传输层是负责数据能够从发送端传输接收端。负责端与端之间的传输。端与端就相当于是两个进程之间的数据传输。
端口号
端口号是传输层协议的内容:
端口号是一个2字节16位的无符号整数;(0-65535之间一个数字,0-1023不推荐使用)
端口号用来标识一个进程,告诉操作系统,当前数据要交给哪一个进程来处理。(为什么不用pid=getpid()来标识一个进程,因为pid会变,如一个进程关闭再打开后,pid就会变,而一个进程的端口号不会变)
IP地址+端口号能够唯一标识网络上某一主机的某一进程;
在TCP/IP协议中, ⽤ “源IP”, “源端⼝号”, “⺫的IP”, “⺫的端⼝号”, “协议号” 这样⼀个五元组来标识⼀个通信(可以通过netstat -n查看);
端口号范围划分:0-2013 :知名端口号
ssh服务器 :22 端口
ftp服务器: 21端口
telnet服务器: 23端口
http服务器 : 80端口
https服务器:443端口
执行 cat /etc/services可以看到知名端口号:
netstat

netstat:
语法:netstat [选项]
功能:查看网络状态
常用选项:
n :拒接显示别名,能显示数字的全部转化为数字
l :仅列出有在listen(监听)的符状态
p :显示建立相关链接的程序名
t :(tcp)仅显示tcp相关选项
u : (udp) 仅显示udp相关选项
a: (all) 显示所有选项,默认不显示LISTEN相关
Udp协议
UDP协议端格式(UDP数据结构):
注:UDP头信息是8个字节;
UDP协议⾸部中有⼀个16位的最⼤⻓度. 也就是说⼀个UDP能传输的数据最⼤⻓度是65535即64K(包含UDP⾸部). (1k=1024字节,2^10=1024, 2 ^16=2 ^ 6 *1K),那么数据最大长度是64K(65535)-8;
如果我们需要传输的数据超过64K, 就需要在应⽤层⼿动的分包, 多次发送, 并在接收端⼿动拼装;但是就不会保证有序,需要用户在应用层进行排序(编号)。
如果校验出错,就会直接丢弃。
Udp特点:
1.无连接:知道对端的ip和端口号就直接进行传输,不需要建立连接;
2.不可靠:没有确认机制,没有重传机制,如果因为网络故障该段无法发到对方,udp协议层不会给应用层返回任何错误信息。
3.面向数据报:不能灵活的控制读写数据的次数和数量。
应⽤层交给UDP多⻓的报⽂, UDP原样发送, 既不会拆分, 也不会合并:如果发送端调⽤⼀次sendto, 发送100个字节, 那么接收端也必须调⽤对应的⼀次recvfrom, 接收100
个字节; ⽽不能循环调⽤10次recvfrom, 每次接收10个字节;
数据必须一整条发送或接受,不能拆分或者合并原因如下:
因为在udp头中定义了udp数据报长度,那么数据长度就国定,每一条数据都是按照这个长度进行发送或接受,这个特点有一个优点是不会造成粘包问题。
Udp缓冲区:
UDP没有真正意义上的 发送缓冲区. 调⽤sendto会直接交给内核, 由内核将数据传给网络层协议进⾏后续的传输动作;
UDP具有接收缓冲区. 但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序⼀致; 如果缓冲区满了, 再到达的UDP数据就会被丢弃;
UDP的socket既能读, 也能写, 这个概念叫做 全双⼯。
UDP传输优点:不会造成粘包问题,另外传输速度快(没有连接管理机制和可靠传输机制)
Tcp协议
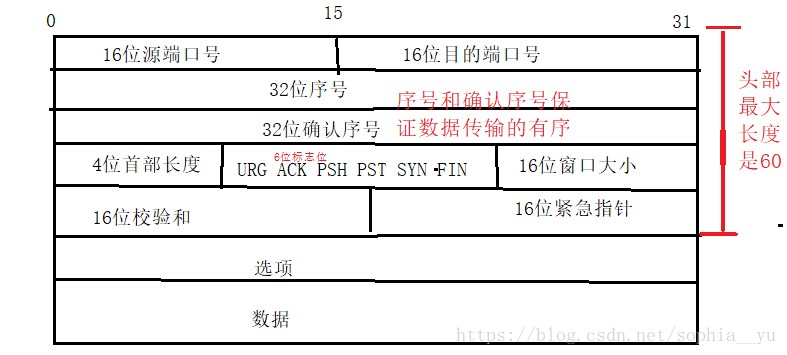
TCP协议格式:
注:1.4位TCP报头⻓度: 表⽰该TCP头部有多少个32位bit(有多少个4字节); 所以TCP头部最⼤⻓度是15 * 4 = 60 ;
2. 6位标志位:
URG: 紧急指针是否有效
ACK: 确认号是否有效
PSH: 提⽰接收端应⽤程序⽴刻从TCP缓冲区把数据读⾛
RST: 对⽅要求重新建⽴连接; 我们把携带RST标识的称为复位报⽂段
SYN: 请求建⽴连接; 我们把携带SYN标识的称为同步报⽂段
FIN: 通知对⽅, 本端要关闭了, 我们称携带FIN标识的为结束报⽂段
16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含TCP⾸部, 也包含TCP数据部分.
16位紧急指针: 标识哪部分数据是紧急数据;
16位窗⼝⼤⼩:指的是⽆需等待确认应答⽽可以继续发送数据的最⼤值
tcp是有连接可靠面向字节流传输。
连接管理机制:
可以查看这篇博客:https://blog.csdn.net/sophia__yu/article/details/82932194
可靠传输机制
1.确认应答机制:发送的每条数据都需要确认回复一下。
2.超时重传机制:发送方等待一段时间后还没有收到回复,就认为传输失败,将数据重传。这个超时时间是递增的,并且次数是有限制的,超过最大次数就认为网络断开。
3.重传有序: 重新传输可能会造成包的无序(后发送的数据可能会先到,先发的数据可能后到),序号和确认序号保证重新传输有序。
保证有序:序号按字节排序,发送的数据是1000字节,两者之间相互协商后加入把起始位置设为1,那么数据序号就是1-1000,当把数据发送 过去后,对端看到是1000个字节,而且起始序号是1,就认为是成功接收,然后回复1001,1001代表成功接收,并且接下来接收的数据序号从1001开始。如果先接受1001-2000序号数据,,会把这个数据放到缓冲区的1001-2000,前面的1-1000会空着。

tcp因为要保证可靠传输,导致性能有很大的消耗,为了提高tcp传输性能,需要一些其他的机制。
滑动窗口机制:
刚讨论的确认应答策略, 对每⼀个发送的数据段, 都要给⼀个ACK确认应答. 收到ACK后再发送下⼀个数据段. 这样做有⼀个⽐较⼤的缺点, 就是性能较差. 尤其是数据往返的时间较⻓的时候.而滑动窗口机制是一次发生多条数据,集中等待(快速重传)
在tcp头中有16位窗口大小:指的是⽆需等待确认应答⽽可以继续发送数据的最⼤值。
窗口越大,网络的吞吐量越大。
- 如果发生方没有接受到第一条数据的ack回复,但是接受到第二条数据的ack,那么它认为第一条数据也发送成功,不需要重传,这样就会提高性能;
- 如果发送方的数据没有成功发送(丢了),那么 接收方会连续三次ack说要的是第一条数据,但是并不会发送第二条已经接受到的ack,发送方收到三次(三次是因为有可能网络较慢,需要确定数据是否真的丢了。)ack请求就会进行数据重传。
一次发送的数据有多少取决于tcp协议中窗口大小字段----窗口大小在进行数据传输前会进行双方协商。这个窗口大小不会超过接收方接收缓冲区大小。
流量控制: - 为什么出现流量控制: 接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被打满, 这个时候如果发送端继续发送, 就会造成丢包, 继⽽引起丢包重传等等⼀系列连锁反应.因此TCP⽀持根据接收端的处理能⼒, 来决定发送端的发送速度. 即依靠流量控制。
- 通过不断的重新设定窗口大小,来告诉对方我能一次接收多少数据,最终达到一个流量控制的效果,避免因为发送太快,而处理太慢,导致接收方缓冲区塞满引起的大量丢包重传(当塞满后,会把缓冲区大小设为0,那么就不会再发送数据,当缓冲区空了后,会再次设置缓冲区大小进行数据传输)
拥塞控制
-
为什么出现拥塞控制:虽然TCP有了滑动窗⼝这个⼤杀器, 能够⾼效可靠的发送⼤量的数据. 但是如果在刚开始阶段就发送⼤量的数据,如果出现丢包,重传会使性能下降。
-
如何做:TCP引⼊ 慢启动 机制, 先发少量的数据, 探探路, 摸清当前网络拥堵状态, 再决定按照多⼤的速度传输数据;
一开始将拥塞窗口设置为1,当发送第一个数据收到ack后,认为网络比较好,第二次就会发生2个包,再次收到ack,第三次就会发生4个包,即发送包的数量按照质数增长。但是每发送数据包的时候,会将拥塞窗口和和接收端主机反馈的窗⼝⼤⼩做⽐较, 取较⼩的值作为实际发送大小,即拥塞窗口控制着tcp传输的慢启动;当然也不能一直增长,增长到阈值(协商窗口大小)后,发送数据速度变慢; -
在每次超时重发的时候,阈值会变成原来的⼀半, 同时拥塞窗⼝置回1;
-
当TCP通信开始后, 网络吞吐量会逐渐上升; 随着网络发⽣拥堵, 吞吐量会⽴刻下降;
-
拥塞窗口避免网络不好,导致丢包重传。总之,拥塞窗口是想尽一切办法将数据传输给对方。
延时应答
假设接收端缓冲区为1M. ⼀次收到了500K的数据; 如果⽴刻应答, 返回的窗⼝就是500K;但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;在这种情况下, 接收端处理还远没有达到⾃⼰的极限, 即使窗⼝再放⼤⼀些, 也能处理过来;如果接收端稍微等⼀会再应答, ⽐如等待200ms再应答, 那么这个时候返回的窗⼝⼤⼩就是1M; -
窗⼝越⼤, 网络吞吐量就越⼤, 传输效率就越⾼. 在保证网络不拥塞的情况下尽量提高传输效率;
-
接收方对接受到的数据能够快速处理,只要稍微延时一下进行ack回复,那么能够设置的窗口大小就会尽可能的大,一直保证一个tcp的最大吞吐量。假如是立即应答,那么有可能回复的这个窗口就比较小。
-
并不是所有包都可以延迟应答:数量限制:每隔N个包就应答一次;时间限制:超过最大延迟应答一次。
捎带应答机制:
将确认应答直接标记在即将发生的数据包内,那么这样不仅传输了数据还对上一次接受的数据进行应答(少传输一个应答包)
面向字节流 -
什么是面向字节流: 由于缓冲区的存在, TCP程序的读和写不需要⼀⼀匹配, 例如:
写100个字节数据时, 可以调⽤⼀次write写100个字节, 也可以调⽤100次write, 每次写⼀个字节;读100个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以⼀次read 100个字节, 也可以⼀次read⼀个字节, 重复100次; -
粘包问题:如果发送的字节数太短, 就会先在缓冲区⾥等待, 等到缓冲区长度差不多或者实际差不多将数据发送数据,那么就不清楚数据的边界,造成数据粘包问题。Udp不会造成粘包问你题,是因为UD头部中有数据报长度,那就可以计算出数据长度,有了数据长度,通过数据长度来找数据的边界,就不会造成粘包问题。
-
发送缓冲区和接受缓冲区都有可能出现粘包问题:
发送端:为了提高传输性能,因此将多个小包合到一块进行发送(但是也可以设置套接字,一次发送多少 )
接受端:将接受的数据放到接受缓冲区,如果处理慢,导致数据在缓冲区淤积合并 -
如何避免粘包问题:数据定长,特殊字符间隔(只要保证分隔符和正文字符不冲突即可),tlv格式数据( 可以在包头的位置, 约定⼀个包总⻓度的字段, 从⽽就知道了包的结束位置)。
Tcp的可靠性依靠下列: -
校验和:保证数据的准确性;
-
序列号:保证按序到达;
-
确认应答和超时重发:保证数据到达;
-
连接管理:保证两段建立起连接;
提高Tcp性能 -
滑动窗口:一次发多条数据,集中等待回复;
-
快速重传
-
延迟应答:稍等一会儿时间回复,提高吞吐量;
-
捎带应答:确认应答直接标记在即将发生的数据包内;
-
流量控制: 不断重新设置窗口大小,避免大量丢包重传导致性能下降;
-
拥塞控制:慢启动,快增大,尽可能使数据传输给对方;
Udp和Tcp谁更优?
TCP是可靠连接, 那么是不是TCP⼀定就优于UDP呢? TCP和UDP之间的优点和缺点, 不能简单, 绝对的进⾏⽐较。tcp和udp根据自己的特点应用于不同的场景:
TCP:⽤于可靠传输的情况, 应⽤于⽂件传输, 重要状态更新等场景;
UDP:⽤于对⾼速传输和实时性要求较⾼的通信领域, 例如, 早期的QQ, 视频传输等. 另外UDP可以⽤于广播。
用Udp实现可靠传输
参考TCP的可靠性机制, 在应⽤层实现类似的逻辑:
引⼊序列号, 保证数据顺序;
引⼊确认应答, 确保对端收到了数据;
引⼊超时重传, 如果隔⼀段时间没有应答, 就重发数据…