文章目录
传输层
在学习HTTP等应用层协议时,为了便于理解,可以简单的认为HTTP协议是将请求和响应直接发送到了网络当中。但实际应用层需要先将数据交给传输层,由传输层对数据做进一步处理后再将数据继续向下进行交付,该过程贯穿整个网络协议栈,最终才能将数据发送到网络当中。
传输层负责可靠性传输,确保数据能够可靠地传送到目标地址。为了方便理解,在学习传输层协议时也可以简单的认为传输层协议是将数据直接发送到了网络当中。
再谈端口号
端口号的作用
端口号(Port)标识一个主机上进行网络通信的不同的应用程序。当主机从网络中获取到数据后,需要自底向上进行数据的交付,而这个数据最终应该交给上层的哪个应用处理程序,就是由该数据当中的目的端口号来决定的。
从网络中获取的数据在进行向上交付时,在传输层就会提取出该数据对应的目的端口号,进而确定该数据应该交付给当前主机上的哪一个服务进程。
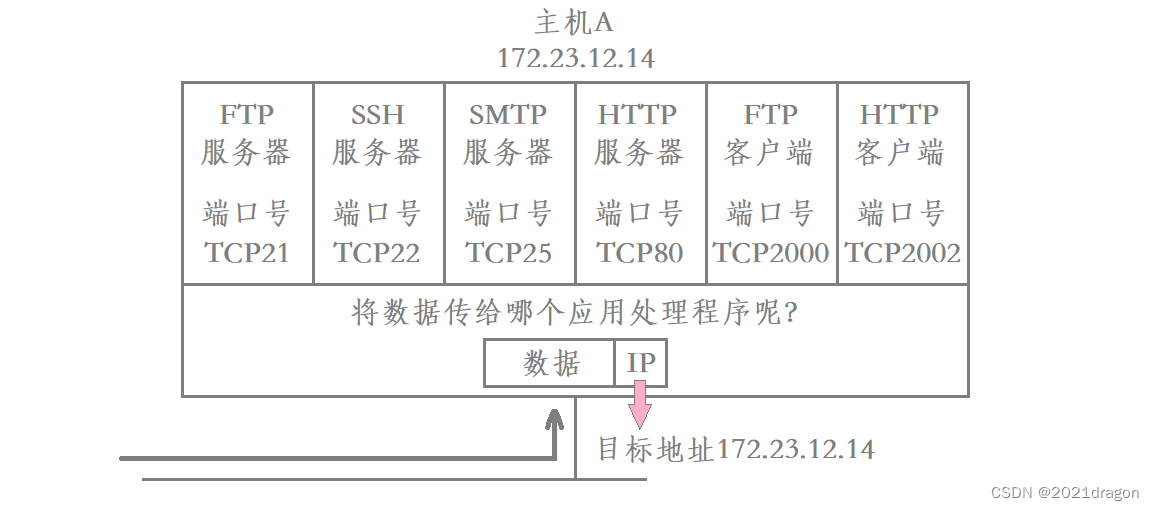
因此端口号是属于传输层的概念的,在传输层协议的报头当中就会包含与端口相关的字段。
五元组标识一个通信
在TCP/IP协议中,用“源IP地址”,“源端口号”,“目的IP地址”,“目的端口号”,“协议号”这样一个五元组来标识一个通信。
比如有多台客户端主机同时访问服务器,这些客户端主机上可能有一个客户端进程,也可能有多个客户端进程,它们都在访问同一台服务器。
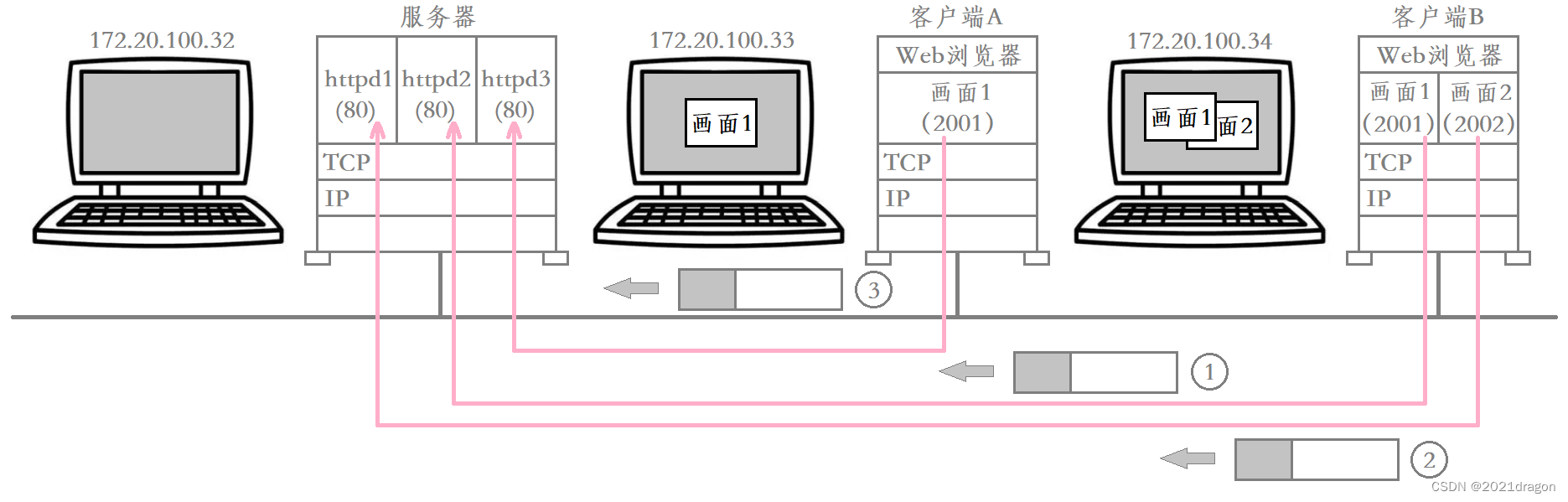
而这台服务器就是通过“源IP地址”,“源端口号”,“目的IP地址”,“目的端口号”,“协议号”来识别一个通信的。
- 先提取出数据当中的目的IP地址和目的端口号,确定该数据是发送给当前服务进程的。
- 然后提取出数据当中的协议号,为该数据提供对应类型的服务。
- 最后提取出数据当中的源IP地址和源端口号,将其作为响应数据的目的IP地址和目的端口号,将响应结果发送给对应的客户端进程。
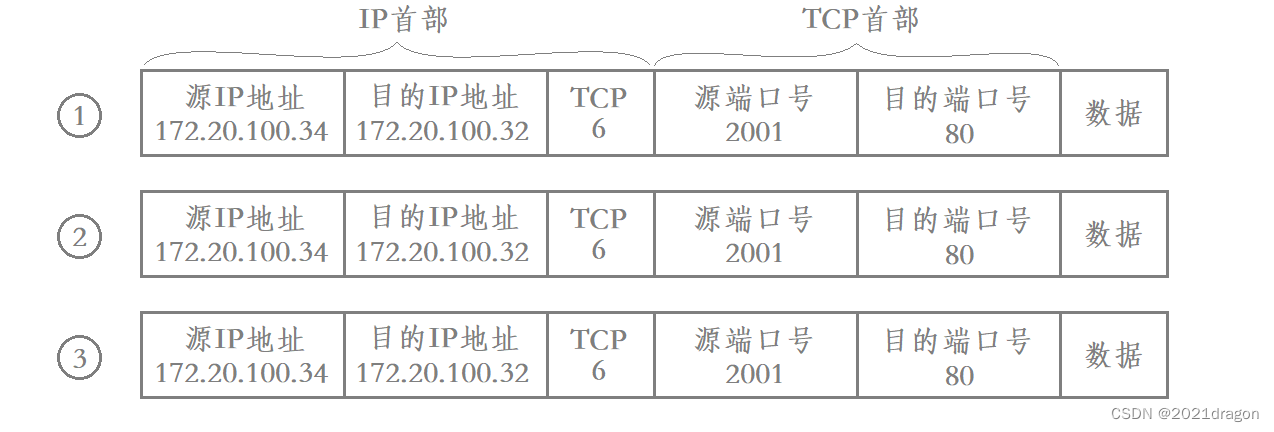
通过netstat命令可以查看到这样的五元组信息。
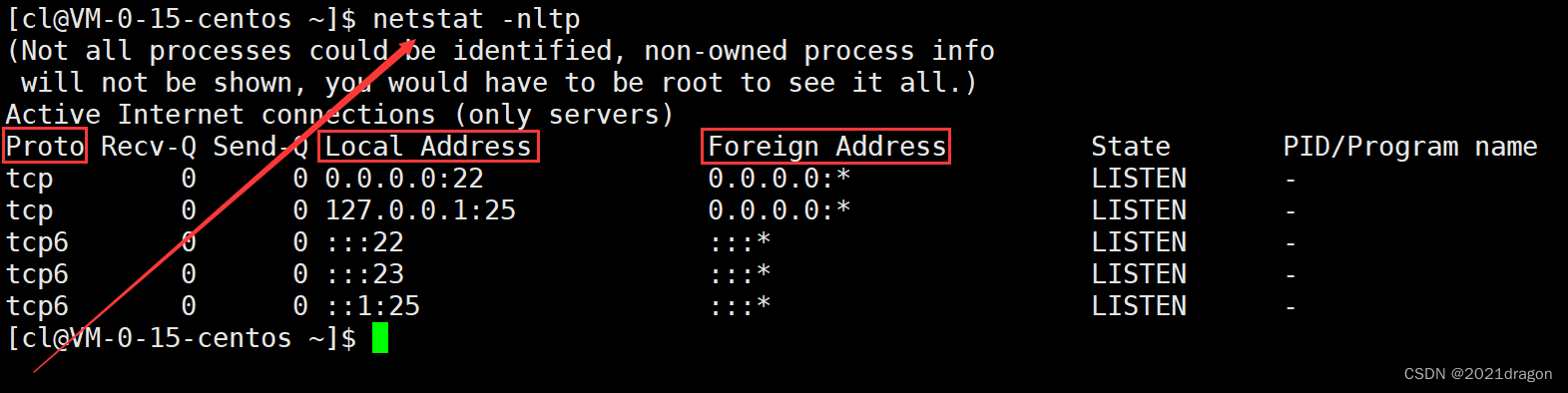
其中的Local Address表示的就是源IP地址和源端口号,Foreign Address表示的就是目的IP地址和目的端口号,而Proto表示的就是协议类型。
协议号 VS 端口号
- 协议号是存在于IP报头当中的,其长度是8位。协议号指明了数据报所携带的数据是使用的何种协议,以便让目的主机的IP层知道应该将该数据交付给传输层的哪个协议进行处理。
- 端口号是存在于UDP和TCP报头当中的,其长度是16位。端口号的作用是唯一标识一台主机上的某个进程。
- 协议号是作用于传输层和网络层之间的,而端口号是作用于应用层于传输层之间的。
端口号范围划分
端口号的长度是16位,因此端口号的范围是0 ~ 65535:
- 0 ~ 1023:知名端口号。比如HTTP,FTP,SSH等这些广为使用的应用层协议,它们的端口号都是固定的。
- 1024 ~ 65535:操作系统动态分配的端口号。客户端程序的端口号就是由操作系统从这个范围分配的。
认识知名端口号
常见的知名端口号
有些服务器是非常常用的,这些服务器的端口号一般都是固定的:
- ssh服务器,使用22端口。
- ftp服务器,使用21端口。
- telnet服务器,使用23端口。
- http服务器,使用80端口。
- https服务器,使用443端口。
查看知名端口号
我们可以查看/etc/services文件,该文件是记录网络服务名和它们对应使用的端口号及协议。
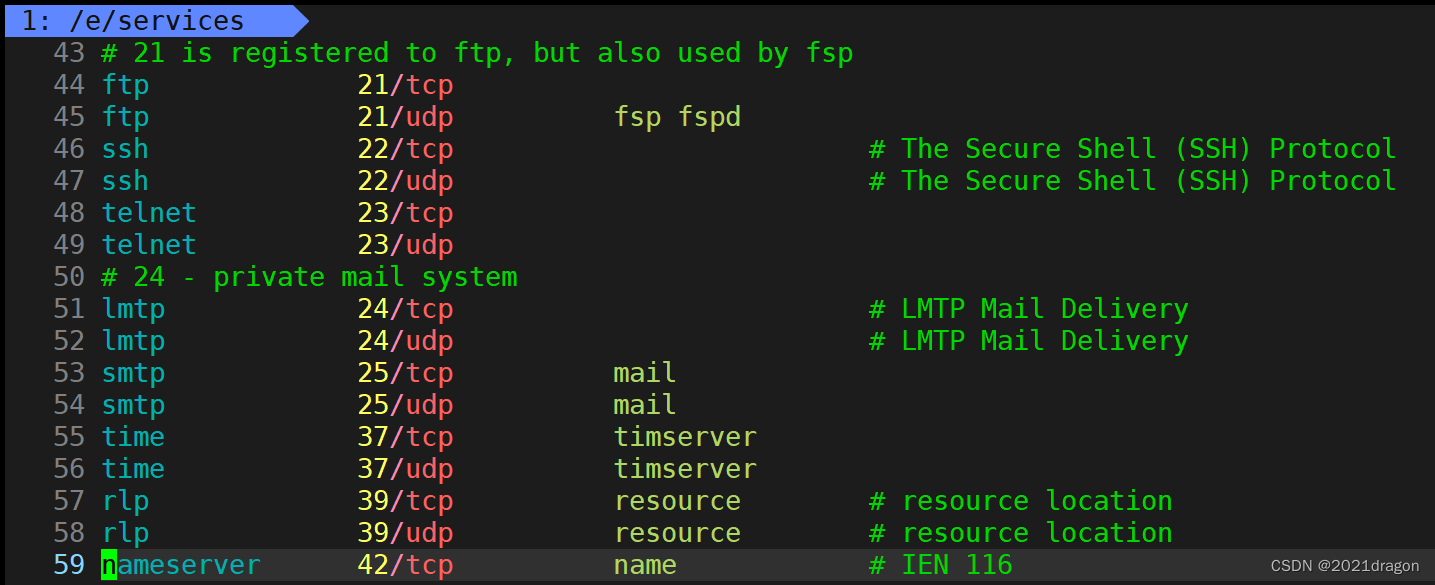
说明一下: 文件中的每一行对应一种服务,它由4个字段组成,每个字段之间用TAB或空格分隔,分别表示“服务名称”、“使用端口”、“协议名称”以及“别名”。
两个问题
一个端口号是否可以被多个进程绑定?
一个端口号绝对不能被多个进程绑定,因为端口号的作用就是唯一标识一个进程,如果绑定一个已经被绑定的端口号,就会出现绑定失败的问题。
一个进程是否可以绑定多个端口号?
一个进程是可以绑定多个端口号的,这与“端口号必须唯一标识一个进程”是不冲突的,只不过现在这多个端口唯一标识的是同一个进程罢了。
我们限制的是从端口号到进程的唯一性,而没有要求从进程到端口号也必须满足唯一性,因此一个进程是可以绑定多个端口号的。
netstat与iostat
netstat命令
netstat是一个用来查看网络状态的重要工具。
其常见的选项如下:
- n:拒绝显示别名,能显示数字的全部转换成数字。
- l:仅列出处于LISTEN(监听)状态的服务。
- p:显示建立相关链接的程序名。
- t(tcp):仅显示tcp相关的选项。
- u(udp):仅显示udp相关的选项。
- a(all):显示所有的选项,默认不显示LISTEN相关。
查看TCP相关的网络信息时,一般选择使用nltp组合选项。
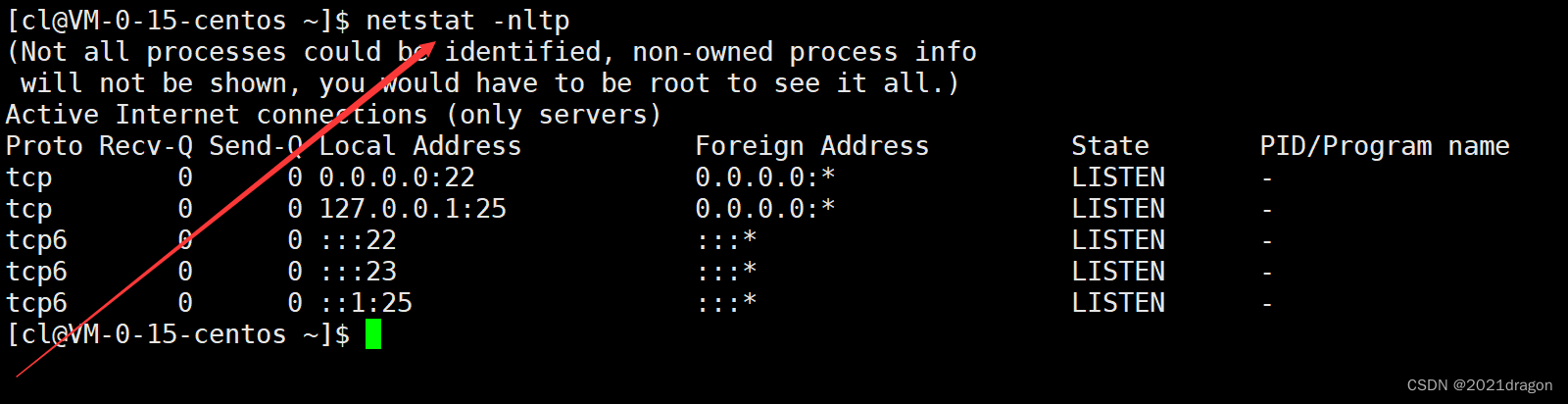
而查看TCP相关的网络信息时,一般选择使用nlup组合选项。
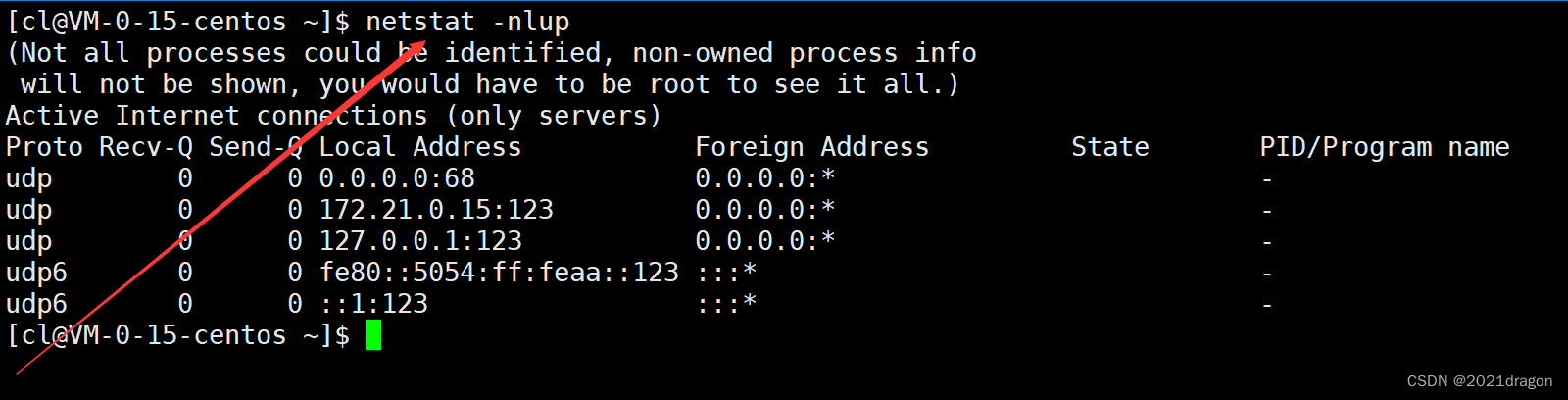
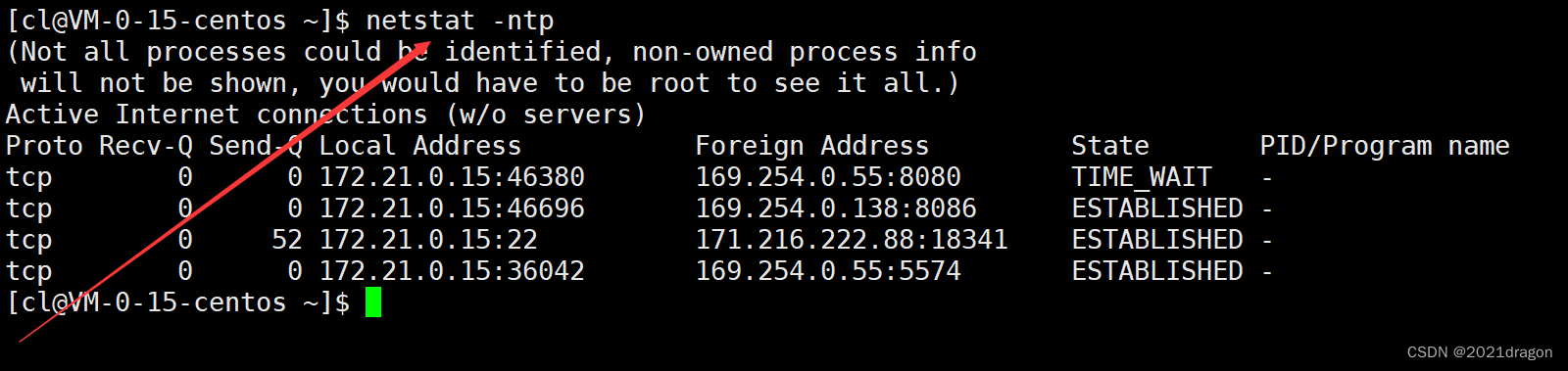
如果想查看LISTEN状态以外的连接信息,可以去掉l选项,此时就会将处于其他状态的连接信息显示出来。
iostat命令
iostat主要用于输出磁盘IO和CPU的统计信息。
其常见的选项如下:
- c:显示CPU的使用情况。
- d:显示磁盘的使用情况。
- N:显示磁盘列阵(LVM)信息。
- n:显示NFS使用情况。
- k:以KB为单位显示。
- m:以M为单位显示。
- t:报告每秒向终端读取和写入的字符数和CPU的信息。
- V:显示版本信息。
- x:显示详细信息。
- p:显示磁盘分区的情况。
比如我们要查看磁盘IO和CPU的详细信息。
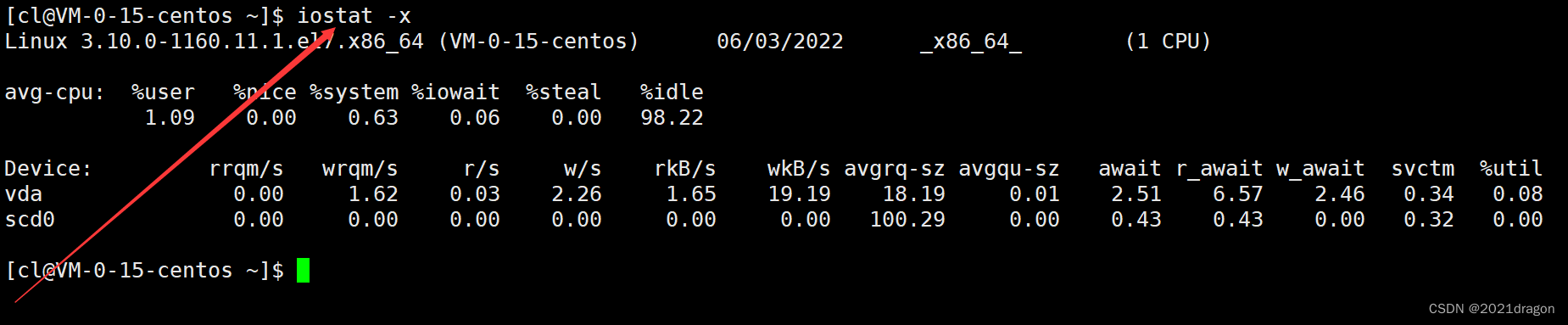
CPU属性值说明:
- %user:CPU处在用户模式下的时间百分比。
- %nice:CPU处在带NICE值的用户模式下的时间百分比。
- %system:CPU处在系统模式下的时间百分比。
- %iowait:CPU等待输入输出完成时间的百分比。
- %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
- %idle:CPU空闲时间百分比。
pidof
pidof命令可以通过进程名,查看进程id。
例如,我们用pidof命令查看我们自己编写的一个死循环进程。

pidof命令可以配合kill命令快速杀死一个进程。

UDP协议
UDP协议格式
UDP的位置
网络套接字编程时用到的各种接口,是位于应用层和传输层之间的一层系统调用接口,这些接口是系统提供的,我们可以通过这些接口搭建上层应用,比如HTTP。我们经常说HTTP是基于TCP的,实际就是因为HTTP在TCP套接字编程上搭建的。
而socket接口往下的传输层实际就是由操作系统管理的,因此UDP是属于内核当中的,是操作系统本身协议栈自带的,其代码不是由上层用户编写的,UDP的所有功能都是由操作系统完成,因此网络也是操作系统的一部分。
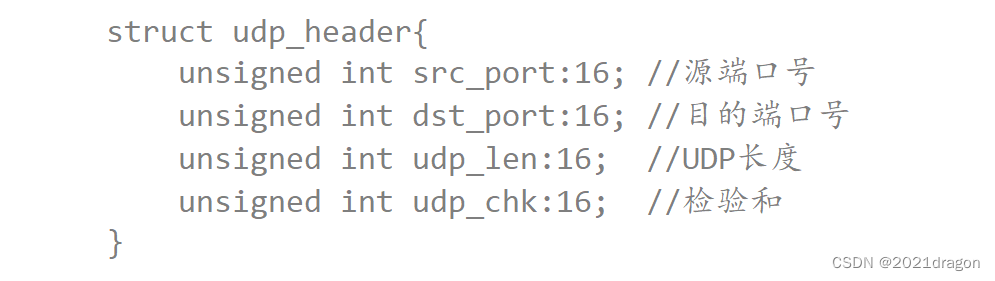
UDP协议格式
UDP协议格式如下:

- 16位源端口号:表示数据从哪里来。
- 16位目的端口号:表示数据要到哪里去。
- 16位UDP长度:表示整个数据报(UDP首部+UDP数据)的长度。
- 16位UDP检验和:如果UDP报文的检验和出错,就会直接将报文丢弃。
我们在应用层看到的端口号大部分都是16位的,其根本原因就是因为传输层协议当中的端口号就是16位的。
UDP如何将报头与有效载荷进行分离?
UDP的报头当中只包含四个字段,每个字段的长度都是16位,总共8字节。因此UDP采用的实际上是一种定长报头,UDP在读取报文时读取完前8个字节后剩下的就都是有效载荷了。
UDP如何决定将有效载荷交付给上层的哪一个协议?
UDP上层也有很多应用层协议,因此UDP必须想办法将有效载荷交给对应的上层协议,也就是交给应用层对应的进程。
应用层的每一个网络进程都会绑定一个端口号,服务端进程必须显示绑定一个端口号,客户端进程则是由系统动态绑定的一个端口号。UDP就是通过报头当中的目的端口号来找到对应的应用层进程的。
说明一下: 内核中用哈希的方式维护了端口号与进程ID之间的映射关系,因此传输层可以通过端口号得到对应的进程ID,进而找到对应的应用层进程。
如何理解报头?
操作系统是C语言写的,而UDP协议又是属于内核协议栈的,因此UDP协议也一定是用C语言编写的,UDP报头实际就是一个位段类型。
例如:
UDP数据封装:
- 当应用层将数据交给传输层后,在传输层就会创建一个UDP报头类型的变量,然后填充报头当中的各个字段,此时就得到了一个UDP报头。
- 此时操作系统再在内核当中开辟一块空间,将UDP报头和有效载荷拷贝到一起,此时就形成了UDP报文。
UDP数据分用:
- 当传输层从下层获取到一个报文后,就会读取该报文的钱8个字节,提取出对应的目的端口号。
- 通过目的端口号找到对应的上层应用层进程,然后将剩下的有效载荷向上交付给该应用层进程。
UDP协议的特点
UDP传输的过程就类似于寄信,其特点如下:
- 无连接:知道对端的IP和端口号就直接进行数据传输,不需要建立连接。
- 不可靠:没有确认机制,没有重传机制;如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息。
- 面向数据报:不能够灵活的控制读写数据的次数和数量。
注意: 报文在网络中进行路由转发时,并不是每一个报文选择的路由路径都是一样的,因此报文发送的顺序和接收的顺序可能是不同的。
面向数据报
应用层交给UDP多长的报文,UDP就原样发送,既不会拆分,也不会合并,这就叫做面向数据报。
比如用UDP传输100个字节的数据:
- 如果发送端调用一次sendto,发送100字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节;而不能循环调用10次recvfrom,每次接收10个字节。
UDP的缓冲区
- UDP没有真正意义上的发送缓冲区。调用sendto会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作。
- UDP具有接收缓冲区。但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃。
- UDP的socket既能读,也能写,因此UDP是全双工的。
为什么UDP要有接收缓冲区?
如果UDP没有接收缓冲区,那么就要求上层及时将UDP获取到的报文读取上去,如果一个报文在UDP没有被读取,那么此时UDP从底层获取上来的报文数据就会被迫丢弃。
一个报文从一台主机传输到另一台主机,在传输过程中会消耗主机资源和网络资源。如果UDP收到一个报文后仅仅因为上次收到的报文没有被上层读取,而被迫丢弃一个可能并没有错误的报文,这就是在浪费主机资源和网络资源。
因此UDP本身是会维护一个接收缓冲区的,当有新的UDP报文到来时就会把这个报文放到接收缓冲区当中,此时上层在读数据的时就直接从这个接收缓冲区当中进行读取就行了,而如果UDP接收缓冲区当中没有数据那上层在读取时就会被阻塞。因此UDP的接收缓冲区的作用就是,将接收到的报文暂时的保存起来,供上层读取。
UDP使用注意事项
需要注意的是,UDP协议报头当中的UDP最大长度是16位的,因此一个UDP报文的最大长度是64K(包含UDP报头的大小)。
然而64K在当今的互联网环境下,是一个非常小的数字。如果需要传输的数据超过64K,就需要在应用层进行手动分包,多次发送,并在接收端进行手动拼装。
基于UDP的应用层协议
- NFS:网络文件系统。
- TFTP:简单文件传输协议。
- DHCP:动态主机配置协议。
- BOOTP:启动协议(用于无盘设备启动)。
- DNS:域名解析协议。
当然,也包括你自己写UDP程序时自定义的应用层协议。