版权声明:本文为博主原创文章,未经博主允许不得转载。转载请注明出处:http://blog.csdn.net/autocyz?viewmode=contents——autocyz https://blog.csdn.net/autocyz/article/details/53149760
Contrastive Loss (对比损失)
在caffe的孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。contrastive loss的表达式如下:
这种损失函数最初来源于Yann LeCun的Dimensionality Reduction by Learning an Invariant Mapping,主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。
观察上述的contrastive loss的表达式可以发现,这种损失函数可以很好的表达成对样本的匹配程度,也能够很好用于训练提取特征的模型。当y=1(即样本相似)时,损失函数只剩下
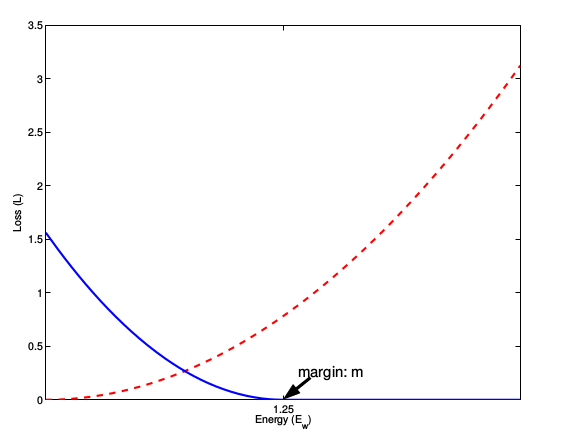
这张图表示的就是损失函数值与样本特征的欧式距离之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。