之前写过Spark的相关练习文档,但一直没有上传,今天把Spark部分的相关练习内容及思维导图给更新下。本篇仅涉及RDD的创建和宽依赖窄依赖。
练习1:RDD的创建
任务1: 通过数组、列表创建
// 1. 通过列表创建RDD
val list = sc.parallelize(List("ab","cd","ef"))
// 2. 通过数组创建RDD
val array = sc.parallelize(Array(1,2,3))
任务2: 通过文件创建
// 从windows本地加载数据,此时操作并未真正执行
val lines = sc.textFile("file:///F:/04Spark/dataset/hello.txt")
练习2:常用的RDD转换操作算子方法
任务1: 窄依赖操作(map、filter、flatMap等)
map方法
map十分容易理解,他是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的JavaRDD。
// 1. 创建原始RDD
val x = sc.parallelize(Array(1,2,3))
// 2. 对RDD的每个元素做操作 ----- 方式1
val mapRDD1 = x.map(ele => ele * 10)
// 2. 方式2
val mapRDD2 = x.map(_*10)
// 3. 查看x 与mapRDD
x.collect().mkString(",")
mapRDD1.collect().mkString(",")
mapRDD2.collect().mkString(",")
// 1. 创建原始RDD
val strRDD = sc.parallelize(Array("ab","cd","ef"))
// 2. 对每个元素增加一个属性
val tupleRDD = strRDD.map(ele => (ele,1))
// 3. 查看strRDD 与tupleRDD
strRDD.collect().mkString(",")
tupleRDD.collect().mkString(",")
filter方法
val intRDD = sc.parallelize(Array(1,2,3))
val filterRDD = intRDD.filter(ele => ele%2==0)
filterRDD.collect().mkString(",")
flatMap方法
flatMap与map一样,是将RDD中的元素依次的传入call方法,他比map多的功能是能在任何一个传入call方法的元素后面添加任意多元素,而能达到这一点,正是因为其进行传参是依次进行的。
val flatMapRDD = intRDD.flatMap(ele => Array(ele,ele*100,42))
intRDD.collect().mkString(",")
flatMap的特性决定了这个算子在对需要随时增加元素的时候十分好用,比如在对源RDD查漏补缺时。
任务2: 宽依赖操作(groupby、distinct、coalesce等)
groupby方法
// 1. 创建原始RDD
val namesRDD = sc.parallelize(Array("Jack","Alice","Card","Jackson"))
// 2. 按照首字母来进行分组
val groupRDD = namesRDD.groupBy(ele => ele.charAt(0))
groupRDD.collect().mkString(",")
distinct方法
val x = sc.parallelize(Array(1,2,3,3,4))
// 去掉重复元素
val y = x.distinct()
x.collect().mkString(",")
y.collect().mkString(",")
coalesce方法
coalesce方法默认是不触发shuffle的,而repartition方法一定会触发shuffle,他们都可以重新进行分区
// 将数据划分为3个分区
val x = sc.parallelize(Array(1,2,3,4,5),3)
// 调用coalesce方法,重新进行分区,减小分区数量使之变为2个分区
val y = x.coalesce(2)
x.glom().collect()
y.glom().collect()
reduceByKey和groupByKey
-
reduceByKey()对于每个key对应的多个value进行了merge操作,最重要的是它能够先在本地进行merge操作。本地的数据先进行merge然后再传输到不同节点再进行merge,最终得到最终结果。在本地进行merge的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
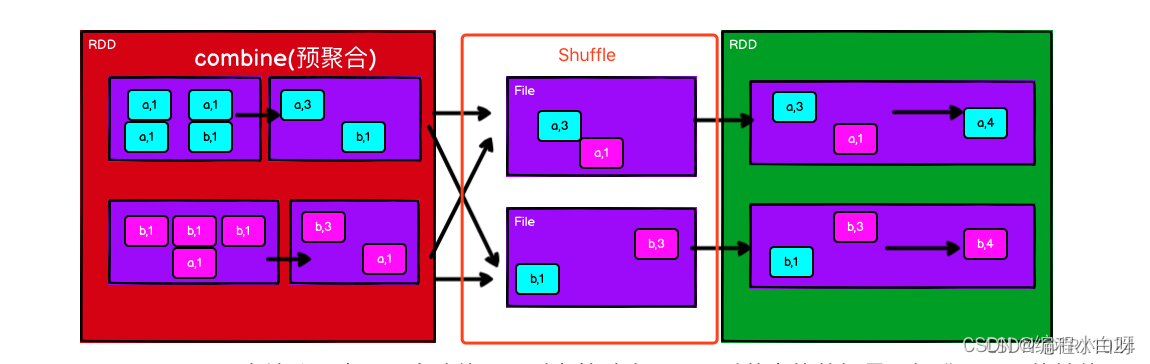
-
groupByKey()也是对每个key对应的多个value进行操作,但是只是汇总生成一个sequence,本身不能自定义函数。一开始并不进行本地的merge,全部数据传出,得到全部数据后才会进行聚合成一个sequence,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。 因此开销较大。
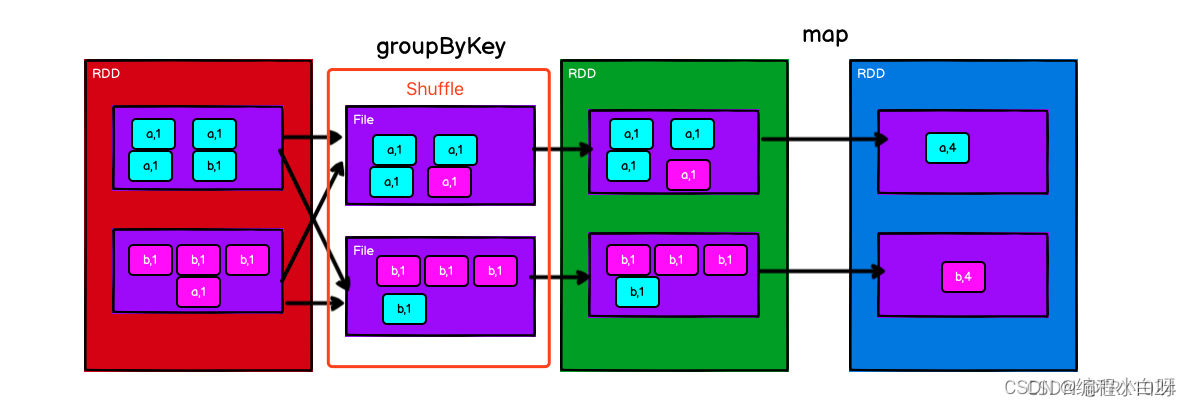
-
(key,value) 形式的数据,我们可以通过 ._1,._2 来访问键和值,用占位符表示就是 _.1,._2,这里前面的两个下划线的含义是不同的,前边下划线是占位符,后边的是访问方式。
val words = Array("one", "two", "two", "three", "three", "three")
// 1. 进行map,增加一个属性
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
// 2. groupByKey()后调用map遍历每个分组,然后通过t => (t._1,t._2.sum)对每个分组的值进行累加。
//因为groupByKey()操作是把具有相同类型的key收集到一起聚合成一个集合,集合中有个sum方法,对所有元素进行求和。
val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
补充
1. action算子
foreachPartition
foreachPartition方法是迭代器被传入了我们的方法(每个分区执行一次函数,我们获取迭代器后需要自行进行迭代处理)
// 1. 分区 2个分区
val rdd = sc.parallelize(1 to 6,2)
rdd.foreachPartition(x =>{
println("data")
println(x)
while(x.hasNext){
println(x.next())}
})
count、mean、min、max
val rdd1 = sc.parallelize(List('A','B','c'))
// 1. 统计计数
rdd1.count()
// 2. 求平均值
val rdd = sc.parallelize(List(1,2,3,4))
rdd.mean()
// 3. 求最大值
rdd.max()
// 4. 求最小值
rdd.min()
reduce
val rdd = sc.parallelize(List(1,2,3,4))
// 求和,将各个数累加
rdd.reduce(_+_)
转换算子
union 、intersection、cartesian、subtract
// 1.创建2个RDD
val rdd1=sc.parallelize(List('A','B'))
val rdd2=sc.parallelize(List('B','C'))
// 2. 取并集
rdd1.union(rdd2).collect().mkString(",")
// 3. 取交集
rdd1.intersection(rdd2).collect().mkString(",")
// 4. 笛卡尔积
rdd1.cartesian(rdd2).collect().mkString(",")
//5. 相减
rdd1.subtract(rdd2).collect().mkString(",")
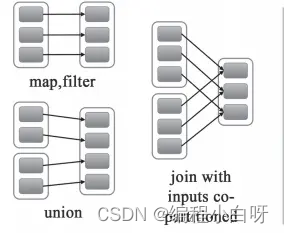
总结-宽依赖和窄依赖
-
宽依赖是串行,窄依赖是并行的
-
宽依赖:父RDD的分区被子RDD的多个分区使用。例如 groupByKey、reduceByKey、sortByKey等操作会产生宽依赖,会产生shuffle。
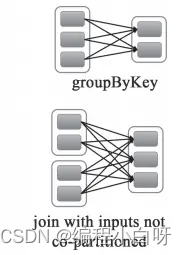
-
窄依赖:父RDD的每个分区都只被子RDD的一个分区使用 例如map、filter、union等操作会产生窄依赖