开门见山,本文就针对一个点,谈谈Spark中的宽依赖和窄依赖,这是Spark计算引擎划分Stage的根源所在,遇到宽依赖,则划分为多个stage,针对每个Stage,提交一个TaskSet:
上图:一张网上的图:
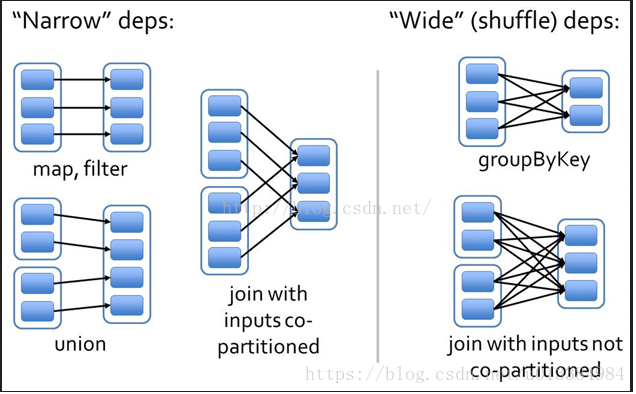
基于此图,分析下这里为什么前面的流程都是窄依赖,而后面的却是宽依赖:
我们仔细看看,map和filter算子中,对于父RDD来说,一个分区内的数据,有且仅有一个子RDD的分区来消费该数据。
同样,UNION算子也是同样的:
所以,我们判断窄依赖的依据就是:父类分区内的数据,会被子类RDD中的指定的唯一一个分区所消费:
这是很重要的:
面试的时候,面试官问到了一个问题,如果父类RDD有很多的分区,而子类RDD只有一个分区,我们可以使用repartition或者coalesce算子来实现该效果,请问,这种实现是宽依赖?还是窄依赖?
如果从网上流传的一种观点:子RDD一个partition内的数据依赖于父类RDD的所有分区,则为宽依赖,这种判断明显是错误的:
别笑,网上的确有这种说法,我差点栽了跟头,这种解释实质上是错误的,因为如果我们的reduceTask只有一个的时候,只有一个分区,这个分区内的数据,肯定依赖于所有的父类RDD:
毫无疑问,这是个窄依赖:
相对之下,什么是宽依赖呢?
宽依赖,指的是父类一个分区内的数据,会被子RDD内的多个分区消费,需要自行判断分区,来实现数据发送的效果:
总结一下:
窄依赖:父RDD中,每个分区内的数据,都只会被子RDD中特定的分区所消费,为窄依赖:
宽依赖:父RDD中,分区内的数据,会被子RDD内多个分区消费,则为宽依赖:
这里,还存在一个可能被挑刺的地方,比如说父类每个分区内都只有一个数据,毫无疑问,这些数据都会被唯一地指定到子类的某个分区内,这是窄依赖?还是宽依赖?
这时候,可以从另外一个角度来看问题:
每个分区内的数据,是否能够指定自己在子类RDD中的分区?
如果不能,那就是宽依赖:如果父RDD和子RDD分区数目一致,那基本就是窄依赖了:
总之,还是要把握住根本之处,就是父RDD中分区内的数据,是否在子类RDD中也完全处于一个分区,如果是,窄依赖,如果不是,宽依赖。