查找是Set中最重要的操作。而且Set是根据对象的值来确定归属性
的。
现在看一下Set接口的类关系图,我再做下面的一系列介绍。
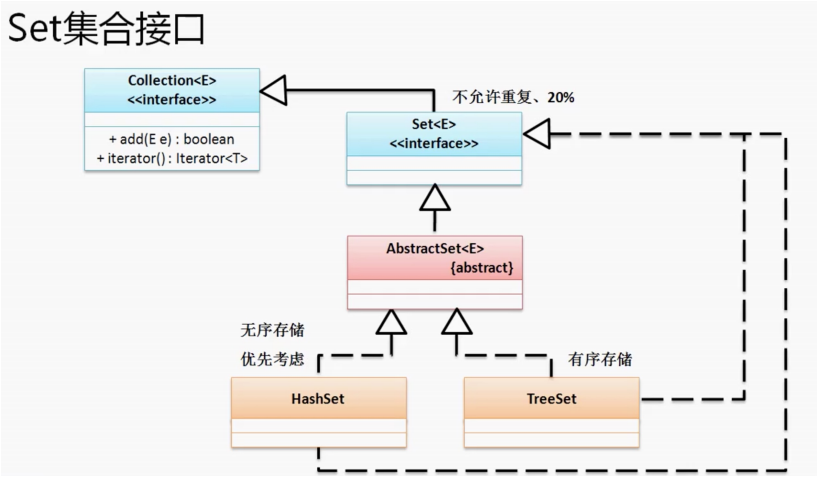
Set接口有两个常用的实现子类:HashSet,TreeSet。
HashSet:
首先示例一个存放Integer对象的HashSet
public class Main{
public static void main(String[] args){
Set<String> set = new HashSet<>();
set.add("Message C");
set.add("Message A");
set.add("Message B");
set.add("Message C");
set.add("Message D");
set.add("Message E");
set.add("Message B");
System.out.println(set);
}
}
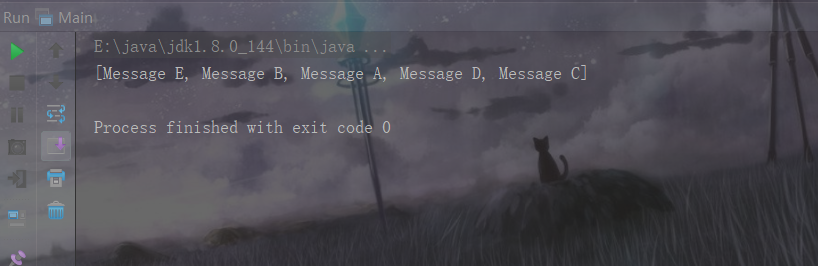
根据结果我们可以发现
1:虽然添加了重复的元素,但是结果中每个元素只出现了一次
2:HashSet存放数据完全没有规律
出于速度的原因,HashSet的元素存储使用了散列函数,而TreeSet的元素存储使用的是红黑树的数据结构。
HashSet重复元素判断
如果HashSet中存放的系统类对象,那么在进行重复元素判断的时候需要依靠ComParable接口来完成,例如Integer类就
实现了ComParable接口。但是,如果存放的是自定义类对象,由于其和ComParable接口没有关系,那么进行重复元素判断的
时候就需要覆写以下两个方法。
1:hash码:public native int hashCode();
2:对象比较: public boolean equals(Object obj);
对象比较的操作一共有两步:通过对象的hash码找到一个对象的信息,编码匹配之后在调用equals()进行内容的比较。
例子:覆写hashCode()与equals()方法消除重复元素
class Student implements Comparable<Student>{
private String name;
private Integer age;
public Student(String name, Integer age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "[name = "+this.name+" "+"age = "+this.age+"]";
}
@Override
public boolean equals(Object obj) {
if(obj == null || getClass() != obj.getClass()){
return false;
}
if(obj == this){
return true;
}
if((obj instanceof Student)) {
Student student = (Student) obj;
return student.age.equals(this.age) && student.name.equals(this.name);
}
return false;
}
@Override
public int hashCode() {
return Objects.hash(name,age);
}
@Override
public int compareTo(Student o) {
if(this.age > o.age){
return 1;
}else if(this.age < o.age){
return -1;
}else {
return this.name.compareTo(o.name);
}
}
}
public class Main{
public static void main(String[] args){
Set<Student> set1 = new HashSet<>();
set1.add(new Student("A",1));
set1.add(new Student("B",2));
set1.add(new Student("C",3));
set1.add(new Student("B",3));
set1.add(new Student("A",1));
System.out.println(set1);
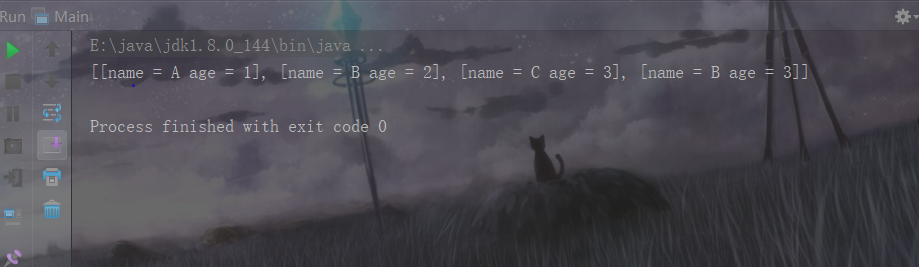
因为使用hashSet,所以集合中元素是乱序的,但是在结果中已经去掉了重复的元素。
要注意的是,如果要去重,一定要同时覆写equals()和hashCode()两个方法,重复对象判断必须这两个方法同时返回相同
才能判断为相同。
TreeSet:
首先看TreeSet的使用方法,和hashSet的使用方法相似
public class Main{
public static void main(String[] args){
Set<String> set = new TreeSet<>();
set.add("Message C");
set.add("Message A");
set.add("Message B");
set.add("Message C");
set.add("Message D");
System.out.println(set);
}
}
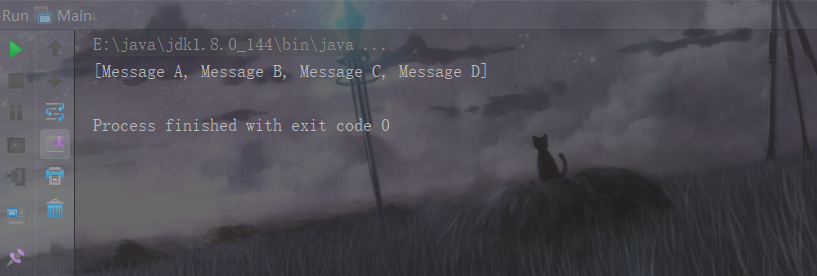
我们发现TreeSet相比于hashSet还实现了升序排序。
TreeSet排序:
如果进行的是自定义类对象的排序,那么对象所在的类就必须实现Comparable接口并且覆写compareTo()方法,并且类中
的所有属性都必须参加比较操作。
示例:使用TreeSet排列自定义类对象
class Person implements Comparable<Person> {
private String name;
private Integer age;
public Person(String name, Integer age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name = "+this.name+" age = "+this.age;
}
@Override
public int compareTo(Person o) {
if(this.age > o.age){
return 1;
}else if(this.age < o.age){
return -1;
}else {
return this.name.compareTo(o.name);
}
}
}
public class Main{
public static void main(String[] args){
Set<Person> set = new TreeSet<>();
set.add(new Person("A",1));
set.add(new Person("B",2));
set.add(new Person("C",3));
set.add(new Person("B",3));
set.add(new Person("A",1));
System.out.println(set);
}
}
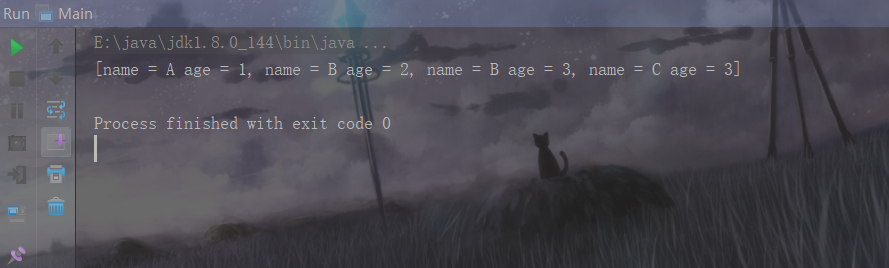
因为在比较排序的时候类中所有属性都要参与比较,如果类中有很多属性的话,所以使用TreeSet存放自定义类对象过于麻
烦了,所以还是推荐使用hashSet来存储自定义类对象。
去重的操作依靠Comparable接口来完成,所以我们不必像hashSet那样取覆写hashCode()方法和equals()方法。
关于Set接口的内容就现总结到这里,希望能对大家有所帮助。